春节前最后一篇,我们来讨论一下在Agent未介入的情况下,RAG如何做到慢思考(相对全面的思考)?
RAG是快思考 OR 慢思考?
相信很多朋友都读过丹尼尔·卡尼曼的《思考,快与慢》,卡尼曼把人类的思考方式比喻为两个系统:
- 系统1:快思考,反应快速、依赖直觉,几乎不需要我们的努力就能完成任务;
- 系统2:慢思考,懒惰,工作起来就需要我们集中注意力,但它也理性、精确。
我们每天都在两个系统间切换。
例如:一眼辨出两条线段的长短只要系统1工作即可,而估算几条线段的平均长度,则非要系统2出马不行。
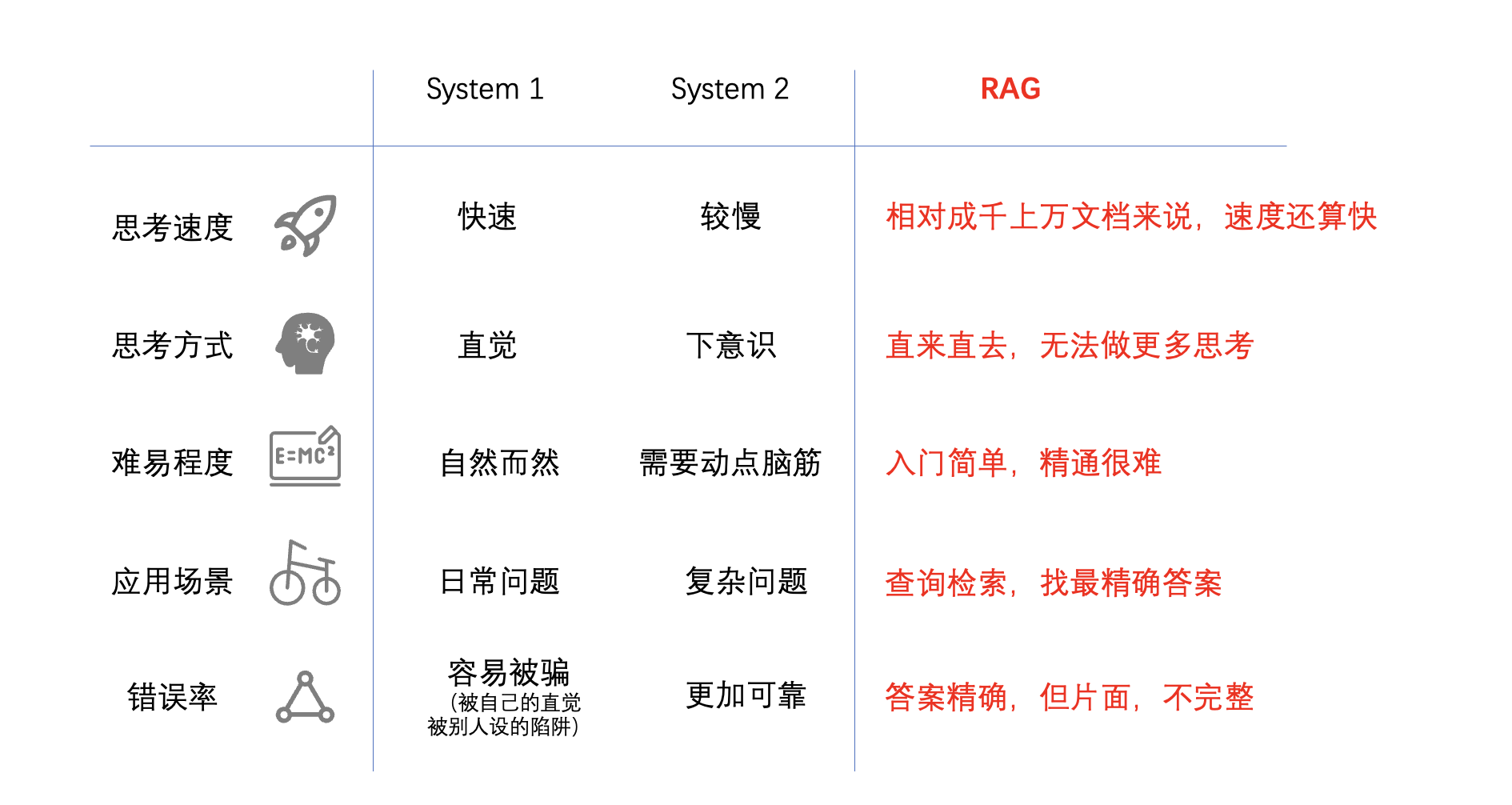
系统1虽然不精确,但是却时刻待命,总能完成任务(尽管质量不敢恭维)。而系统2却常常偷懒,精力有限,除非付出主观努力,否则很难做出点什么。我们可以从下面这张图看出两者的只管区别:

OK,关于系统1和系统2大家应该能一下子就明白它们之间的区别。那么我们回到检索增强生成(Retrieval-Augmented Generation, RAG),RAG是属于系统1,还是属于系统2呢?
RAG从成千上万的文件片段中快速检索召回最“贴合”问题的那些片段,然后再Rerank,按最终的分值(Score)取top n(比如n=3),然后将这top 3的片段化妆(Prompting)一下,送给LLM去生成结果。我们也可以根据上图来衍生一张RAG特性对照的图:

就上面这张图来看,除了难易程度,其他方面RAG都更像系统1。
RAG当下最大的问题是什么?
好,先不去争论RAG是快思考还是慢思考,就目前来看,RAG最大的问题是:RAG的结果覆盖面有点窄,好像它只管精确,但不能做“思虑”周详的事情!。比如,给定某公司从2020年开始的所有采购合同文档,然后问:“近三年一共采购了多少金额的水泥?”[1]这个问题,对于RAG又应该如何解决呢?
要解决这个问题,其实就是要让RAG具备一些系统2的能力,第一直觉是要搭配Agent,比如CrewAI[2]这样的串行Agent框架。
但就我个人感觉来说,现在的Agent还不够好,当然我认同Agent一定是主流方法。现在的Agent更多是把任务一个个切分出来,按顺序排列执行,各切分出来的Agent各自和LLM交互,然后把判断的权利也给了LLM(完成?重做?)。其实Agent更应该是一组深度强化学习驱动的具备自我优化能力的节点,自己可以完成结果的判断,而不仅仅只做一个路由器(或分发器)。加上最致命的是国内自己的大模型在能力和GPT-4依然还有距离,所以直接上Agent,恐怕效果不见得会多好。
所以对于Agent,我的看法是还需要看国产大模型的能力,还需要等待真正基于深度强化学习的框架出现。
那么,这种情况下要让RAG有“慢思考”能力,还会有其他更好的方案吗?答案肯定是:有!
让RAG慢思考的两个非直接方案
既然不用Agent,那我们又从哪里入手让RAG具备“慢思考”的能力呢?

在RAG的整个流程中,第一部分“提取”可操作的空间不大,而如果去大量操作最后一部分“生成”的话,其实就是去频繁地去和LLM对话,更像是Agent。可是本文我们已经说了,先不说Agent的,虽然我应该再强调一次,Agent未来一定是主流。
所以剩下的就是答案了,就是在“索引”和“检索”两大环节里面“动手脚”了:
- 索引:无论是分块、做元数据索引,还是做向量化,通俗地说就是创造数据结构的过程;
- 检索:有了数据结构之后,通过各类算法(如KNN、HNSW、TF-IDF等)进行搜索排序和过滤,去权衡算法之间的优劣势,这就是一个算法分析和实现的过程。
好吧,这两大环节,其实就是数据结构与算法分析(不卖书!!!),这一刻我是真正领悟到大学老师的良苦用心了,挣扎多年,一旦我们走出CURD的沼泽,数据结构与算法才是区分码农能力的试金石!

好了,废话不多数了,下面介绍两个最新的方案,也许可以对大家有一些启发。
一、递归聚类索引,解决资料完备问题
该方案最大的特点在于索引创建的环节,对应于我们的TorchV的话,就是在用户上传了文档之后,等待系统处理的阶段。
该方法的名字是RAPTOR(RECURSIVE ABSTRACTIVE PROCESSING FOR TREE-ORGANIZED RETRIEVAL,树检索的递归抽象处理),我最早是在X上看到的[3],下面我们先看看RAPTOR的工作流程和原理。

