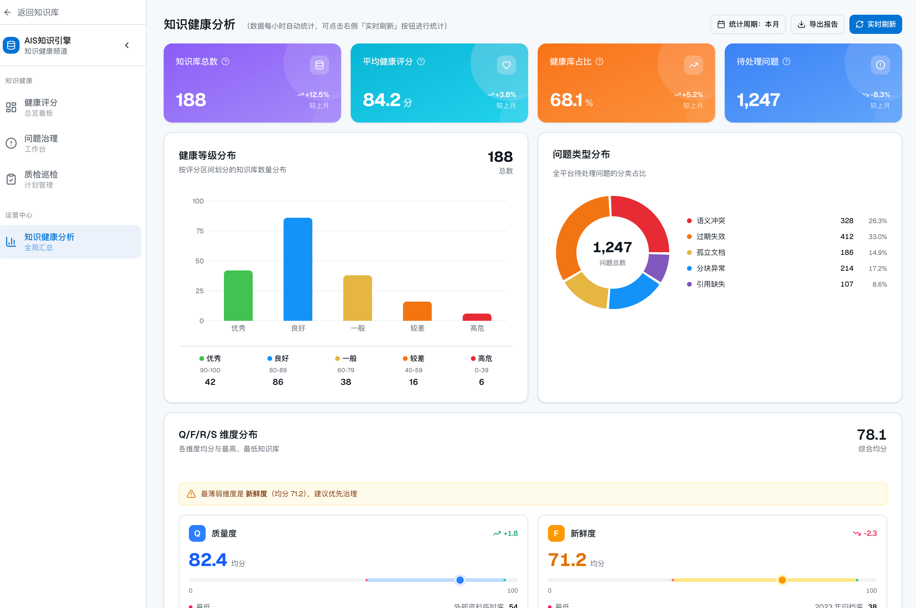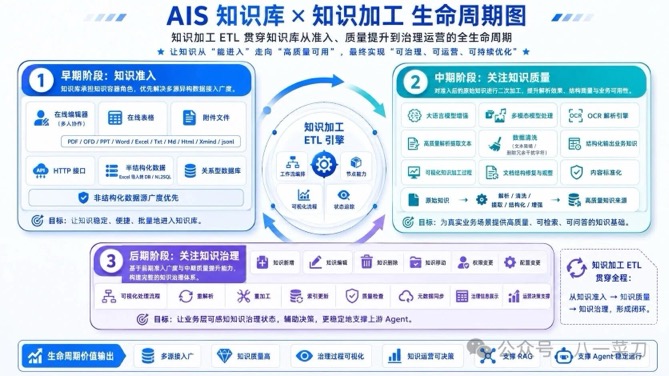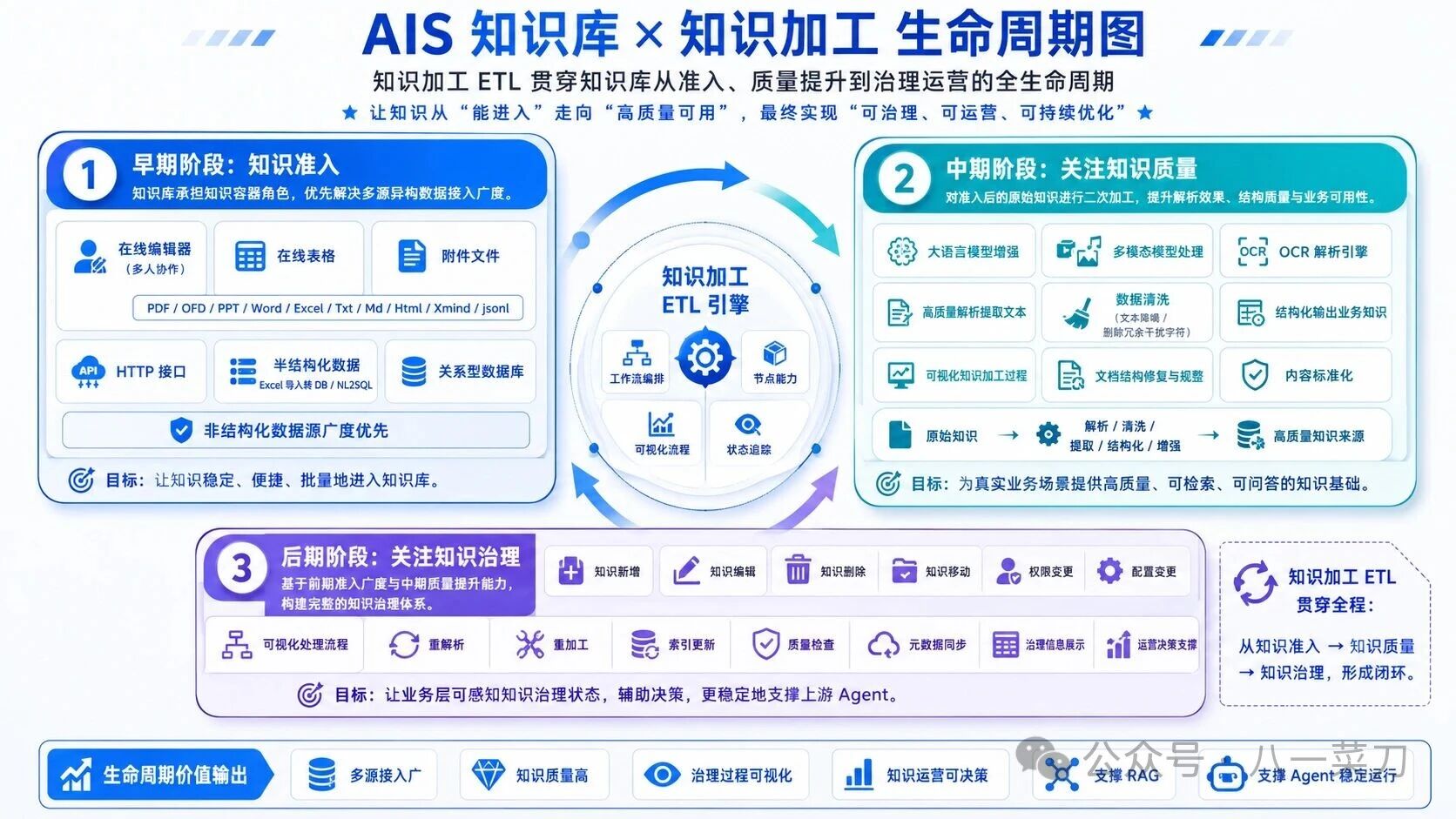
未来,当企业内部出现大量 Agent 时,企业之间的差距也会迅速拉开。因为除了一定程度上可以共享的大模型能力,真正难以复制的,是由企业级知识引擎长期沉淀、治理并持续更新的企业上下文。
