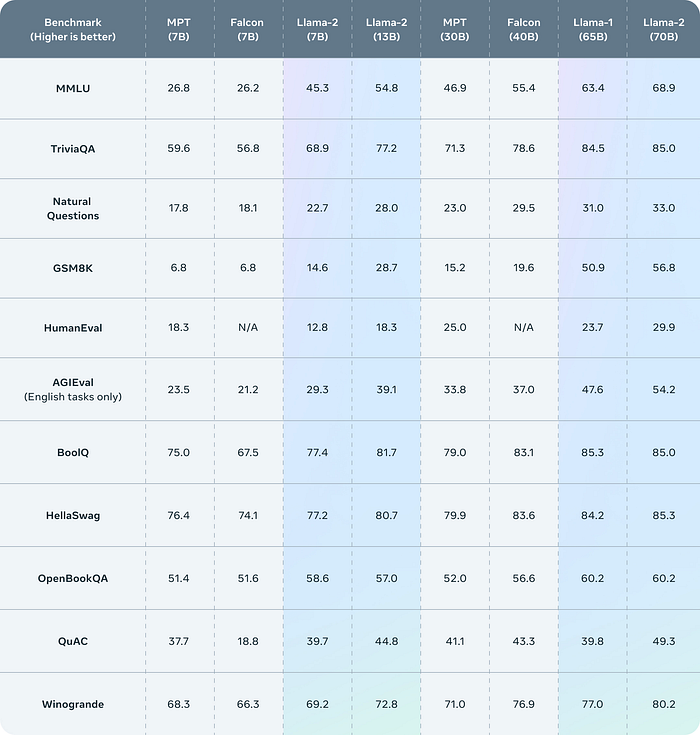
Llama 2是开源模型的最佳基准 在几乎所有的基准测试中,Llama2的7B和40B参数模型都超过了之前最先进的开源模型猎鹰。基于其他基准测试,它与GPT3.5相当,略低于GPT4,考虑到GPT4在技术上仍处于测试阶段,这令人难以置信。
你可以在这里试试Llama2 。
Step 1: 获得Llama2的许可证 截至2023年7月19日,Meta已经在注册流程后面设置了Llama2。首先,你需要从Meta请求访问 。然后,您可以从HuggingFace 请求访问,以便我们可以通过HuggingFace下载docker容器中的模型。
Step 2: 容器化Llama 2 为了将Llama 2部署到Google Cloud,我们需要将其封装在一个带有REST端点的Docker容器中。我们比较了这一步的几个不同选择,包括LocalAI 和Truss 。我们最终选择了Truss,因为它的灵活性和广泛的GPU支持。
你也可以使用RAGStack ,一个MIT许可的项目,来自动完成本教程中的其他步骤。它通过Terraform将Llama 2部署到GCP,还包括一个矢量数据库和API服务器,因此您可以上传Llama 2可以检索的文件。
容器化Llama2,开始创建一个Truss项目:
这将创建一个名为llama2-7b的目录,其中包含Truss需要的相关文件。我们需要配置项目,以便从Huggingface下载Llama2并使用它进行预测。将llama2-7b/model/model.py更新为以下代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 import torchfrom transformers import AutoTokenizer, AutoModelForCausalLM, pipelinefrom typing import Dict from huggingface_hub import loginimport osMODEL_NAME = "meta-llama/Llama-2-7b-chat-hf" DEFAULT_MAX_LENGTH = 128 class Model : def __init__ (self, data_dir: str , config: Dict , **kwargs ) -> None : self._data_dir = data_dir self._config = config self.device = "cuda" if torch.cuda.is_available() else "cpu" print ("THE DEVICE INFERENCE IS RUNNING ON IS: " , self.device) self.tokenizer = None self.pipeline = None secrets = kwargs.get("secrets" ) self.huggingface_api_token = os.environ.get("TRUSS_SECRET_huggingface_api_token" ) def load (self ): login(token=self.huggingface_api_token) self.tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME, use_auth_token=self.huggingface_api_token) model_8bit = AutoModelForCausalLM.from_pretrained( MODEL_NAME, device_map="auto" , load_in_8bit=True , trust_remote_code=True ) self.pipeline = pipeline( "text-generation" , model=model_8bit, tokenizer=self.tokenizer, torch_dtype=torch.bfloat16, trust_remote_code=True , device_map="auto" , ) def predict (self, request: Dict ) -> Dict : with torch.no_grad(): try : prompt = request.pop("prompt" ) data = self.pipeline( prompt, eos_token_id=self.tokenizer.eos_token_id, max_length=DEFAULT_MAX_LENGTH, **request )[0 ] return {"data" : data} except Exception as exc: return {"status" : "error" , "data" : None , "message" : str (exc)}
因为Huggingface上的LLama2访问是门接的,所以在检索模型时需要提供Huggingface APItoken。Truss有一个内置的秘密管理系统,这样我们就可以使用我们的API密钥,而不用在Docker容器中公开它。要添加我们的APItoken,请更新llama2-7b/config.yaml:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 apply_library_patches: true bundled_packages_dir: packages data_dir: data description: null environment_variables: {}examples_filename: examples.yaml external_package_dirs: []input_type: Any live_reload: false model_class_filename: model.py model_class_name: Model model_framework: custom model_metadata: {}model_module_dir: model model_name: Falcon-7B model_type: custom python_version: py39 requirements: - torch - peft - sentencepiece - accelerate - bitsandbytes - einops - scipy - git+https://github.com/huggingface/transformers.git resources: use_gpu: true cpu: "3" memory: 14Gi secrets: {}spec_version: '2.0' system_packages: []
