DeepSeek火爆现象背后企业可以得到什么实质提升?
本文的主要内容:
- DeepSeek火爆最值得关注的点;
- 企业可以在DeepSeek进化中得到哪些好处;
- 企业如何更近一步拥抱AI。
DeepSeek-R1(其实还有V3)这个春节真的太火爆了,感觉比上一个春节期间的Sora带来的轰动要更加强烈,而且在最终效果上也非常落地和成功,媒体热度和DeepSeek的服务器一样,近20天了依然热得发烫。但我们也不能只看个热闹,还是想分析一下企业AI应用市场可以在火爆现象背后得到那些实质提升。
![]()
1.最值得关注的点
这次DeepSeek最开始的爆发点是R1的RL(强化学习)和联网搜索能力,在能力上与OpenAI的o1-1217相当,而且在交互方面实现了超越。然后对岸科技圈发现训练R1的基础模型DeepSeek-V3-Base和DeepSeek-R1的训练效率极高,根据外界普遍认为DeepSeek有一万张专业卡来推算,训练成本仅是OpenAI训练o1的5%~10%。而且使用了RL进行训练还有可能出现超越人类思维的能力,这是之前直接使用人类生产的知识,以及监督学习的方式下所没有出现过的。
DeepSeek这次引起轰动的点有很多,确实非常优秀。从个人角度来说,除了能力与OpenAI o1持平之外最影响深刻的就是开源。
开源
在我们开启TorchV的创业以来,我们的客户和潜在客户一直在问一句话:“国产模型会不会和ChatGPT差距太大,效果不好啊?“
确实,说差别不大肯定是假的,我们在企业应用中会通过RAG、NLU等技术不断增加整个应用的”胶水组件“,在一定程度上弥补这种差距。但是开源大模型也一直在努力,最开始是Llama,确实为国内大模型的蓬勃发展带来巨大转机。而后Qwen一直在国内开源的道路上起到了带头大哥的作用,在Qwen-1.5/2/2.5这些阶段,确实让我们做大模型企业应用的开发者心里感受到了丝丝踏实,但是差距依然还是明显,特别是和GPT-4o、GPT-o1和Claude 3.5 Sonnet这些模型的差距还很大。这次DeepSeek-R1算是直接一杆子捅到底了,能力和OpenAI-o1-1217相当,还开源,这就一下子打破了OpenAI的技术垄断,这是国内媒体最嗨的点之一。但我看到的也许是如果你有足够的算力,在公司内部私有化一个与OpenAI-o1相当的671B大模型完全没问题了。
