对于RAG,从文档中提取信息是一个不可避免的场景。确保从源头提取内容的有效性对于提高最终输出的质量至关重要
重要的是不要低估这个过程。在实现RAG时,解析过程中的信息提取不佳可能导致对PDF文件中包含的信息的理解和利用受到限制。
pass过程在RAG中的位置如图1所示:
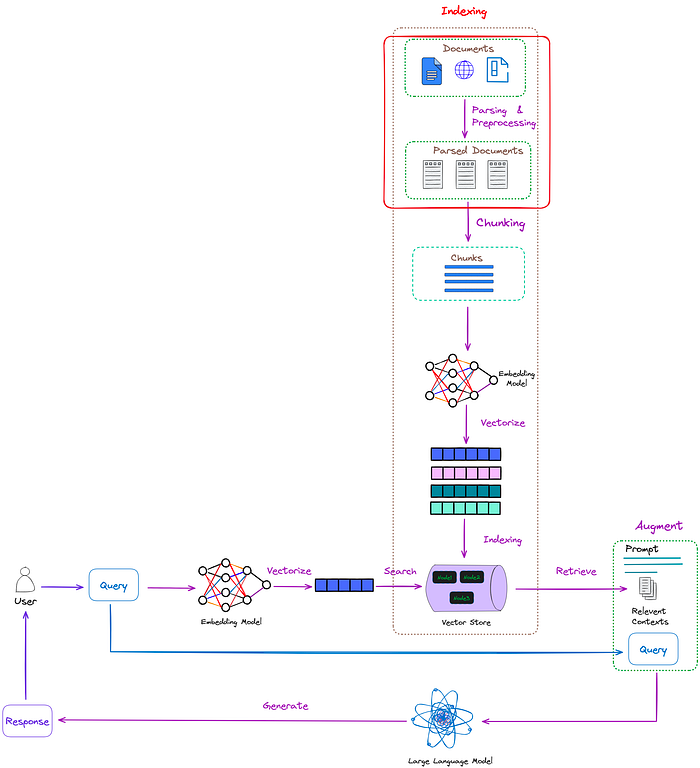
图1:通过过程在RAG中的位置(红框)。图片来自作者。
在实际工作中,非结构化数据要比结构化数据丰富得多。如果这些海量的数据不能被解析,它们的巨大价值就无法实现。
在非结构化数据中,PDF文档占多数。有效地处理PDF文档还可以**极大地帮助管理其他类型的非结构化文档
本文主要介绍解析PDF文件的方法。它提供了有效解析PDF文档和提取尽可能多的有用信息的算法和建议
解析PDF的挑战
PDF文档是非结构化文档的代表,但是,从PDF文档中提取信息是一个具有挑战性的过程。
与其说PDF是一种数据格式,不如将其描述为打印指令的集合更为准确。PDF文件由一系列指令组成,这些指令指示PDF阅读器或打印机在屏幕或纸张上显示符号的位置和方式。这与HTML和docx等文件格式形成对比,后者使用<p>、<w:p>、<table>和 <w:tbl>>来组织不同的逻辑结构,如图2所示:
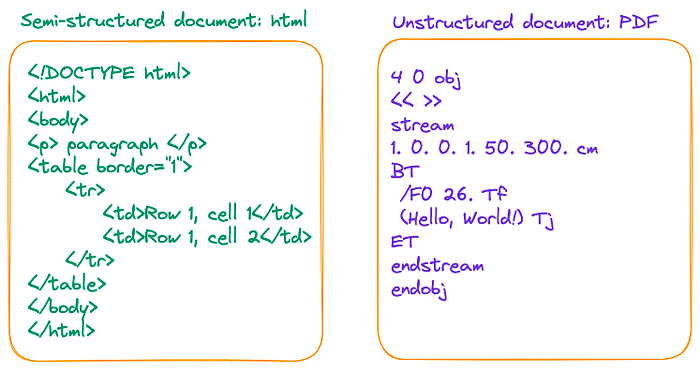
图2:Html与PDF。图片来自作者。
解析PDF文档的挑战在于准确地提取整个页面的布局,并将内容(包括表格、标题、段落和图像)翻译成文档的文本表示形式。该过程涉及处理文本提取、图像识别和表中行-列关系的混淆中的不准确性。
如何解析PDF文档
一般来说,有三种解析pdf的方法:
- 基于规则的方法:根据文件的组织特征确定每个部分的风格和内容。然而,这种方法不是很通用,因为pdf有许多类型和布局,因此不可能用预定义的规则覆盖它们。
- 基于深度学习模型的方法:如目前流行的结合物体检测和OCR模型的解决方案。
- 基于多模态大模型传递复杂结构或提取pdf中的关键信息。
基于规则的方法
最具代表性的工具之一是pypdf,它是一种广泛使用的基于规则的解析器。它是Langchain和LlamaIndex中解析PDF文件的标准方法。
下面是尝试使用pypdf解析“(Attention Is All You Need)”论文的第6页。原始页面如图3所示。

图3:“Attention Is All You Need”论文的原始第6页。
代码如下:
1 | import PyPDF2 |