现在我们可以在刚刚创建的文件夹外运行以下代码来创建docker镜像:
1 2 3 4 5 6 7 import trussfrom pathlib import Pathimport requeststr = truss.load("./llama2-7b" ) command = tr.docker_build_setup(build_dir=Path("./llama2-7b" )) print (command)
下面的脚本会给你一个命令来构建docker镜像:
1 docker build llama2-7b -t llama2-7b:latest
一旦你构建了镜像,你就可以将它部署到Docker Hub以供GKE使用:
1 2 docker tag llama2-7b $DOCKER_USERNAME/llama2-7b docker push $DOCKER_USERNAME/llama2-7b
Step 3: 使用Google Kubernetes Engine (GKE)部署Llama 2 现在我们有了Llama的docker映像,我们可以将它部署到GKE。我们需要打开Google Cloud仪表盘到Google Kubernetes Engine ,并创建一个名为gpu-cluster的新标准Kubernetes集群。将zone设置为us-central1-c。
在 default-pool > Nodes 选项卡中, 设置
Machine Configuration :将 General Purpose 改成 GPUGPU type: Nvidia TFNumber of GPUs: 1Enable GPU time sharingMax shared clients per GPU: 8Machine type: n1-standard-4Boot disk size: 50 GBEnable nodes on spot VMs
一旦创建了GKE集群,我们需要安装一些Nvidia驱动程序。在终端中运行
1 2 3 gcloud config set compute/zone us-central1-c gcloud container clusters get-credentials gpu-cluster kubectl apply -f <https://raw.githubusercontent.com/GoogleCloudPlatform/container-engine-accelerators/master/nvidia-driver-installer/cos/daemonset-preloaded.yaml>
安装了驱动程序之后,就可以部署到GKE了。创建一个yaml文件kubernetes_deployment.yaml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 apiVersion: apps/v1 kind: Deployment metadata: name: llama2-7b namespace: default spec: replicas: 1 selector: matchLabels: component: llama2-7b-layer template: metadata: labels: component: llama2-7b-layer spec: containers: - name: llama2-7b-container image: psychicapi/llama2-7b:latest ports: - containerPort: 8080 env: - name: TRUSS_SECRET_huggingface_api_token value: "$YOUR_HUGGINGFACE_API_TOKEN" resources: limits: nvidia.com/gpu: 1 --- apiVersion: v1 kind: Service metadata: name: llama2-7b-service namespace: default spec: type: LoadBalancer selector: component: llama2-7b-layer ports: - port: 8080 protocol: TCP targetPort: 8080
确保用你的apitoken替换$ YOUR_HUGGINGFACE_API_TOKEN 。这部分是必要的,因为Llama的通道是受限的。
然后运行:
1 kubectl create -f kubernetes_deployment.yaml
部署完成后,您可以通过调用获得llama2-7b-service的外部IP
Step 4: 测试已部署的模型 复制这个cURL并在终端上运行它,将$EXTERNAL_IP替换为您在上一步中获得的IP。
1 2 3 4 5 curl --location 'http://$EXTERNAL_IP/v1/models/model:predict' \\ --header 'Content-Type: application/json' \\ --data '{ "prompt": "Who was president of the united states of america in 1890?" }'
如果您得到响应,则意味着您的服务按预期工作!..
