这是一篇翻译文章,觉得确实很有启发,所以发出来大家一起看看。
我们现在做RAG应用,对于tokens确实很敏感,能省一些是一些吧,但是这篇文章是针对英文的,不知道对于中文支持的怎么样?
我们后面也会真正用起来,会再给大家汇报一下使用效果,或者会发布我们自己的改良方法。
感谢原作者:Iulia Brezeanu,原文和引用在文末。
推理过程是使用大型语言模型时消耗资金和时间成本的因素之一,对于较长的输入,这个问题会更加凸显。下面,您可以看到模型性能与推理时间之间的关系。
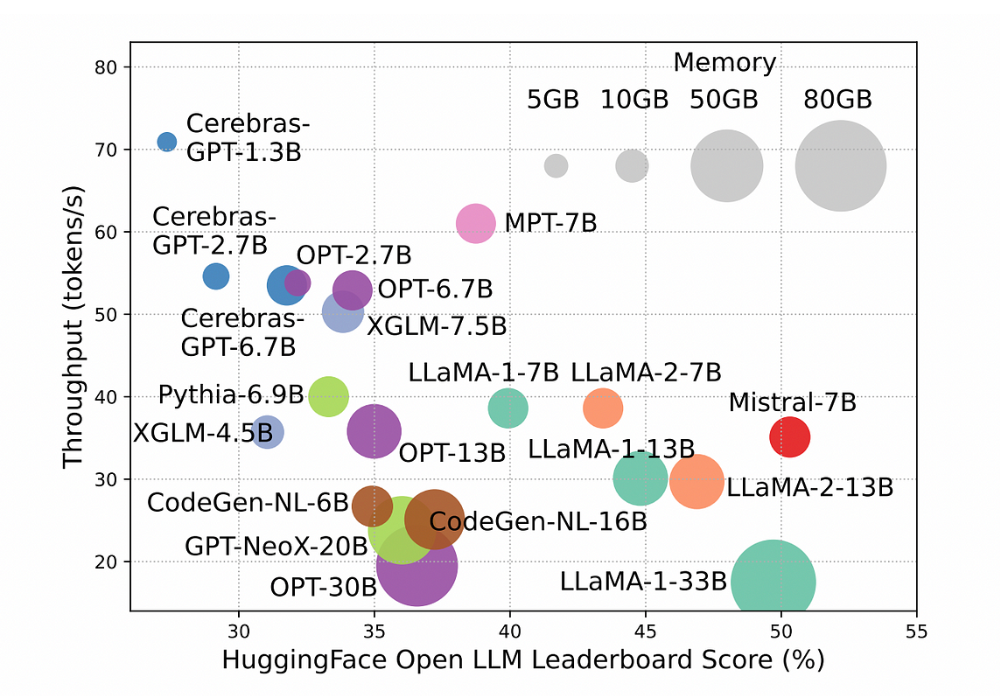
小型模型每秒生成更多的tokens,往往在Open LLM排行榜上得分较低。增加模型参数大小可以提高性能,但会降低推理吞吐量。这使得在实际应用中部署它们变得困难[1]。
提高LLMs的速度并减少资源需求将使其能够更广泛地被个人或小型组织使用。
对于提高LLM的效率,目前大家提出了不同的解决方案来,有些人会关注模型架构或系统。然而,像ChatGPT或Claude这样的专有模型只能通过API访问,因此我们无法改变它们的内部算法。
本文我们将讨论一种简单且廉价的方法,该方法仅依赖于改变输入给模型的方式——即提示压缩。
首先,让我们澄清LLMs如何理解语言。理解自然语言文本的第一步是将其分割成片段。这个过程被称为tokenization(标记化)。一个token可以是一个完整的单词,一个音节,或者是当前口语中经常使用的字符序列。

作为一个经验法则,tokens的数量通常比单词的数量高出33%。因此,1000个单词大约对应1333个tokens。让我们具体看一下OpenAI gpt-3.5-turbo模型的定价,因为这是我们将来要使用的模型。

我们可以看到,推理过程对输入tokens(对应发送给模型的提示)和输出tokens(模型生成的文本)都有成本。
输入tokens消耗最多资源的应用之一是检索增强生成。输入甚至可以达到数千个tokens。在检索增强生成中,用户查询被发送到一个向量数据库,从中检索出最相似的信息,并与查询一起发送到LLM。在向量数据库中,我们可以添加模型在初始训练中未见过的个人文档。

发送到LLM的tokens数量可能会很大,这取决于从数据库中检索到多少文本块。
Prompt 压缩

Prompt压缩可以缩短原始提示,同时保留最重要的信息。它还可以加快语言模型处理输入的速度,帮助生成快速准确的答案。
这种技术利用了语言中常常包含不必要的重复。研究表明,英语在段落或章节长度的文本中有很多冗余,大约占75% [2]。这意味着大部分单词可以从它们前面的单词中预测出来。
自动压缩机(AutoCompressors)
我们将要讨论的第一种压缩方法是AutoCompressors。它通过将长文本总结为称为摘要向量的短向量表示来工作。这些压缩的摘要向量然后作为模型的软提示。