执行的结果是(为简洁起见,省略了其余部分):
1 | (py) Florian:~ Florian$ pip list | grep pypdf |
基于PyPDF检测的结果,观察到它将PDF中的字符序列序列化为单个长序列,而不保留结构信息。换句话说,它将文档的每行视为由换行字符“\n”分隔的序列,这妨碍了对段落或表格的准确识别。
这种限制是基于规则的方法的固有特征。
基于深度学习模型的方法。
这种方法的优点是它能够准确地识别整个文档的布局,包括表格和段落。它甚至可以理解表中的结构。这意味着它可以将文档划分为定义良好的完整信息单元,同时保留预期的含义和结构。
然而,也有一些限制。目标检测和OCR阶段可能很耗时。因此,建议使用GPU或其他加速设备,并使用多个进程和线程进行处理。
这种方法涉及到对象检测和OCR模型,我已经测试了几个代表性的开源框架:
非结构化:已集成到Langchain。
infer_table_structure=True的hi_res策略的表识别效果较好。然而,fast策略表现不佳,因为它没有使用目标检测模型,错误地识别了许多图像和表格。Layout-parser:如果您需要识别复杂的结构化pdf,建议使用最大的模型以获得更高的精度,尽管它可能会稍微慢一些。此外,似乎Layout-parser的模型在过去两年中没有更新过。
PP-StructureV2:采用多种模型组合进行文档分析,性能高于平均水平。架构如图4所示:
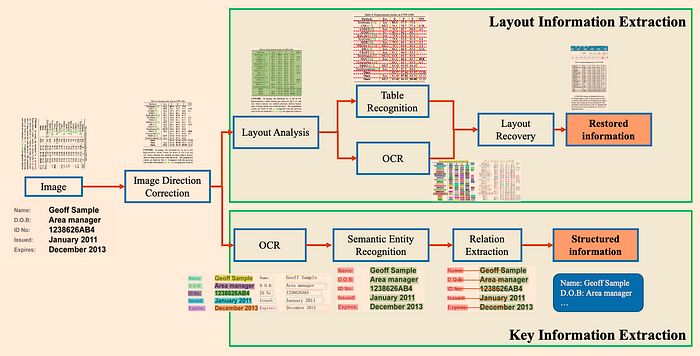
图4:拟议PP-StructureV2的框架。它包含布局信息提取和关键信息提取两个子系统。来源:PP-StructureV2。
除了开源工具之外,还有一些付费工具,比如ChatDOC,利用基于布局的识别+ OCR方法来解析PDF文档。
接下来,我们将解释如何使用开源**非结构化 **框架解析pdf,解决三个关键挑战
挑战1:如何从表和图像中提取数据
在这里,我们将使用非结构化框架作为示例。检测到的表数据可以直接导出为HTML。其代码如下:
1 | from unstructured.partition.pdf import partition_pdf |
我已经跟踪了partition_pdf 函数的内部过程。图5是一个基本流程图。
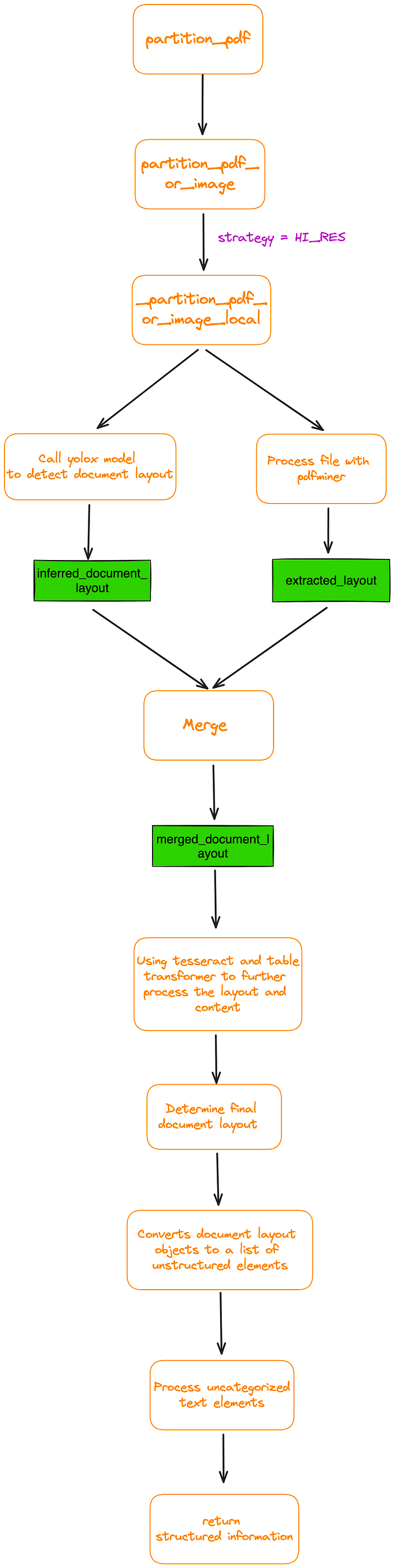
图5:**partition_pdf**函数的内部过程。图片来自作者。
代码运行结果如下:
1 | Layer Type Self-Attention Recurrent Convolutional Self-Attention (restricted) Complexity per Layer O(n2 · d) O(n · d2) O(k · n · d2) O(r · n · d) Sequential Maximum Path Length Operations O(1) O(n) O(1) O(1) O(1) O(n) O(logk(n)) O(n/r) |
复制HTML标记并将其保存为HTML文件。然后,使用Chrome打开它,如图6所示:

图6:图3中表1的可视化表示。图片来自作者。
可以看出,非结构化算法在很大程度上恢复了整个表。
挑战2:如何重新排列检测到的方块?特别是对于双列pdf文件
在处理双列pdf时,让我们以论文“BERT:用于语言理解的深度双向Transformers的预训练”为例。阅读顺序用红色箭头表示:

图7:双列页面。
在确定布局之后,非结构化框架将把每个页面划分为几个矩形块,如图8所示。

图8:布局检测结果的可视化。图片来自作者。
每个矩形块的详细信息可以通过以下格式获得:
1 | [ |
式中(x1, y1)为左上顶点的坐标,(x2, y2)为右下顶点的坐标:
1 | (x_1, y_1) -------- |
此时,您可以选择重新调整页面的阅读顺序。Unstructured自带内置排序算法,但我发现在处理双列情况时排序结果不是很令人满意。
因此,有必要设计一种算法。最简单的方法是先按左上角顶点的水平坐标排序,如果水平坐标相同,再按垂直坐标排序。伪代码如下:
1 | layout.sort(key=lambda z: (z.bbox.x1, z.bbox.y1, z.bbox.x2, z.bbox.y2)) |
然而,我们发现即使在同一列中的块也可能在其水平坐标上有变化。如图9所示,紫色线块的水平坐标bbox。X1实际上更靠左。排序时,它将被放置在绿行块之前,这显然违反了读取顺序。

图9:同一列的水平坐标可能有变化。图片来自作者。
在这种情况下,一个可能使用的算法如下:
- 首先,对所有左上角的x坐标
x1进行排序,我们可以得到x1_min - 然后,对所有右下角的x坐标
x2进行排序,我们可以得到x2_max - 接下来,确定页面中心线的x坐标为:
1 | x1_min = min([el.bbox.x1 for el in layout]) |
