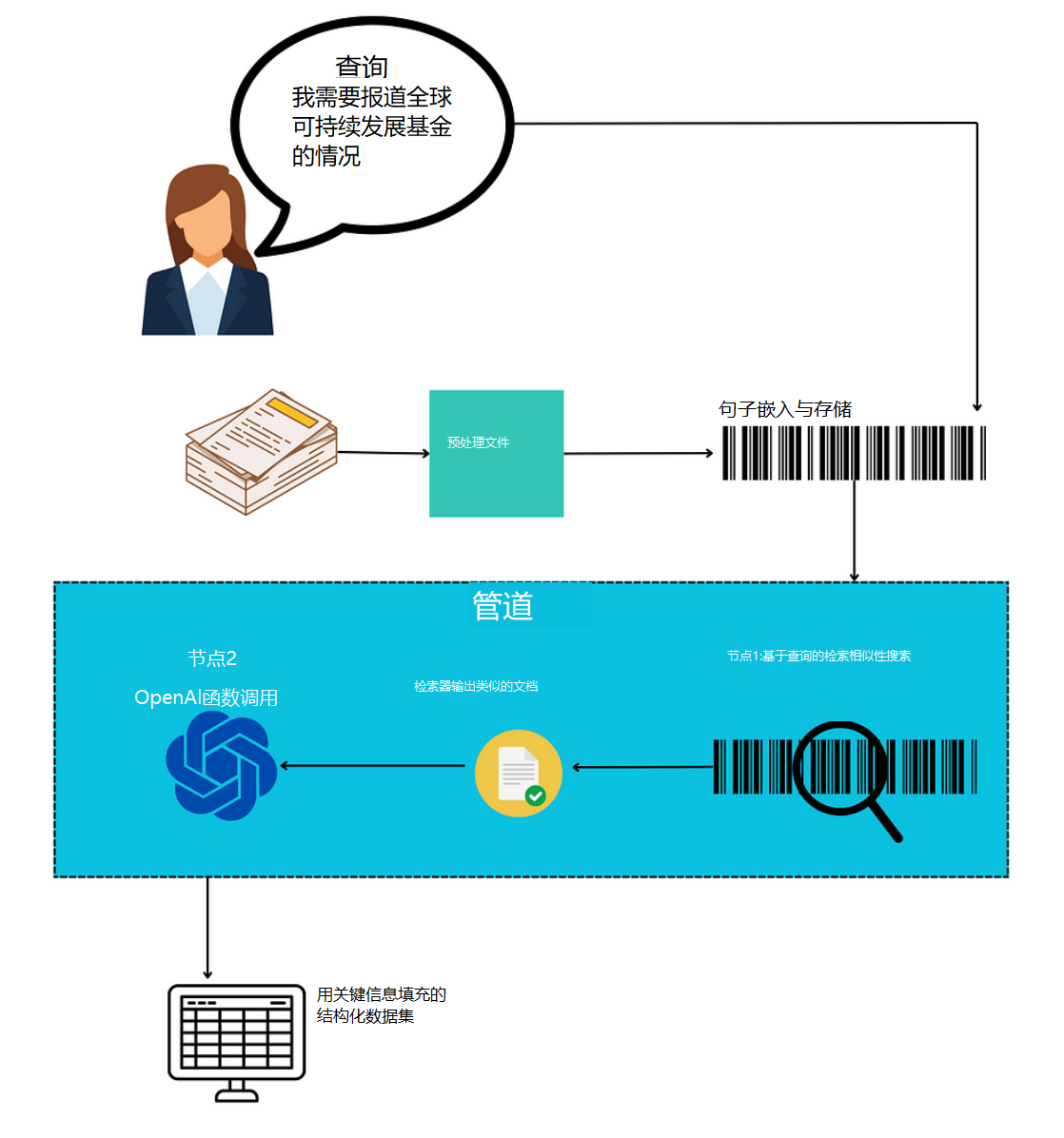
我预计许多读者将遇到类似的工作负载。因此,在本文中,我将介绍一种使用大型语言模型和检索管道自动化此类工作负载的简单方法。为了给您提供一个现实的用例,我用Morgan Stanley Funds UK的基金招股说明书来演示这一点,这是一份164页的公开文件,提供了他们一些基金的信息。这与风险经理可能会看到的招股说明书类型类似。我们将从招股说明书中提取并记录以下信息:
from haystack.nodes import PreProcessor from haystack.utils import convert_files_to_docs from haystack.document_stores import FAISSDocumentStore from sqlalchemy import create_engine from haystack.nodes import EmbeddingRetriever
# create FAISS and store defvector_stores(docs): engine = create_engine('sqlite:///C:/Users/johna/anaconda3/envs/longfunctioncall_env/long_functioncall/database/database.db') # change to your local directory try: # Attempt to drop the table engine.execute("DROP TABLE document") except Exception as e: # Catch any exceptions, likely due to the table not existing print(f"Exception occurred while trying to drop the table: {e}") document_store = FAISSDocumentStore(sql_url='sqlite:///C:/Users/johna/anaconda3/envs/longfunctioncall_env/long_functioncall/database/database.db', faiss_index_factory_str="Flat", embedding_dim=768) # change to your local directory document_store.write_documents(docs) return document_store
defrun(self, documents: List[str]): try: document_content_list = [doc.content for doc in documents] print("documents extracted") document_content = " ".join(document_content_list) except Exception as e: print("Error extracting content:", e) return functions = [ { "name": "update_dataframe", "description": "write the fund details to a dataframe", "parameters": { "type": "object", "properties": { "Product_reference_num": { "type": "string", "description": "The FCA product reference number which will be six or seven digits" }, "investment_objective": { "type": "string", "description": "You should return the investment objective of the fund. This is likely to be something like this: The Fund aims to grow your investment over t – t + delta t years" }, "investment_policy": { "type": "string", "description": "Return a summary of the fund's investment policy, no more than two sentences." }, "investment_strategy": { "type": "string", "description": "Return a summary of the fund's investment strategy, no more than two sentences." }, "ESG": { "type": "string", "description": "Return either True, or False. True if the fund is an ESG fund, False otherwise." }, "fund_name": { "type": "string", "description": "Return the name of the fund" }, }, }, "required": ["Product_reference_num", "investment_objective", "investment_policy", "investment_strategy", "ESG", "fund_name"] } ] openai.api_key = self.API_KEY response = openai.ChatCompletion.create( model="gpt-3.5-turbo-0613", messages=[{"role": "system", "content": document_content}], functions=functions, function_call="auto", # auto is default, but we'll be explicit )
defrun_batch(self, documents: List[str]): # You can either process multiple documents in a batch here or simply loop over the run method results = [] for document_content in document_content: result, _ = self.run(document_content) results.append(result) return results, "output_1"
一旦定义了自定义函数调用,将其与管道中的检索器结合在一起就很简单了。
1 2 3 4 5 6 7 8
from haystack import Pipeline from function_call import OpenAIFunctionCall
defcreate_pipeline(retriever, API_KEY): p = Pipeline() p.add_node(component=retriever, name="retriever", inputs=["Query"]) p.add_node(component=OpenAIFunctionCall(API_KEY), name="OpenAIFunctionCall", inputs=["retriever"]) return p