在构建检索增强生成(RAG)管道时,一个关键组件是Retriver。我们有各种各样的Embedding模型可供选择,包括OpenAI、CohereAI和开源的Sentence-Transformers。此外,CohereAI和Sentence-Transformers也提供了一些重新排序器。
但是有了这些选项,我们如何确定最佳组合以获得一流的检索性能呢?我们如何知道哪种Embedding模型最适合我们的数据?或者哪个重新排名对我们的结果提升最大?
在这篇博文中,我们将使用LlamaIndex的检索评估(Retrieval Evaluation)模块来快速确定Embedding和重新排名模型的最佳组合。让我们开始吧!
让我们首先从理解检索评估(Retrieval Evaluation)中可用的度量标准开始。
理解检索评价中的度量标准
为了衡量我们的检索系统的有效性,我们主要依赖于两个被广泛接受的指标:命中率和**平均倒数排名(MRR)**。让我们深入研究这些指标,了解它们的重要性以及它们是如何运作的。
命中率:
Hit rate计算在前k个检索文档中找到正确答案的查询比例。简单来说,它是关于我们的系统在前几次猜测中正确的频率。
平均倒数排名(MRR):
对于每个查询,MRR通过查看排名最高的相关文档的排名来评估系统的准确性。具体来说,它是所有查询中这些秩的倒数的平均值。因此,如果第一个相关文档是顶部结果,则倒数排名为1;如果是第二个,倒数是1/2,以此类推。
现在我们已经确定了范围并熟悉了参数,是时候深入实验了。想要亲身体验,你也可以使用我们的谷歌Colab笔记本
设置环境
1 | !pip install llama-index sentence-transformers cohere anthropic voyageai protobuf pypdf |
设置各种key
1 | openai_api_key = 'YOUR OPENAI API KEY' |
下载数据
本次实验我们将使用Llama2论文吧。
1 | !wget --user-agent "Mozilla" "https://arxiv.org/pdf/2307.09288.pdf" -O "llama2.pdf" |
加载数据
让我们加载数据。我们将使用从第1页到第36页进行实验,不包括目录、参考文献和附录。
然后将该数据解析为节点,节点表示我们想要检索的数据块。我们确实使用chunk_size为512。
1 | documents = SimpleDirectoryReader(input_files=["llama2.pdf"]).load_data() |
生成问题-上下文对:
为了评估的目的,我们创建了一个问题-上下文对的数据集。这个数据集可以被看作是我们数据中的一组问题及其相应的上下文。为了消除评估Embedding(OpenAI/ CohereAI)和重新排序(CohereAI)的偏见,我们使用Anthropic LLM来生成问题-上下文对。
让我们初始化一个prompt模板来生成问题-上下文对。
1 | # Prompt to generate questions |
过滤句子的功能,比如— Here are 2 questions based on provided context
1 | # function to clean the dataset |
自定义检索:
为了识别最优的检索器,我们采用了Embedding模型和重新排序器的组合。首先,我们建立一个基本的VectorIndexRetriever。检索节点后,我们引入一个重新排序器来进一步优化结果。值得注意的是,在这个特殊的实验中,我们将similarity_top_k设置为10,并使用reranker选择top5。但是,您可以根据具体实验的需要随意调整此参数。我们在这里用OpenAIEmbedding显示代码,请参阅笔记本获取其他Embeddings的代码。
1 | embed_model = OpenAIEmbedding() |
评估
为了评估我们的检索器,我们计算了平均倒数排名(MRR)和命中率指标:
1 | retriever_evaluator = RetrieverEvaluator.from_metric_names( |
结果:
我们对各种Embedding模型和重新排序器进行了测试。以下是我们考虑的模型:
向量模型:
Rerank模型:
值得一提的是,这些结果为这个特定数据集和任务的性能提供了坚实的见解。但是,实际结果可能会根据数据特征、数据集大小和其他变量(如chunk_size、similarity_top_k等)而有所不同。
下表展示了基于命中率和平均倒数排名(MRR)指标的评估结果:
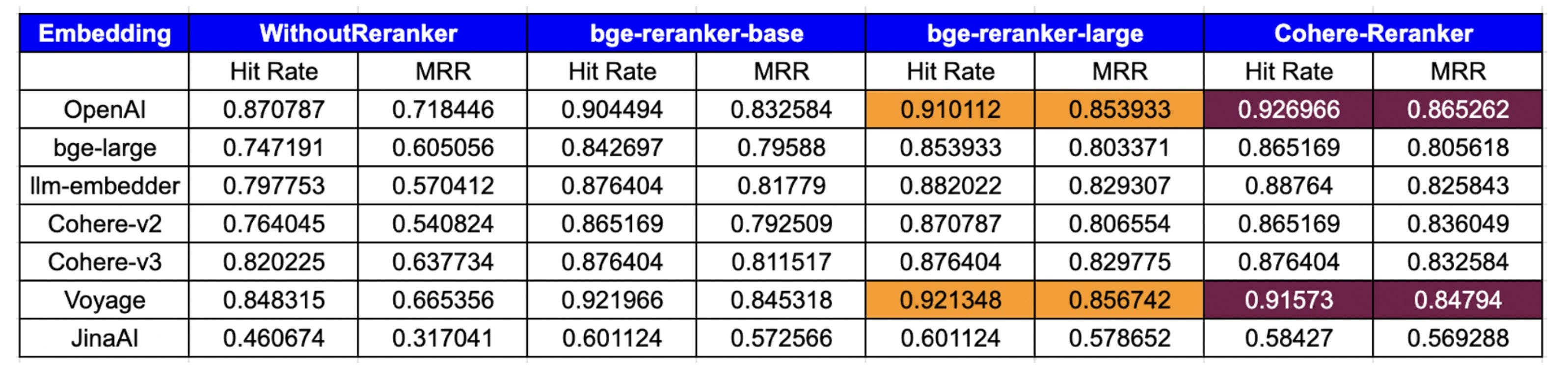
分析:
Embedding性能:
- OpenAI:表现出顶级的性能,特别是
cohererank(0.926966命中率,0.865262 MRR)和big-reranker-large(0.910112命中率,0.853993 MRR),表明与重排名工具的兼容性很强。 - big-large:在重新排序器上有了显著的改进,
CohereRerank的结果最好(0.865169命中率,0.805618 MRR)。 - llm-embedder:从重新排名中受益匪浅,特别是
CohereRerank(0.887640命中率,0.825843 MRR),它提供了实质性的性能提升。 - **coherhere **: coherhere最新的v3.0Embeddings优于v2.0,并且通过集成本地CohereRerank,显着提高了其指标,拥有0.876404命中率和0.832584 MRR。
- Voyage:具有较强的初始性能,并被
cohererank(0.915730命中率,0.847940 MRR)进一步放大,表明对重新排名的响应性较高。 - JinaAI:虽然起点较低,但
big -rerank -large的收益显著(命中率0.601124,MRR 0.578652),表明重新排名显著提升了它的性能。其性能不佳的一个潜在原因可能是Embedding针对8K上下文长度进行了优化。
重新排名的影响:
- **WithoutReranker **:为每个Embedding提供基准性能。
- bge-rerrank-base:通常可以提高Embeddings的命中率和MRR。
- bge-rerank-large:此rerank通常为Embeddings提供最高或接近最高的MRR。对于一些Embeddings,它的性能可以与
cohererank相媲美或超过。 - **Cohererank **:始终如一地提高所有Embeddings的性能,通常提供最好或接近最好的结果。
重新排序的必要性:
- 数据清楚地表明重新排名在优化搜索结果中的重要性。几乎所有的Embeddings都受益于重新排序,显示出更高的命中率和mrr
- 重新排序器,特别是
CohereRerank,已经证明了它们将平均表现的Embedding转化为具有竞争力的能力,正如JinaAI所看到的那样。
整体优势:
当考虑到命中率和MRR时,
OpenAI + CohereRerank和Voyage + big-reranker-large的组合成为最热门的竞争者。然而,
cohererank/big-reranker-largereranker在各种Embeddings中所带来的持续改善,使它们成为提高搜索质量的突出选择,无论使用的Embedding是什么。
综上所述,为了实现命中率和MRR的峰值性能,OpenAI或Voyage Embeddings与cohererank/big-reranker-largeReranker的组合脱颖而出。
结论:
在这篇博文中,我们演示了如何使用各种Embeddings和重新排序器来评估和提高检索器的性能。以下是我们的最终结论。
- Embeddings:
OpenAI和VoyageEmbeddings,特别是当与CohereRerank/big-reranker-largereranker配对时,为命中率和MRR设定了黄金标准。 - 重排器:重排器的影响,特别是
cohererank/big-reanker-large,怎么强调都不为过。它们在提高许多Embeddings的MRR方面发挥了关键作用,显示了它们在使搜索结果更好方面的重要性。 - 基础是关键:为初始搜索选择正确的Embedding是至关重要的;如果基本搜索结果不好,即使是最好的重新排名器也帮不上什么忙。
- **一起工作:**为了获得最好的寻回犬,找到Embeddings和重新排序的正确组合是很重要的。这项研究表明,仔细测试并找到最佳配对是多么重要。
原文:https://blog.llamaindex.ai/boosting-rag-picking-the-best-embedding-reranker-models-42d079022e83