在软提示期间,预训练模型保持冻结状态,并在每个特定任务的输入文本开头添加了少量可训练的标记。这些标记不是固定的,而是通过训练学习得到的。它们在整个模型的上下文中进行端到端优化,以最适合特定任务。

对于RAG,索引文档可以进行预处理,以转化为摘要向量。在检索阶段,检索到的块被融合并发送到LLM。融合过程意味着它们的向量表示被连接在一起,形成一个单一、更长的向量。这些向量基本上是堆叠在一起的。
为了创建这些摘要向量,您可以选择自己训练一个压缩器,或者使用一个预训练的压缩器。下面是一个使用来自论文[5]的GitHub页面的预训练压缩器的API示例。

AutoCompressor-Llama-2–7b-6k是LLama-2–7B模型的优化版本。它在一块NVIDIA A100 80GB GPU上进行了优化。训练数据包括来自RedPajama的150亿个tokens,每个序列包含6144个tokens。在训练过程中,LLama-2模型本身保持冻结状态。只有摘要tokens embedding和注意力权重使用LoRA进行了优化。
选择性背景

在信息论中,熵衡量了一段信息的不可预测性或不确定性。在语言模型的背景下,它代表了在预测序列中下一个token的不确定程度。熵越高,不可预测性越大。
当一个LLM以高确定性预测token时,这些token对模型的总熵贡献较小。这促使引入一种基于从数据中删除可预测token的prompt压缩方法。
这个想法是,如果移除低困惑度的token,对LLM对上下文的理解影响较小,因为这些token本身并没有提供太多新信息。高困惑度的标记被认为具有较高的自信息值。
为了压缩prompt,像Llama或GPT-2这样的基础语言模型为每个词汇单元分配一个自信息值(基本上表示对其出现感到惊讶的程度)。词汇单元可以是短语、句子或标记,具体取决于我们的选择。然后,基础模型按降序对单元进行排名,并仅保留来自第p个百分位数的单元,其中p是我们可以设置的变量。作者选择了基于百分位数的方法而不是绝对值方法,因为它更加灵活。
让我们看一个以不同词汇单位压缩的文本示例。

使用不同的词汇单位和比率进行选择性上下文的文本压缩。图片由作者提供。
在这三个词汇单元之间,句子级压缩保持原始句子完整。此外,较低的压缩比可以更大程度地压缩文本。
LongLLMLingua

最后一个我们要讨论的压缩方法是LongLLMLingua。LongLLMLingua基于LLMLingua,它使用类似Llama的基础LLM来评估提示中每个token的困惑度,并丢弃那些困惑度较低的token。这种方法基于信息熵,类似于选择性上下文。
然而,LLMLingua并非直接删除tokens,而是使用了一个预算控制器、一个token级别的prompt压缩算法和一个分布对齐机制。我们不会详细介绍,但你可以在原始论文[8]中阅读更多相关内容。
LLMLingua的问题在于在压缩过程中没有考虑用户的问题,可能会保留与问题无关的信息。LongLLMLingua声称通过将用户的问题纳入压缩过程来改善这个缺点。
他们带来的四个新组件是一个问题感知的粗细压缩方法,一个文档重新排序机制,压缩比率,以及一个压缩后子序列恢复策略,以提高LLMs对关键信息的感知。
Question-Aware Coarse-Grained Compression 问题感知的粗粒度压缩
意味着不再单独查看每个文档,而是检查每个文档与问题的关联性。如果一个文档使问题对模型来说更加预期或“不那么令人惊讶”,那么它被视为更重要。
Question-Aware Fine-Grained Compression 问题感知的细粒度压缩

首先,我们测量一个词通常的惊讶程度(不考虑问题)。这就是*perplexity(x_i | x<i),它表示在看到单词x_i之前的所有单词时感到困惑或惊讶。然后,我们再次测量困惑,但这一次包括上下文中的问题。这就是perplexity(x_i | x^que, x<i)*,意思是看到给定问题的单词x_i及其前面的所有单词时的惊喜。
这个想法是找出每个词对问题的惊讶程度产生了多大的改变。如果一个词在包含问题时变得不那么令人惊讶,那么它可能与问题非常相关。
然后,我们根据第一步得到的重要性分数,按降序重新排列文档。这样,最重要的文档会排在前面。
Subsequence recovery 子序列恢复

