def cosine_pseudocode(query_v, doc_v, num_indices): """ Retrieve indices of the highest cosine similarity values between the query vector and embeddings. Parameters: query_v (numpy.ndarray): Query vector. doc_v (list of numpy.ndarray): List of embedding vectors. num_indices (int): Number of Top indices to retrieve. Returns: list of int: Indices of the highest cosine similarity values. """ cosine_similarities = [] # Initialize an empty list to store cosine similarities
query_norm = np.linalg.norm(query_v) # Calculate the norm of the query vector # Iterate over each documents embedding vectors in the list for vec in doc_v: dot_product = np.dot(vec, query_v.T) # Calculate dot product between embedding vector and query vector embedding_norm = np.linalg.norm(vec) # Calculate the norm of the embedding vector cosine_similarity = dot_product / (embedding_norm * query_norm) # Calculate cosine similarity cosine_similarities.append(cosine_similarity) # Append cosine similarity to the list cosine_similarities = np.array(cosine_similarities) # Convert the list to a numpy array # Sort the array in descending order sorted_array = sorted(range(len(cosine_similarities)), key=lambda i: cosine_similarities[i], reverse=True)
# Get indices of the top two values top_indices = sorted_array[:num_indices] # Return the indices of highest cosine similarity values return top_indices
def cosine_chunkdot(query_v, doc_v, num_indices, max_memory): """ Calculate cosine similarity using the chunkdot library. Parameters: query_v (numpy.ndarray): Query vector. doc_v (numpy.ndarray): List of Embedding vectors. num_indices (int): Number of top indices to retrieve. max_memory (float): Maximum memory to use. Returns: numpy.ndarray: Top k indices. """ # Calculate Cosine Similarity cosine_array = cosine_similarity_top_k(embeddings=query_v, embeddings_right=doc_v, top_k=num_indices, max_memory=max_memory) # Calculate cosine similarity using chunkdot
# Get indices of the top values top_indices = cosine_array.nonzero()[1] # return the top similar results return top_indices
user_query = np.random.rand(1,100) # 1 user query (100 dim)
top_indices = 1 # number of top indices to retrieve
max_memory = 5E9 # maximum memory to use (5GB)
# retrieve indices of the highest cosine similarity values using pseudocode print("top indices using pseudocode:", cosine_pseudocode(user_query, doc_embeddings, top_indices))
# retrieve indices of the highest cosine similarity values using chunkdot print("top indices using chunkdot:", cosine_chunkdot(user_query, doc_embeddings, top_indices, max_memory)) ### OUTPUT ### top indices using pseudocode: [4] top indices using chunkdot: [4] ### OUTPUT ###
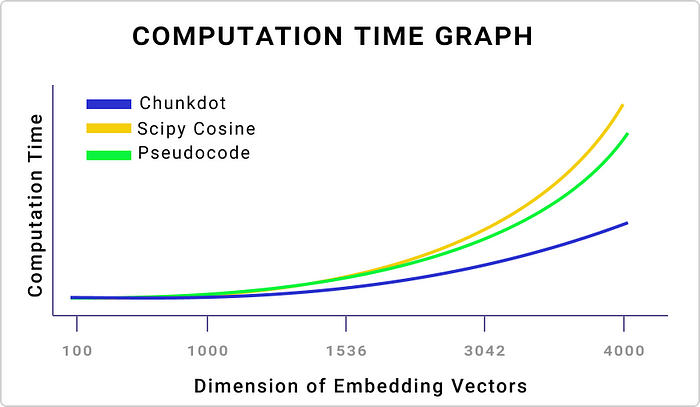
# calculate time taken def calculate_execution_time(query_v, doc_v, num_indices, max_memory, times): # calculate time taken to execute the pseudocode function pseudocode_time = round(timeit.timeit(lambda: cosine_pseudocode(query_v, doc_v, num_indices), number=times), 5)
# calculate time taken to execute the chunkdot function chunkdot_time = round(timeit.timeit(lambda: cosine_chunkdot(query_v, doc_v, num_indices, max_memory), number=times), 5)
# print the time taken print("Time taken for pseudocode function:", pseudocode_time, "seconds") print("Time taken for chunkdot function:", chunkdot_time, "seconds")