写在前面
在我的产品研发生涯中,出品的产品已经超过十个了,有 toG、toB也有toC,有复杂的,也有非常简单的。回顾这十多个产品,也发现一个有意思的想象,但凡现在依然还被很多客户在使用的,往往都是目的很纯粹的产品,至少从产品初衷来说,都是仅为了解决一个核心问题的。而那些单个产品就带有很多功能的toG系统,现在基本上都已经被扔进垃圾桶了……
所以在我和八一菜刀自己出来创业之后,就“立志”要做简单但强大的产品。
- 简单:也就是上面说的产品的初衷非常单纯,就是去解决一个问题;
- 强大:这可能有多个解释,如对客户非常有效,有很高的使用价值;产品使用体验非常好,上手很快,能被广泛使用;产品性能好,性能稳定,可解释性(可控)强。
但是过去八个月的创业经历也许并不会让我们那么顺意,有技术方向的变化,有大客户的case要完成,有生存压力,所以“立志”要做的事情好像并没有那么顺利。 虽迟但到,我们最近还是发布了两款符合我们追求的产品:TorchV Bot和TorchV Assistant。
下面介绍一下这两款产品。
TorchV Bot
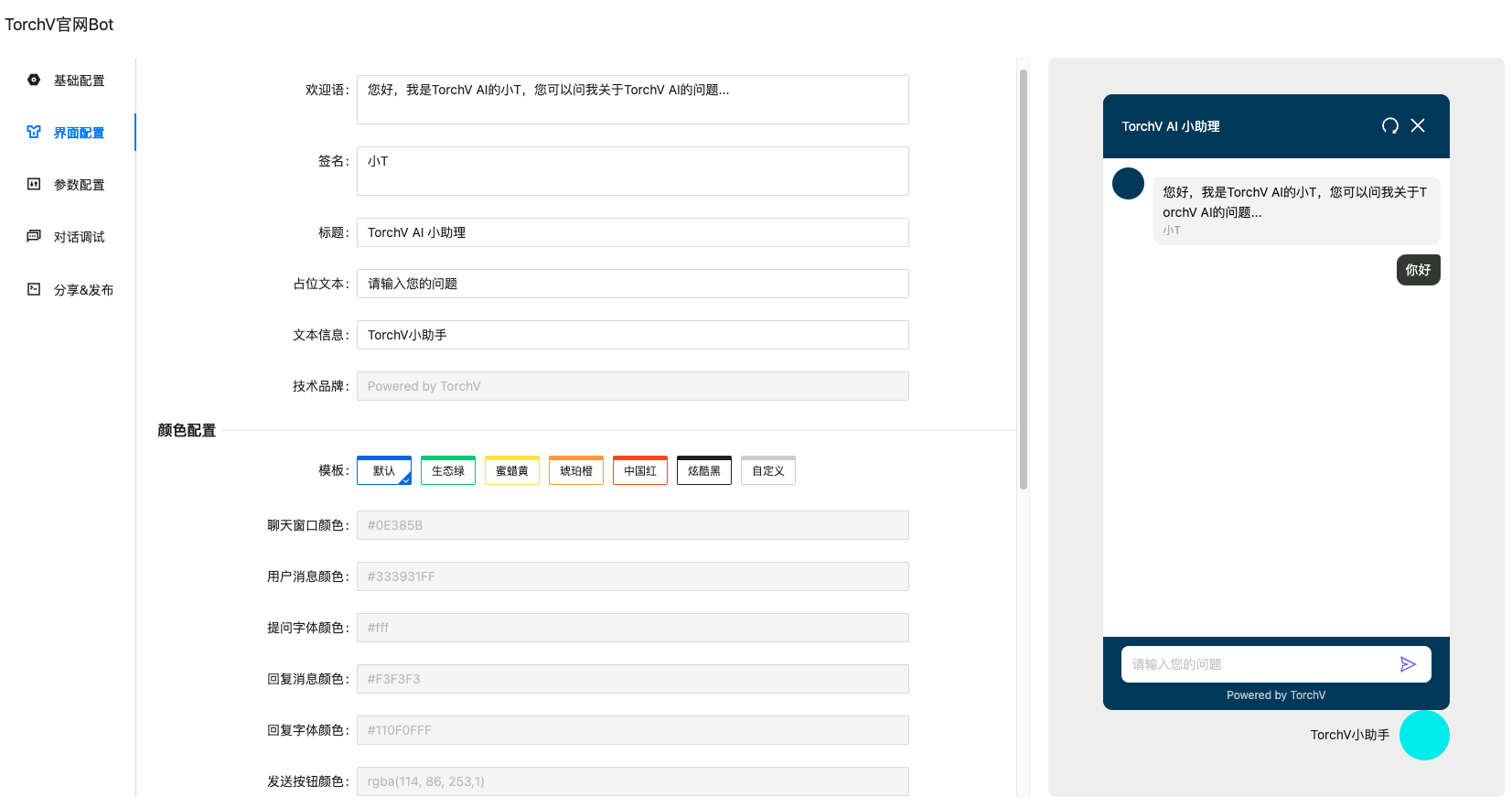
图1:TorchV Bot产品截图
四年前存在的问题
TorchV Bot应该算是最简单的产品了,其实就是对话机器人,基于知识库和大模型(LLM)对用户的提问进行回答。
说起来我们团队从2019年就开始做对话机器人的事情了,并且当时的产品也有几千万人使用过,对于对话机器人场景是非常熟悉的。当时使用的更多是NLP技术,遇到的最大问题主要是两个:
- 识别能力差:如果使用关键词匹配,那么知识库量级一大,冲突就会非常严重;如果使用向量的相似度匹配,那么就需要做很多的相似问法,比如“厕所在哪里?”,就需要增加维护相应的相似问法,如“洗手间在哪里?”等等。所以纯粹的NLP在智能客服场景是比较吃力的;