请记住,我们启用了未经身份验证的调用,因此任何知道您服务的IP或URL的人都可以向您托管的Llama 2模型发出请求。您可能希望在GCP中设置身份验证,以只允许您自己的服务调用与模型交互的端点,否则您的GPU账单可能会很快堆积起来..。
接下来的步骤-连接你的数据 Llama 2的自托管版本很有用。使该模型从有用变为关键任务的是将其连接到外部和内部数据源(例如web或公司的内部知识库)的能力。
我们可以通过一种称为RAG检索增强生成的技术来实现这一点。
RAG 代表检索增强生成 (Retrieval Augmented Generation),这种技术通过从其他系统检索信息并通过prompt将其插入LLM的上下文窗口来增强大型语言模型(LLM)的功能。这为大语言模型提供了训练数据之外的信息,这对于几乎每个企业级应用程序都是必要的。例子包括来自当前网页的数据,来自Confluence或Salesforce等SaaS应用程序的数据,以及来自销售合同和pdf等文档的数据。
RAG往往比微调(fine-tuning)模型更有效,因为:
**更便宜: **微调(fine-tuning)模型是昂贵的,因为必须调整模型参数本身的权重。RAG仅仅是一系列向量相似度查询、SQL查询和API调用,花费很少。
更快: 微调(fine-tuning)每次需要几个小时,有时几天取决于模型的大小。使用RAG,对知识库的更改会立即反映在模型响应中,因为它可以及时地直接从记录系统中检索。更可靠: RAG允许您跟踪元数据上检索的文件,包括每个文件来自哪里的信息,使其更容易检查幻觉。另一方面,微调是一个黑盒子。
Llama2本身就像一个新员工 ,它有很好的一般知识和推理能力,但缺乏任何业务经验,不了解文本之外的各种背景信息,说的夸张一点就像是你不了解公司的基因、文化和现状,对很多事务的判断也许是正确的,但并不适用。
Llama2组合RAG就像一个经验丰富的员工 ,它了解你的业务是如何运作的,可以提供具体情况下的帮助,从客户反馈分析到财务规划和预测。
大家可以使用开源的RAGstack库 来设置RAG堆栈。
配置本地的gcloud客户端 我们需要首先从GCP控制台 获得我们的项目ID,并登录到gcloud客户端。
然后在终端运行以下命令,将$PROJECT_ID替换为您的项目ID。
1 2 gcloud auth login gcloud config set project $PROJECT_ID
现在我们有两种选择来部署每个服务——我们可以使用RAGstack,或者我们可以手动部署每个服务。
使用RAGstack进行部署 RAGstack 是一个开源工具,它使用Terraform和Truss来自动部署LLM (Falcon或Llama 2)和向量数据库。它还包括一个API服务和轻量级UI,以便于接受用户查询和检索上下文。
RAGstack还允许我们在本地运行每个服务,所以我们可以在部署前测试应用程序!
在本地开发 要在本地运行RAGstack,运行:
这将设置本地开发环境,并安装所有必要的python和nodejs依赖项。更改server 和ragstack-ui 下的文件将自动反映。
发布 要将RAGstack部署到GCP,运行:
如果你没有安装Terraform,你必须先按照[这些说明]安装它(https://developer.hashicorp.com/terraform/tutorials/aws-get-started/install-cli)。在Mac上,只有两个命令 :
1 2 brew tap hashicorp/tap brew install hashicorp/tap/terraform
但是,如果您仍然喜欢自己设置,请继续阅读!
