
前几天Falcon-180B大模型发布,在Hugging Face的所有LLM(大语言模型)里面排名第一,应该也是迄今为止参数量最大的开源预训练模型了。就性能来说,我看很多国外的专家都在给他背书,说仅次于GPT-4,和PaLM2相当,也就是说性能已经超过了大部分常用的ChatGPT3.5(GPT-3.5)了。开始我是不相信的,但是马上一想,这是TII(阿联酋阿布扎比技术创新研究所)发布的,我信了,因为他们是一群有“钞”能力的人。
很快,我们吕总就开始问我了,搞不搞。我一想到1800亿参数,那还不得上百张A100啊,不可能的,直接拒绝了。但是意识到可以自己武断了,于是再去好好查看了他们的网站,果然是我唐突了。官方说推理的话,400GB的显存就可以了,也就是6张A100-80GB就可以了(实际需要大概8张A100),大概也就是84万元(实际需要112万元)人民币(不考虑其他设备成本的话)。
好吧,这个“也就”用的有点飘,我感觉到了。
说实话180B的大模型,目前还没有太多中文benchmark出来,所以,我还是很想去尝试一下,看看效果的。
于是,我找到了一篇文章:《Falcon 180B: Can It Run on Your Computer?》,可能大多数人不一定能打开原文,那么可以看我下面的一些转述。
注:本文中180B中的B代表billion,也就是十亿,所以180B=1800亿。
2023年5月,阿布扎比技术创新研究所(TII)已经发布了两种预训练大语言模型:Falcon-7b和Falcon-40b,以及它们的聊天版本(Chat)。这两个模型表现出了非常好的性能,并曾经在OpenLLM排行榜上排名第一。
TII发布的第三个大模型就是Falcon-180B,一个1800亿个参数模型。它比Llama2-70b多2.5x参数,比Falcon-40b多4.5x参数。
关于Falcon-180B的一些基本情况(1)
- 预训练3.5万亿tokens
(2) - 使用Apache 2.0 license分发
- 容量大小为360GB
- 在OpenLLM排行榜
(3)上排名第一(截至2023年9月11日)
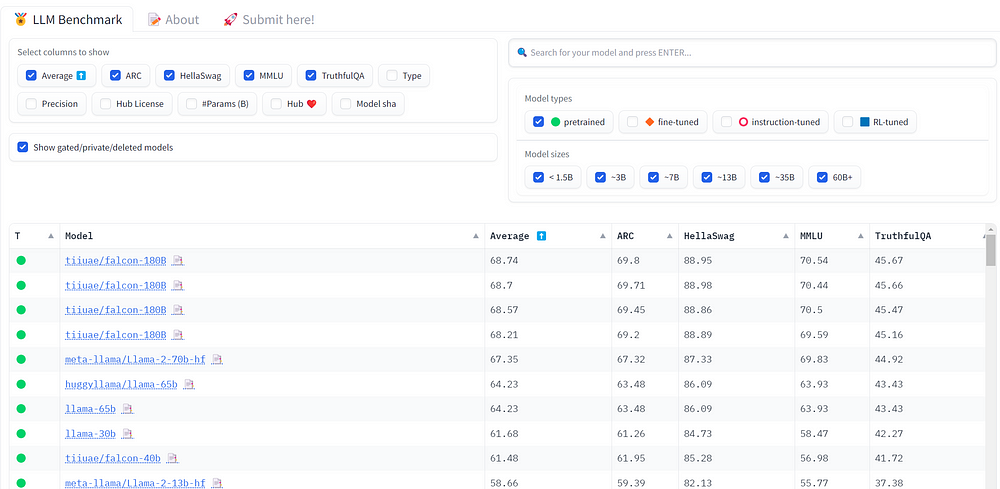
还有一个聊天(Chat)版本。这些模型可以在Hugging Face中心找到:
Falcon-180B是完全免费和最先进的。但它也是一个巨大的模型。
那么,它能在你的电脑上运行吗?