最近一段时间,我的大部分精力都放在一个企业级智能知识库项目的需求分析和总体设计上。
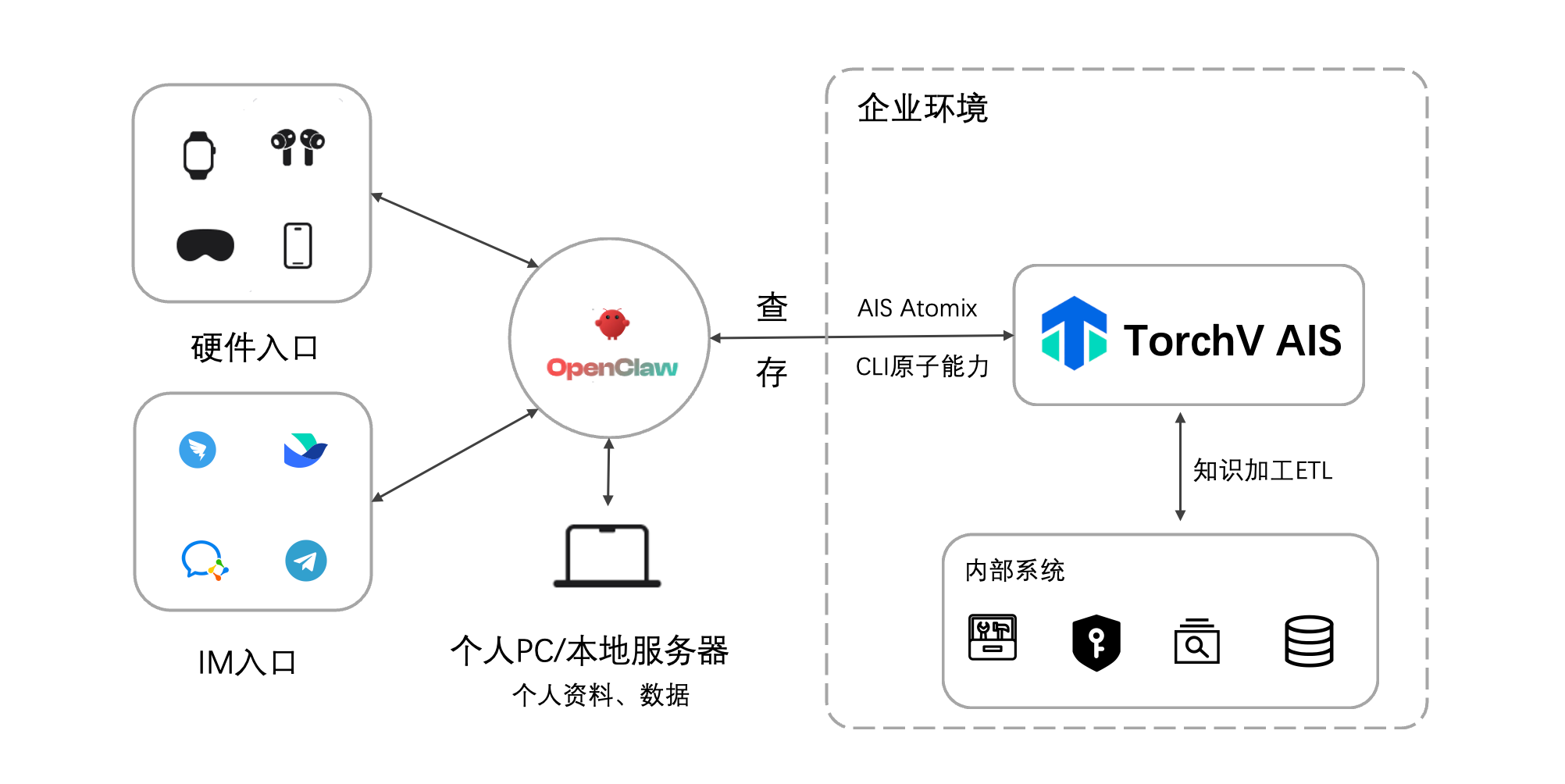
明总刚刚写了一篇《AIS 交付实践中的架构演进与思考》更多从技术和交付角度,讨论不同客户基础设施带来的适配问题,以及 AIS 如何通过存储适配、任务持久化和部署组合降低私有化交付的复杂度。其中有一个观点我很认同:产品架构不是关起门来设计出来的,交付过程中真实遇到的问题,本身就是架构演进的重要输入。