所以DeepSeek的开源带来两个直接影响:
- 在企业私有化大模型应用中也可以用上第一梯队的模型了,至少在当下,且我对后续DeepSeek能跟上OpenAI保持谨慎乐观;
- 快速提升国内大模型的整体能力,因为开源,国内包括阿里、火山,以及其他的大模型公司全面拥抱DeepSeek,很多新的大模型会在DeepSeek-R1或其蒸馏版本上继续开发。
为什么最值得期待的不是成本
据说这是直接让英伟达股票大挫的原因,训练效率极大提升,卡就不需要那么多了。在国内的话,还有人在用PTX说事,说DeepSeek已经绕过了英伟达的CUDA框架。当然,这应该是没有的,一方面PTX也是英伟达的更底层的技术,另外一方面很多公司继续用英伟达的卡和CUDA框架复现了DeepSeek-R1的效果。但是在目前高性能卡禁售的情况下,这无疑是国人最喜闻乐见的突破,真有点看爽剧的效果。
但值得注意的是,不说细节,只从整个AI能力上限的探索来说,DeepSeek依然还是属于追赶者,不是探索者。探索者会面对很多待探索的工作,在成本上肯定会付出更多。看DeepSeek是否可以在2025年持续创新,特别是可以提高AI能力天花板,那才是真正的引领者。
2.企业可以得到什么好处
说了DeepSeek为什么火爆的原因之后,更应该理性来看这次DeepSeek的技术创新和突破可以为国内公司在AI应用上带来哪些好处。
2.1.信息获取方式大提升
DeepSeek-R1在用户使用界面上最让人印象深刻的是“深度思考”、“联网搜索”,以及展示思考的过程。在结果方面,用户可以说的更少,得到更多。如果您在工作中一直非常依赖搜索引擎,那么现在你可以改变自己的工作习惯了。可能你会逐渐发现,已经不需要通过关键词去寻找各类信息,然后自己去阅读理解和整理了,通过R1,也许可以将前面的“检索—阅读—摘要—汇总”的步骤转化为“提问—获得答案”就可以了。
可以联网搜索,可以自启发式地思考,可以去判断内容价值,可以进行最终推理总结甚至推断新的内容,这是接下来几年大模型发展的一个大趋势。包括OpenAI最新推出来的Deep Research,也是在强化这种信息获取的能力,可以高度自动化完成“信息采集—分析—整合”的工作。比如面对“过去10年中GDP排名前10的发达国家和前10的发展中国家的 iOS 和 Android 智能手机普及率,并要求将结果绘制成表格。”这种问题,如果是人工+搜索引擎的方式去处理,那会极其麻烦,没有几天完成不了,但Deep Research可以在10-20分钟内返回结果。