- 知识语料维护复杂:当时我们是有一个六人的知识库运营团队的,专门负责接收客户那边过来的大量资料,阅读-理解-提取QA,再维护相似问法,这个过程相当繁琐,就算是我们的专业团队,也是很吃力的。虽然我们当时确实用这种“拼命三郎”的能力打败了一众大厂,拿下了很多客户。
但这两个问题依然是严重阻碍该产品被大面积推广和被客户欢心接受的主要原因。
LLM被广泛应用之后
然而时间到了2022年底,OpenAI把大语言模型(LLM)炒热之后,我们发现这两个问题被引刃而解。这里其实并不完全是LLM的功劳,还有围绕LLM一起的其他技术,包括RAG。下面我可以简单说一下有了RAG和LLM之后是怎么被解决的。
解决识别能力差的问题
通过RAG的大量结果召回,然后rerank,已经把可能的答案都收罗进来并层层过滤了,得到的结果已经非常接近真实答案,再通过把用户问题和过滤之后的多个chunks给到LLM进行最后的选择,可以完美解决识别能力的问题。
当然,我们还在这里做了一些其他优化,比如使用元数据帮助检索系统过滤无关chunks,以及根据用户上下文进行多轮对话辅助等。
解决知识语料维护复杂问题
目前我们在处理从客户那边接收的资料时,不再需要去阅读理解和手工提取内容了。而是采用自动化进行处理,采用文件解析、chunking和embedding之后,文件被解析为向量索引,当然我们另外还用了BM25,类似于传统的倒排索引。
类似于上一小节讲到的,因为检索能力的增强,我们不需要去做复杂的QA对就能被系统检索出正确的答案,所以预料维护工作可以说已经不存在了。当然,要严格说起来,在一些专业场景下,依然会存在专有名词(库)维护、问答流程引导等需要人工去维护的情况。
关于TorchV Bot
TorchV Bot正是基于RAG和LLM的对话机器人产品,其拥有一个相对比较复杂的底层,但是对于用户来说无需关心,在使用上是非常简单的。下面我们可以通过一个例子介绍一下TorchV Bot的使用:假设你有一个公司官网,你想在官网挂载一个客服机器人,如何在十分钟内实现?