压缩后,关键实体如日期或姓名可能会发生变化。例如,“2009”可能变成“209”,或者“威廉·康拉德·伦琴”可能变成“威廉根”。为了避免这个问题,我们首先识别LLM响应中与压缩提示的一部分匹配的最长子字符串。这个子字符串被视为关键实体。接下来,我们找到对应于压缩实体的原始、未压缩的子序列。然后,我们用原始实体替换压缩实体。
在RAG中使用LlamaIndex和prompt压缩
我们将使用尼古拉斯·凯奇的维基百科页面进行实际的RAG应用。可能,模型已经在其训练数据中看到了关于这位演员的信息,所以我们正在指定我们只期望基于检索到的上下文给出答案。我们正在使用WikipediaReader()加载器加载维基百科页面。
1 | from llama_index import ( |
现在,我们正在构建一个简单的向量存储索引。只需一行代码即可对文档进行分块、嵌入和索引。
检索器将用于返回与用户查询最相关的文档。它通过计算查询与嵌入空间中的各个文档块之间的相似度来实现。我们希望检索出两个最相似的文档块。
1 | index = VectorStoreIndex.from_documents(documents) |
现在我们的数据存储在索引中,我们发起一个用户查询。retriever.retrieve(question)函数在索引中搜索与查询最相似的两个数据块。
1 | question = "Where did Nicolas Cage go to school?" |
上下文列表包含具有元数据和与其他节点的关系信息的NodeWithScore数据实体。目前,我们只对内容感兴趣。
1 | context_list = [n.get_content() for n in contexts] |
这是检索到的上下文。即使我们选择只获取前两个文档,我们仍然需要处理大量的文本。

根据用户查询检索到的文本。作者提供的图片。
我们将这些相关的片段与原始查询结合起来创建提示。我们将使用提示模板而不仅仅是f-string,因为我们希望在后续中能够重复使用它。
然后我们将这个提示输入到gpt-3.5-turbo-16k中生成一个回应。
1 |
|
输出:
尼古拉斯·凯奇曾就读于贝弗利山高中,后来进入了加州大学洛杉矶分校戏剧、电影和电视学院。
现在,让我们在使用不同的提示压缩技术后测量RAG性能。
选择性背景
我们将使用0.5的reduce_ratio,并观察模型的表现。如果压缩能够保留我们感兴趣的信息,我们将降低该值以压缩更多的文本。
1 | from selective_context import SelectiveContext |
这是简化后的内容。

使用选择性上下文减少内容。作者提供的图片。
很遗憾,尽管在句子层面上进行了压缩,但关于尼古拉斯·凯奇上学的信息丢失了。我们还尝试了标记和短语级别的压缩,但信息仍然缺失。
输出:
提供的信息没有提到尼古拉斯·凯奇上过哪所学校。
LongLLMLingua 长LLMLingua
1 | # Setup LLMLingua |
postprocess_nodes函数是我们最关心的函数,因为它可以根据查询缩短节点文本。
1 | from llama_index.indices.query.schema import QueryBundle |
现在让我们看看结果。
1 | original_contexts = "\n\n".join([n.get_content() for n in retrieved_nodes]) |
Original Tokens: 2362
Compressed Tokens: 344
Compressed Ratio: 6.87x
压缩的上下文:

让我们看看模型是否理解了压缩的上下文。
1 | response = synthesizer.synthesize(question, new_retrieved_nodes) |
输出:
尼古拉斯·凯奇曾就读于贝弗利山高中。
从使用longllmlingua压缩的上下文中,可以清楚地看出演员上学的地方。我们还几乎减少了7倍的输入标记!这意味着节省了0.00202美元。想象一下对于10亿个标记的成本减少。通常情况下,它们将花费1000美元,但通过提示压缩,我们只需支付约150美元。

结论
在讨论的方法中,LongLLMLingua似乎是在RAG应用中进行快速压缩最有前景的方法。它将提示压缩了6-7倍,同时仍保留了生成准确回答所需的关键信息。
这是原文链接:How to Cut RAG Costs by 80% Using Prompt Compression
引用
LLMLingua: Compressing Prompts for Accelerated Inference of Large Language Models
LongLLMLingua: ACCELERATING AND ENHANCING LLMS IN LONG CONTEXT SCENARIOS VIA PROMPT COMPRESSION
可以点击“阅读原文”获得可点击的链接。
Update: 2024-01-26

我们的TorchV Bot产品目前已经开始试用了,详情可以点击:https://www.luxiangdong.com/2024/01/25/lanuch-1
目前只接受企业用户试用,需要您填写一些信息,必要信息如下:
邮箱: 用来接收地址和账号
如何称呼您:
所服务的公司:
您的职位:
当然,如果您可以告诉我们您的使用场景,我们将更加感激!
对了,可以发送到yuanwai@mengjia.net
另外,也可以直接加我微信(lxdhdgss)联系我。