除非你的计算机已经准备好进行非常密集的计算,否则它无法开箱即用地运行Falcon180B。您将需要升级您的计算机并使用该模型的量化版本。
接下来,我们来看看如何在消费类硬件上运行Falcon-180B。我们将看到,在家用计算机上运行一个1800亿个参数的模型是可行的。我还讨论了几种有助于减少硬件需求的技术。
在电脑上加载Falcon180B所需的条件
您需要知道的第一件事是,Falcon180B有1800亿个参数,存储形式为bfloat16。一个bfloat16参数在内存中占2个字节。
当你加载一个模型时,标准Pytorch管道是这样工作的:
- 创建一个空模型:180B个参数* 2字节= 360 GB
- 在内存中加载其权重:180B个参数* 2字节= 360 GB
- 在步骤1创建的空模型中加载步骤2加载的权重
- 将步骤3得到的模型移动到设备上进行推理,例如GPU
步骤1和步骤2消耗内存。总的来说,您需要720 GB的可用内存。这可以是CPU RAM,但为了快速推理,您可能希望使用GPU,例如,9块A100(80GB)VRAM刚好是720GB,但实际上最好是12块A100。
无论是CPU RAM还是VRAM,这都是很大的内存。幸运的是,目前其实有一些方法可以“曲线”完成。
在HuggingFace,Falcon-180B使用安全防护器格式(safetensors format)分发。与标准Pytorch格式相比,这种格式有几个优点。它(几乎)没有复制(注:不需要有一个巨大或等量内存区域来做中间缓存),所以模型直接加载到第1步创建的空模型中。它节省了很多内存。
关于safetensors
safetensors 节省内存,而且它也使模型更安全运行,因为没有任意代码可以存储在这种格式。Safetensors模型的加载速度也快得多。当您从Hugging Face下载模型时,请使用此格式而不是“.bin”格式,以便更快、更安全、更节省内存。
尽管看起来我们跳过了第2步,但仍然会有一些内存开销。TII在Hugging Face的模型介绍上写着400GB的内存可以工作。这仍然很大,但比使用标准Pytorch格式少了220gb。
我们需要一个400 GB的设备,例如,5个A100(80G)的GPU VRAM,但这个结果离“消费级”家用电脑配置还很远。
在多个存储设备上分布式Falcon180B
你可能没有一个400 GB的内存设备,但如果你把以下所有设备的内存组合起来,你的电脑可能有超过400 GB的内存:
- GPU VRAM:如果你有NVIDIA RTX 3090或4090,那已经是24GB了。
- CPU RAM:大多数现代计算机至少有12GB的CPU内存,CPU的扩展也非常便宜。
- 硬盘(或SSD):SSD一般都可以有几个TB存储空间,而且是可以用SWAP做虚拟内存的。请注意,如果您计划使用SSD(固态硬盘)运行LLM,那么它将比原来的机械硬盘驱动器速度快得多,但是仅仅是高铁比汽车快的意思,和飞机、火箭差距依然很大。
为了利用可用的设备,我们可以拆分Falcon-180B,以便它按照以下优先顺序使用设备的最大可用内存:GPU, CPU RAM和SSD。
这很容易通过Accelerate上的device_map架构来实现。
Device_map将模型的整个层放在您拥有的不同设备上。
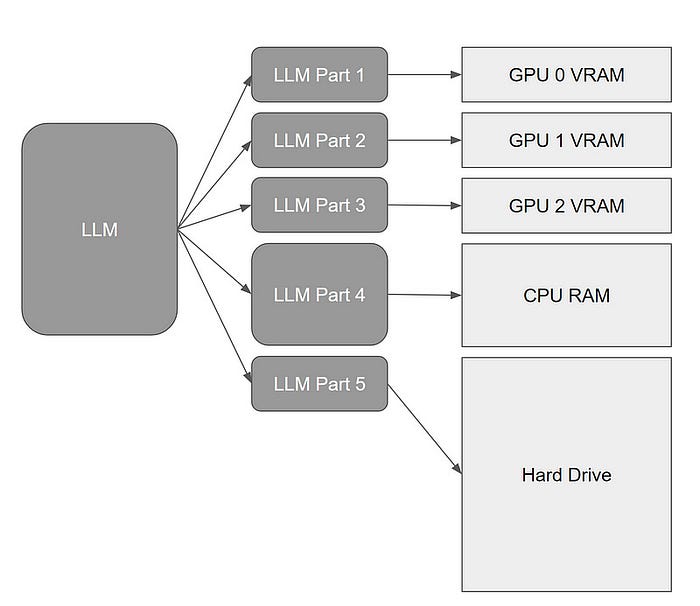
如果您想查看device_map使用的一些示例,请参考这篇文章。
Device_map对于解决CUDA内存不足问题来说确实是一种很好的方法,但如果你打算在消费级硬件上使用Falcon180B,那还远远不够理想。即使是拥有24 GB VRAM的GPU(比如RTX 4090)和32 GB CPU RAM的高端配置,它也依然还需要动用几百GB的硬盘空间。
这里有两个原因:
- 硬盘驱动器/SSD总体来说比GPU VRAM、CPU RAM慢得多。从硬盘装载和运行Falcon180B需要很长时间。
- 消费类硬盘和固态硬盘不是为这种密集计算使用设计和测试的。如果模型的许多部分被装载到硬盘驱动器上,系统将不得不在推理期间多次访问和读取模型的大量分割部分。这是长时间的大量读取操作。如果您连续数天进行推理,例如生成一些合成数据集,这可能会损坏您的硬盘,或者至少会显著降低其预期寿命。
为了避免过度使用硬盘,我们最好的方式就是去除硬盘方案,那么剩下来的解决方案实在不多了:
- 增加一个GPU:大多数高端主板可以容纳两个RTX 3090/4090。它会给你48 GB的VRAM。