在这里我假设你已经拥有了一个TorchV AI的试用平台账号(如果您还没有,可以扫描文末的二维码联系员外进行获取,记得提供公司名称和使用场景)。
《嵌入视频》
通过上面的视频,大家能看到在官网挂载一个客服机器人有多么简单,而且TorchV Bot对准确率有较好保障。
TorchV Bot的架构如下图所示,除了视频中看到的一键嵌入这种无需开发的方式,还有API可供用户调用,可以接入到APP、小程序等更多类型客户端。
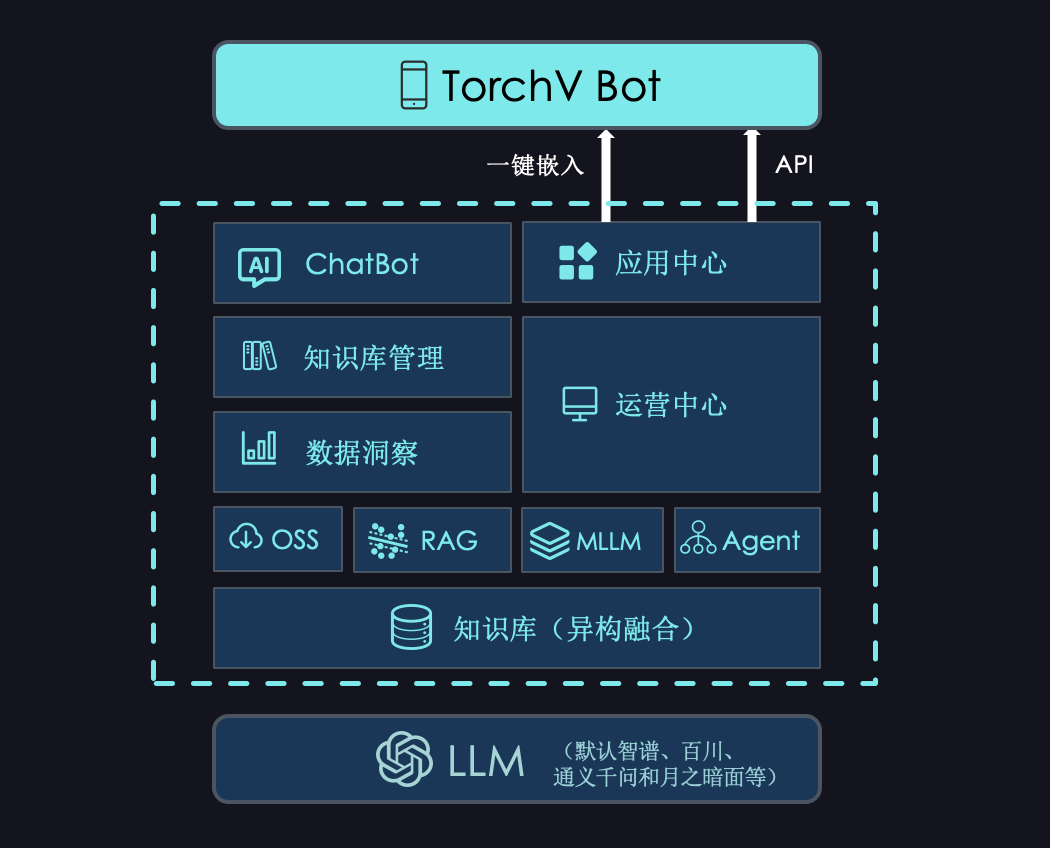
图2:TorchV Bot架构图
TorchV Assistant
先说一个暴论
在今天之前的十年或十五年,我们看到了结构化数据因为移动互联网、数字化营销、数字化运营等场景兴起被大量使用,相应的大数据应用也大量崛起,于是数据中台一直在唱高调。而时间来到2021年之后,我们发现数据中台开始逐渐走下坡路。其实在企业应用中,结构化数据存在生成难(大多数由机器、传感器或手机等终端设备生成),而且往往缺乏流程、解释性说明等知识内容,不知道knowhow很难真正挖掘企业价值。
而非结构化数据(如我们每个人都能生产的记录文章内容的Word、记录数据的Excel、产品介绍PPT和图表等)在解释流程、业务知识等方面显然更擅长。在LLM热潮之前,非结构化数据在利用方面确实是受限的,但是在这之后,情况就变得不一样了。比如前面介绍的TorchV Bot,你可以非常容易与非结构化数据进行对话,并且还可以将非结构化数据利用在其他广泛业务中,比如我们下面会讲到的TorchV Assistant。当然,我这里要说的还是知识库,它是可以融合原来的结构化数据和非结构化数据的。特别是在非结构化数据可以被轻松应用之后,知识库对与非结构化数据的四个环节算是打通了,即生产—汇集—协同—利用。