RAPTOR基于向量Embeddings递归地对文本块进行聚类,并生成这些聚类的文本摘要,从下向上构建树。聚集在一起的节点是兄弟姐妹;父节点包含该集群的文本摘要。具体的方法如下:
- 文本分割
- 将检索语料库拆分为100个tokens的短的连续的chunk,类似于传统方法
- 保持句子完整,即使超过100个tokens,以保持连贯性
- Text Embedding
- 嵌入文本块使用SBERT获得密集的向量表示
- Clustering
- 采用软聚类使用高斯混合模型和UMAP降维
- 更改UMAP参数以识别全局和本地集群
- 采用贝叶斯信息准则进行模型选择,确定最优聚类数量
- Summarization
- 使用LLM来总结每个簇(cluster)中所有chunks
- 生成捕获关键信息的简明摘要
- 创建节点
- 聚类块+相应的摘要=新的树节点
- Recursive Processing
- 重复 steps 2-5: 重新嵌入摘要,集群节点,生成更高级别的摘要
- 从下向上形成多层树
- 直到聚类不可行(最终根节点总结整个语料库)
- Retrieval
- 两种方法:树遍历(自上而下一层一层)或折叠树(扁平视图)
- 对于每一个,计算查询和节点之间的余弦相似度,以找到最相关的

根据论文[4]指出,使用RAPTOR方式创建的索引,在RAG过程中效果会更加突出。但是我感兴趣的其实不在这里,而是整篇论文中的一句话:
传统RAG在非连续文档、跨文档主题和分散型主题内容时效果不佳.
而RAPTOR则可以利用高斯混合模型和UMAP降维等技术,使用递归形式将散落的片段先按层级组织起来。
好了,在RAG中,因为资料检阅不充分的情况是不是会被极大解决了,要计算三年的水泥销售额,至少RAPTOR已经有能力把所有与水泥相关的资料都给你找到了。
二、状态存储和控制,解决过程计算问题
这个方案其实是我自己提的,目前也还在有限探索范围内,下面我们针对前置的合同评审,先用一张图解释一下:

- 针对业务设定问题:假设借款合同,我们现在先列出预审时法务部门需要首先筛选的一系列问题,在图的左上角用Q1-Qn列出;
- 使用RAG逐个去检索和召回问题,Q1的问题可以再细化问甲方的名称、乙方的名称,检查是否以“有限公司”结尾,如果两者都是True,那么Result=True && True = True;
- 设定操作:问题Q1-Qn,在思考的过程中,中间状态存储在上图右侧的二叉树(已经简化,实际不是二叉树)结构中。根Node代表最终结果,且存储叶节点的计算操作(与或、加减乘除…),左右叶子Node代表的临时状态。他们的问题被存储在上方的数组Q1-Qn中;
- 全部执行结束后,针对问题逐个打印输出✅❎,输出预审报告。
该方法目前还处在实验阶段,很明显的问题是设置的内容会比较多,比如问题、比如运算操作等等,但是在一些具体的业务场景中,设置后能够长期使用和批量使用,那就是有性价比的尝试。然后等待国产LLM崛起,我相信用上配合Agent之后,可行性会更好。
结论
RAG目前已经是大语言模型(LLM)在落地场景中非常重要的存在了,但是RAG依然有一些严重的缺点,最直接的就是思考不全面,类似与《思考,快与慢》中提到的System1。那么我们如何让RAG思考更加全面呢?个人觉得未来最好的方式应该是结合Agent,更多借助LLM的能力。但是现在我们似乎也需要找一条更现实的路线,来渡过LLM还未成熟的岁月。
RAPTOR的能力已经让我们看到了它可以在RAG中让主题文件充分聚类,解决了传统RAG在跨文件、非连续文档中存在的召回“片面”问题;而利用树结构来存储多个问题的临时状态,并按数据顺序进行计算,则可以让RAG实现报表形式(问题1、问题2、问题3….问题n)的输出。这两者的结合,也许可以为RAG的“慢思考”发展提供一些思路。
好了,今天就写到这里,祝大家龙年快乐!身体健康!万事如意!财源滚滚!

对了,再宣传一下TorchV Bot吧,这是我们的第一个基线产品,已经接受企业用户试用了。如果:
- 您是企业用户
- 需要一个极其了解您业务的AI对话Bot服务
- 或您需要和内部海量文档对话,如项目管理
- 或需要一个AI工业操作指导专家
- 或需要一个……反正都可以试试,哈
可以给我发邮件:yuanwai@mengjia.net,把您的称呼+公司+使用场景描述一下,我就会发给您试用账号。
引用
[1]共识粉碎机的EP15提到的RAG问题—https://mp.weixin.qq.com/s/phWsKbdrwt0g0iyLMZUzxg
[2]关于CrewAI—https://medium.com/@mayaakim/crewai-a-team-of-ai-agents-that-work-together-for-you-4cc9d24e0857
[3]RAPTOR推特线程—https://twitter.com/IntuitMachine/status/1753044020601696317
[4]RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval—https://arxiv.org/abs/2401.18059