- 扩展CPU RAM:大多数主板有4个插槽可用于CPU RAM套件。4x128GB CPU内存的套件有出售,但不容易找到,而且仍然很贵。 注意:您的操作系统可以支持的CPU RAM总量也有限制。Windows 10是2tb。如果你使用的是一个老版操作系统,你应该在购买更多的内存之前看看它的文档
- 量化版Falcon180B和扩展CPU RAM。
Falcon180B的量化版是减少内存消耗的最佳方案之一。
使用量化版Falcon180B减少RAM尺寸
现在的常见做法是将非常大的语言模型量化到较低的精度。GPTQ(4)和bitsandbytes nf4(5)是将LLM量化到4位精度的两种常用方法。
Falcon180B在使用bfloat16的情况下,我们看到它的尺寸是360 GB。
一旦量化到NF4精度,它只需要90GB(1800亿个参数* 0.5字节)。我们可以用100GB内存(90GB +一些内存开销)加载NF4的Falcon-180B。
如果你有24 GB的VRAM,你“只”需要75 GB的CPU RAM。这仍然是很多,但比加载原始模型便宜得多,并且在推理期间不会需要和硬盘上的模型层做交换。注意:您仍然需要100 GB的可用硬盘空间来存储模型
你甚至不需要GPU。使用128 GB的CPU RAM,您可以仅使用CPU进行推理。
量化本身是非常昂贵的。值得庆幸的是,我们已经可以在网上找到量化的版本。TheBloke:https://huggingface.co/TheBloke 发布了使用GPTQ制作的4位版本:
4-bit Falcon180B:https://huggingface.co/TheBloke/Falcon-180B-GPTQ)
4-bit Faclon 180B Chat:https://huggingface.co/TheBloke/Falcon-180B-Chat-GPTQ)
注:也有3位模型可作为模型的“分支”。按照4位型号卡的说明来获取它们
虽然模型的精度降低了,但根据Hugging Face的实验,模型的性能仍然相似(这一点太棒了!!!)。
GPTQ模型的推理速度很快,您可以使用LoRA适配器对它们进行微调,可以在这里查看如何微调使用GPTQ量化的Llama 2(6)。
虽然可以对GPTQ模型进行微调,但我不推荐这样做。使用QLoRA进行微调具有类似的内存消耗,但由于使用nf4进行了更好的量化,因此产生了更好的模型,如QLoRA论文(7)所示。
最后
总而言之,您需要量化版本(4-bit Falcon180B)和100GB内存才能在高配置的家用计算机上运行Falcon-180B。
对于快速推理或微调,你需要使用到GPU。RTX 4090(或RTX 3090 24GB,更实惠,但速度更慢)将足以加载量化模型的1/4。如果你的电脑机箱有足够的空间,你甚至可以放两张RTX卡。
如果你想在一个只有CPU的配置上运行Falcon-180b,也就是说,没有任何GPU,那你只把放弃微调的想法,它会慢到你怀疑人生,嗯,推理也同样会很慢。如果要在纯CPU的机器上运行,那llama.cpp(C++重写的llama)是个不错的选择。我们只能期待Falcon180B也有这样的版本,那在存内存的环境下运行Falcon180B才有可能。
我目前家里电脑的配置是RTX 4090(24GB) + 32GB内存,如果再买一块64GB的内存,好像就可以跑起来了哈哈。64GB的内存大概1400元,虽然有些舍不得,但感觉有点心动。
引用:
1.Falcon-180B模型介绍:https://huggingface.co/tiiuae/falcon-180B
2.RefinedWeb:https://huggingface.co/datasets/tiiuae/falcon-refinedweb
3.OpenLLM排行榜:https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
4.GPTQ:https://arxiv.org/abs/2210.17323
5.bitsandbytes nf4:https://arxiv.org/abs/2305.14314
6.微调使用GPTQ量化的Llama 2:https://kaitchup.substack.com/p/quantize-and-fine-tune-llms-with?source=post_page-----c3f3fb1611a9--------------------------------
7.QLoRA论文:https://arxiv.org/abs/2305.14314