手动部署 Step 1: 将Llama2号部署到GCP
Step 2: 部署向量数据库 向量数据库是最常用的存储检索上下文的方法,因为它们测量相似性的方式很适合用自然语言进行查询。
一些最流行的向量数据库是:
在本文中,我们使用Qdrant,因为它有一个方便的docker镜像,我们可以拉取和部署。
在终端中运行:
1 gcloud run deploy qdrant --image qdrant/qdrant:v1.3.0 --region $REGION --platform managed --set-env-vars QDRANT__SERVICE__HTTP_PORT=8080
将$REGION替换为要部署到的REGION 。我们通常部署到us-west1,但您应该部署到离您或您的用户较近的数据中心。
Step 3: 上传文档到向量数据库 我们需要一些方法来收集用户的文档。最简单的方法是从命令行读取文件路径。RAGstack库 有一个简单的UI来处理文件上传和解析。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 def read_document () -> str : while True : try : file_path = input ("Enter the file path: " ) with open (file_path, 'r' ) as file: data = file.read() return Document( content=data, title="Doc Title" , id =str (uuid.uuid4()), uri=file_path ) except Exception as e: print (f"An error occurred: {e} " ) input ("Press enter to continue..." )
我们还需要一个函数将这些文档转换为Embeddings并将它们插入到Qdrant中。
源码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 async def upsert (self, documents: List [Document] ) -> bool : langchain_docs = [ Document( page_content=doc.content, metadata={"title" : doc.title, "id" : doc.id , "source" : doc.uri} ) for doc in documents ] text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000 , chunk_overlap=100 ) split_docs = text_splitter.split_documents(langchain_docs) points = [] seen_docs = {} for doc in split_docs: doc_id = None if doc.metadata["id" ] not in seen_docs: doc_id = doc.metadata["id" ] seen_docs[doc.metadata["id" ]] = 1 chunk_id = uuid.uuid5(uuid.NAMESPACE_DNS, f"{doc_id} _1" ) else : doc_id = doc.metadata["id" ] seen_docs[doc.metadata["id" ]] += 1 chunk_id = uuid.uuid5(uuid.NAMESPACE_DNS, f"{doc_id} _{seen_docs[doc.metadata['id' ]]} " ) vector = embeddings_model.encode([doc.page_content])[0 ] vector = vector.tolist() points.append(PointStruct( id =str (chunk_id), payload={ "metadata" : { "title" : doc.metadata["title" ], "source" : doc.metadata["source" ], "chunk_id" : chunk_id, "doc_id" : doc_id, }, "content" : doc.page_content }, vector=vector )) self.client.upsert( collection_name=self.collection_name, points=points ) return True
Step 4: 把点连起来 为了端到端运行我们的RAG模型,我们需要在python中设置一些额外的glue功能。
接受用户查询并将其转换为Embedding,然后根据Embedding在Qdrant中运行相似度搜索
源码
1 2 3 4 5 6 7 8 9 10 async def query (self, query: str ) -> List [PsychicDocument]: query_vector = embeddings_model.encode([query])[0 ] query_vector = query_vector.tolist() results = self.client.search( collection_name=self.collection_name, query_vector=query_vector, limit=5 ) return results
使用模板和检索到的文档构造prompt,然后将prompt发送到托管的Llama 2模型
Source — 这是来自猎鹰7B模型的代码,但由于我们使用Truss来服务模型,因此与Llama2连接时代码将相同。