而我在这次项目中做的事情更偏向需求、产品和总体设计。每天面对的不是“某个功能怎么实现”,而是另一组问题:
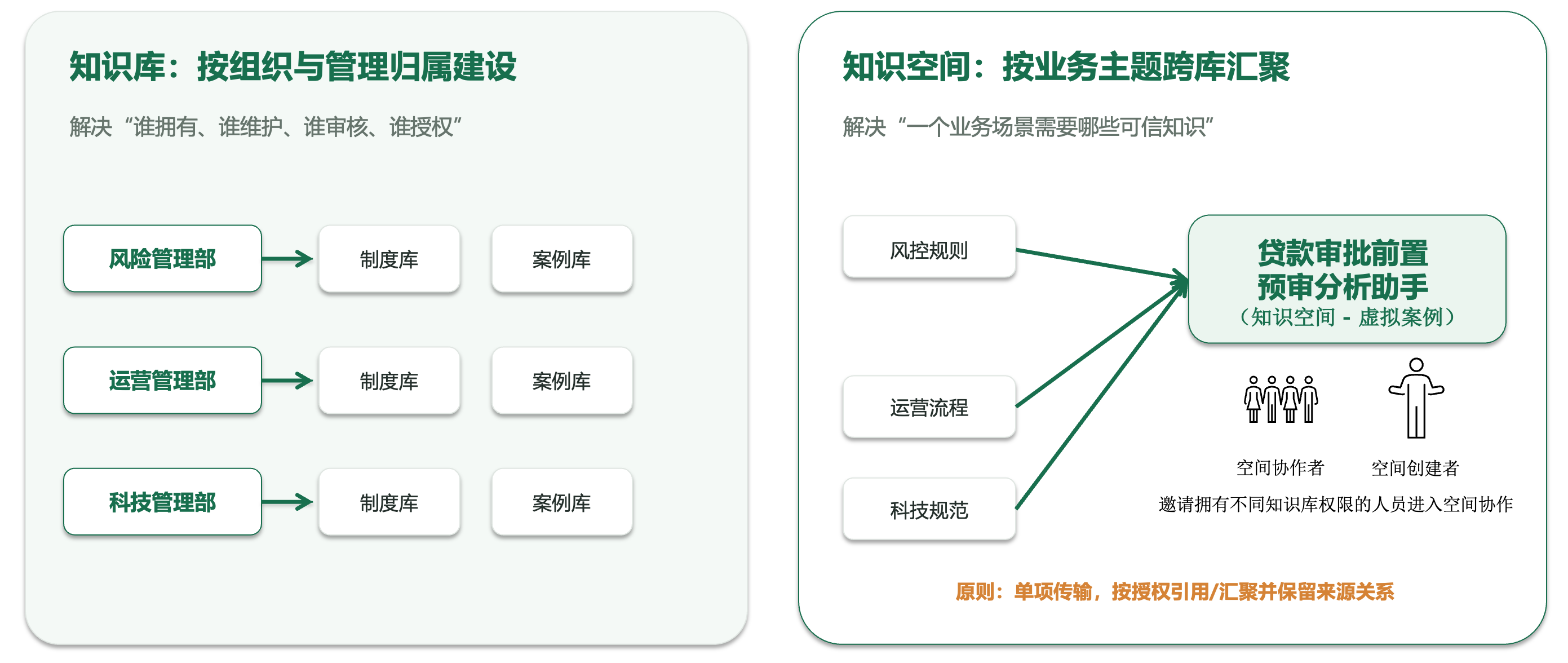
客户为什么要建设企业级知识库?它和原来的文档管理系统有什么区别?知识由谁维护?制度更新后旧版本怎么办?跨部门 Agent 从哪里获得知识?答案不准确时,问题究竟出在模型、检索,还是知识本身?