所以我要说的暴论是:因为LLM和相关技术的崛起,未来十年结合LLM的知识库会是新一波热潮,而且极有可能会比之前的数据中台更具备实战价值。
用知识库快速制作报表
制作各类业务报表应该是很多白领日常工作的重要部分,而这里花费时间最大的可能是两个环节:
- 阅读和理解大量业务资料,从中找到答案,汇总信息;
- 对报表内容进行优化,文字优化,以及对数值类内容进行表格和分析图表制作。
针对这两个环节,TorchV Assistant给出了优化方法。首先使用RAG和LLM帮助业务人员通过提问的方式获得答案,比如“XX公司从2020年到2023年的收入复合增长率是多少?”,可以大量节省阅读理解时间。另外就是利用大模型的优势对报表中的内容进行优化,还可以将数值内容选中,进行表格和分析图表的生成,非常方便。
TorchV Assistant也算是对非结构化数据利用的一种应用形式,它的主体是一个编辑器。其主要的流程非常简单,先装载文档到知识库,然后对知识库进行问答,再是优化,最后下载成Word等普通格式,根据个人喜爱再进行一些美化就可以了。
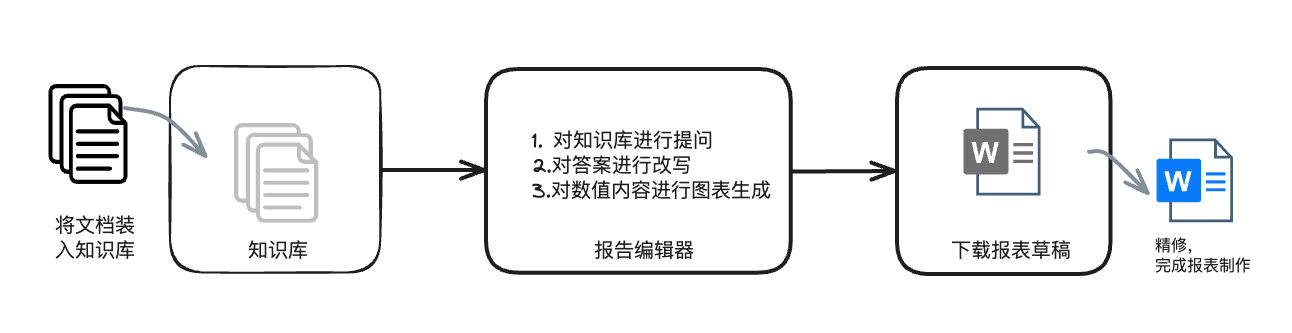
图3:TorchV Assistant业务流程图
下面我们可以通过一个不到一分钟的视频了解一下TorchV Assistant的部分功能。
《视频插入》
如果您觉得对你的业务有帮助,可以找我拿试用账号,嗯,需要告诉我您的公司名称和使用场景。
最后
好了,今天就写到这里,我们的另外两个产品也即将到来,会第一时间和大家来分享。
最后再介绍一下TorchV AI,我们是一家提供大模型(LLM)企业应用落地服务的公司,提供的内容包括:
- 和客户交流之后给出的针对大模型应用的可行性方案;
- 一整套基于Java研发的成熟大模型应用系统和不断演进的应用;
- POC、部署、对接和培训等落地服务。
如您有产品和商务方面的合作需求,可以扫以下二维码联系我。