接下来,**if bbox.x1 < mid_line_x_coordinate **,该块被分类为左列的一部分。否则,它被认为是右列的一部分。
分类完成后,根据列中的y坐标对每个块进行排序。最后,将右列连接到左列的右侧。
1 | left_column = [] |
值得一提的是,这种改进还与单列pdf兼容。
挑战3:如何提取多级标题
抽取题目(包括多级题目)的目的是为了提高LLM答案的准确性。
例如,如果用户想知道图9中section 2.1的主要思想,通过准确提取section 2.1的标题,并将其与相关内容作为上下文一起发送给LLM,最终答案的准确性将大大提高。
该算法仍然依赖于图9所示的布局块。我们可以使用**type='Section-header提取块并计算高度差(bbox.y2 - bbox.y1 **)。高差最大的块对应第一级标题,其次是第二级标题,最后是第三级标题。
基于多模态大模型在pdf中传递复杂结构
在多模态模型爆发之后,也可以使用多模态模型来解析表。有几个选项:
- 检索相关图像(PDF页),并将其发送给GPT4-V,以回应查询。
- 将每个PDF页面视为图像,让GPT4-V对每个页面进行图像推理。为图像推理建立文本矢量存储索引。根据图像推理向量库查询答案。
- 使用表转换器从检索到的图像中裁剪表信息,然后将这些裁剪后的图像发送到GPT4-V进行查询响应。
- 对裁剪的表格图像应用OCR,并将数据发送到GPT4/ GPT-3.5来回答查询。
经过测试,确定第三种方法最有效
此外,我们可以使用多模态模型从图像中提取或总结关键信息(PDF文件可以很容易地转换为图像),如图10所示。
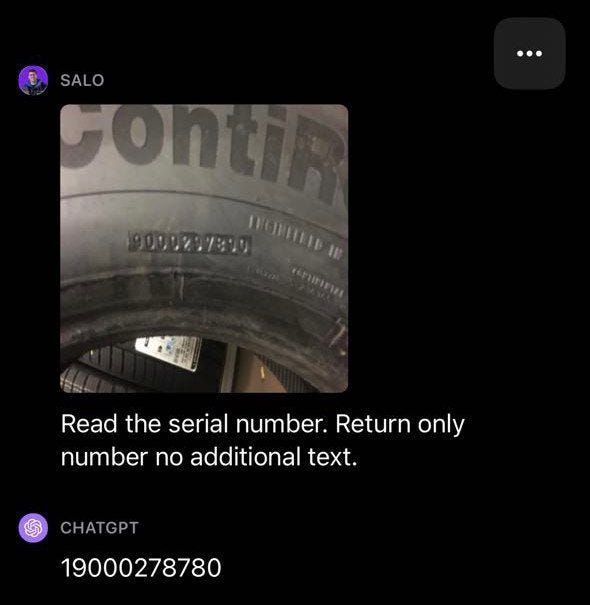
图10:从图像中提取或总结关键信息。来源:GPT-4 with Vision: Complete Guide and Evaluation。
结论
一般来说,非结构化文档提供了高度的灵活性,需要各种解析技术。然而,目前还没有达成共识的最佳方法使用。
在这种情况下,建议选择最适合您项目需求的方法。建议根据不同类型的pdf文件采用特定的处理方法。例如,文件、书籍和财务报表可能根据其特点有独特的设计
然而,如果情况允许,仍然建议选择基于深度学习或基于多模态的方法。这些方法可以有效地将文档分割成定义良好且完整的信息单元,从而最大限度地保留文档的预期含义和结构。
英文原文:https://pub.towardsai.net/advanced-rag-02-unveiling-pdf-parsing-b84ae866344e