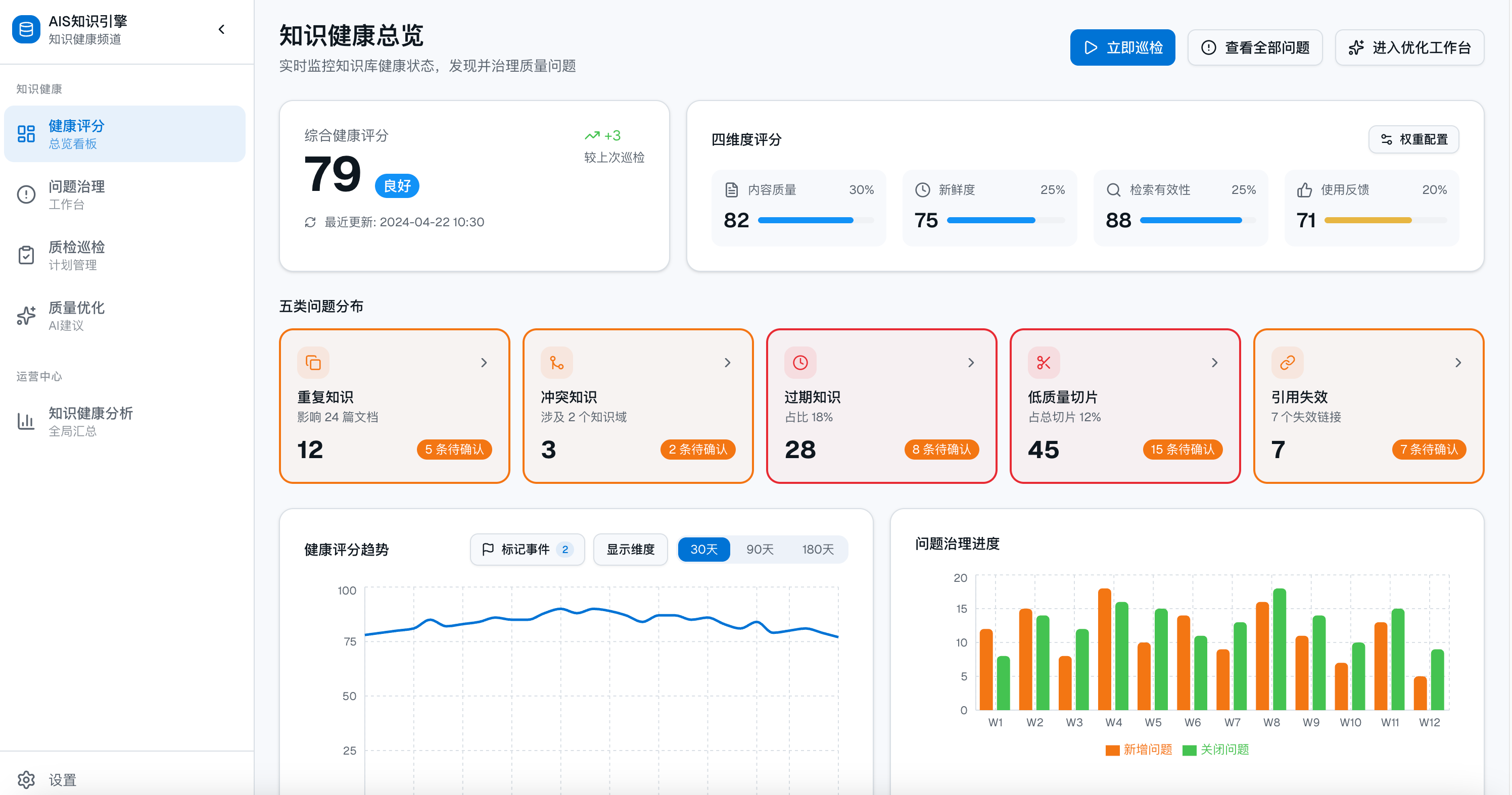
这些问题看起来不像算法问题,却往往决定了一个知识库能不能真正进入生产。