1 2 3 4 5 6 7 8 9 async def ask (self, documents: List [Document], question: str ) -> str : context_str = "" for doc in documents: context_str += f"{doc.title} : {doc.content} \\n\\n" prompt = ( "Context: \\n" "---------------------\\n" f"{context_str} " "\\n---------------------\\n" f"Given the above context and no other information, answer the question: {question} \\n" ) data = {"prompt" : prompt} res = requests.post(f"{base_url} :8080/v1/models/model:predict" , json=data) res_json = res.json() return res_json['data' ]['generated_text' ]
将所有这些放在一起的最简单的方法是使用FastAPI 或Flask 设置一个API服务器 ,它处理托管Llama 2实例,托管Qdrant实例和用户输入之间的所有通信和协调。
下面是一个使用FastAPI的例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 from fastapi import FastAPI, File, HTTPException, Depends, Body, UploadFile from fastapi.security import HTTPBearer from fastapi.middleware.cors import CORSMiddleware from models.api import ( AskQuestionRequest, AskQuestionResponse, )app = FastAPI() app.add_middleware( CORSMiddleware, allow_origins=["*"], allow_credentials=True, allow_methods=["*"], allow_headers=["*"], )bearer_scheme = HTTPBearer()@app.post( "/ask-question", response_model=AskQuestionResponse, ) async def ask_question( request: AskQuestionRequest = Body(...), ): try: question = request.question # vector_store and llm should be classes that provide an interface into your hosted Qdrant and Llama2 instances documents = await vector_store.query(question) answer = await llm.ask(documents, question) return AskQuestionResponse(answer=answer) except Exception as e: print(e) raise HTTPException(status_code=500, detail=str(e))
您可以在RAGstack 库中看到这些部分是如何组合在一起的-应用程序的入口点是从 server/main.py 运行的FastAPI服务器。
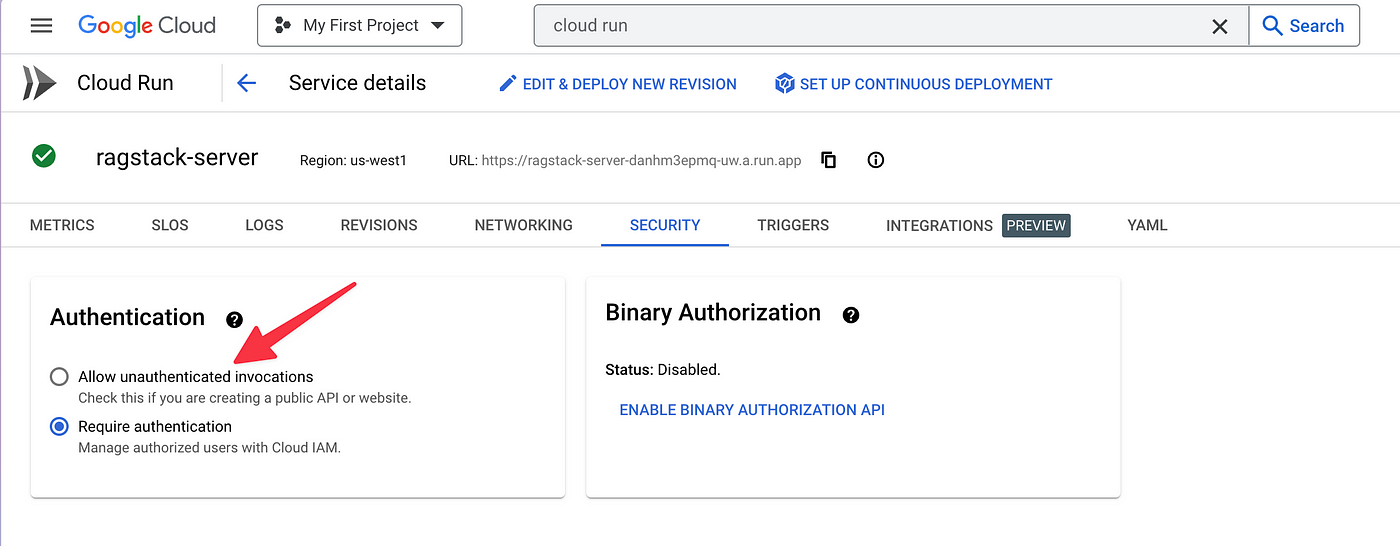
禁用验证
In order to make testing our new RAG model easier, we can Allow unauthenticated invocations for each of our GCP services (hosted Llama 2 model, the hosted Qdrant image, any API server you have set up).
Make sure you set up authentication after your testing is complete or you might run into some surprises on your next billing cycle. GPUs ain’t cheap!
测试您的RAG模型 有趣的部分来了!我们现在有了一个Llama 7B服务、一个Qdrant实例和一个API服务,将所有这些部分连接在一起,所有这些都部署在GCP上。
使用这个简单的cURL查询您的新RAG模型。
1 2 3 4 5 curl --location '$API_SERVICE_URL/ask-question' \\ --header 'Content-Type: application/json' \\ --data '{ "question": "Who was president of the united states of america in 1890?" }'
Replace $API_SERVICE_URL with the URL to the service that is responsible for connecting the vector store and Llama 2.
得到答案后,就可以在自己的基础设施上有效地部署ChatGPT,并将其连接到自己的文档。您可以提出问题并获得答案,而无需向外部第三方进行单个API调用!
原文:How to connect Llama 2 to your own data, privately