所以对于企业来说,员工去处理信息类问题的时候,效率将会大幅提升。另一方面,搜索引擎的使用可能会进一步被缩减。
2.2.蒸馏模型带来性能提升
私有化方案
在我们现有的客户中,大模型私有化的比例非常高,因为基本上都涉及到企业内部数据处理。我们定义的私有化也分为两种等级,一种是源文件私有化方案,另一种更普遍的是全量私有化。
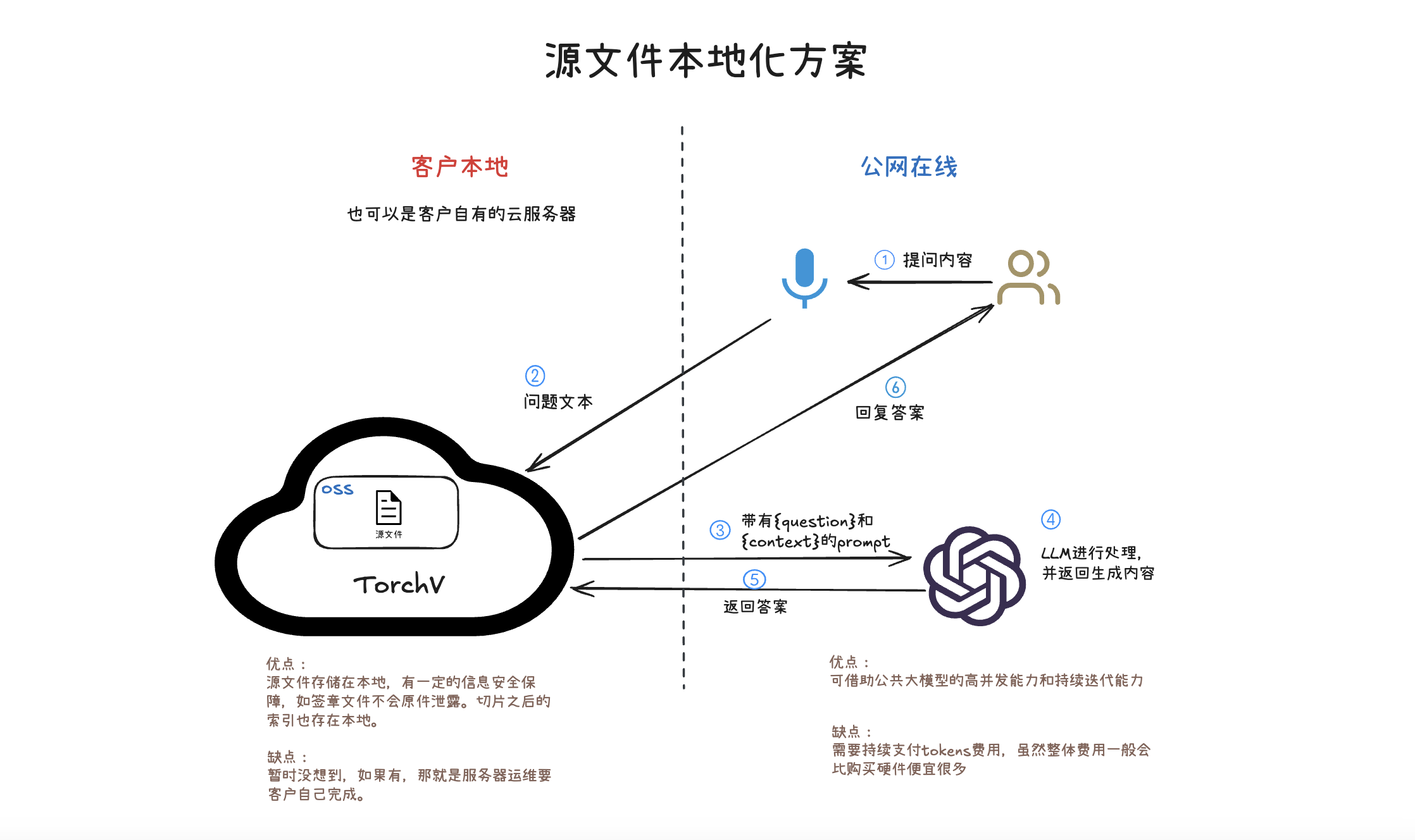
图:源文件本地化方案,大模型依然采用在线模型。
全量私有化的时候最纠结的就是部署怎样的大模型了,需要考量模型特性和业务特点是否匹配,需要平衡硬件成本和使用价值等各个方面。因为之前优秀的开源大模型较少,我们基本上给客户部署的都是Qwen系列的,包括7B、14B、32B和72B。一旦到32B、72B的参数体量,硬件要求就比较高了,下面放出一个局部的Nvidia L20硬件/Qwen模型的并发对比图(QPM为推算值):
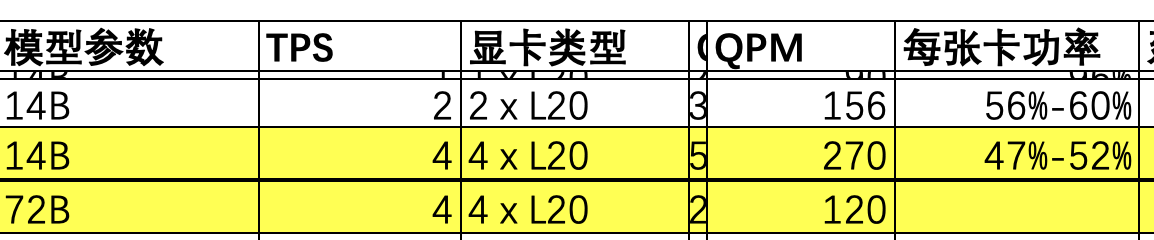
图:L20显卡和Qwen大模型的并发性能对照表(部分)
蒸馏模型能力大提升
所以这也一直是困扰我们的问题,我们当然希望推理模型可以更小、更强,还开源。这次的DeepSeek蒸馏模型刚好满足了这方面的需求,我们从DeepSeek和Qwen官方的Github/Huggingface上找到下面这两图,并制作成对比图:

图:DeepSeek-R1-Distill-Qwen-32B能力已经显著超越Qwen2.5-72B-Instruct
- DeepSeek-R1蒸馏过的Qwen2.5-32B大模型—DeepSeek-R1-Distill-Qwen-32B,其在各类测试中能力要明显强于Qwen最新的大模型QwQ-32B-Preview(参看上图左侧部分);
- 而千问自己提供的测试对照来看,QwQ-32B-Preview又比自家的Qwen2.5-72B-Instruct强出不少(看上图右侧部分);
- 间接可以得出,被DeepSeek-R1蒸馏过的DeepSeek-R1-Distill-Qwen-32B,能力上已经比Qwen2.5-72B-Instruct要高出很多了。
春节回来开工之后,已经有多个客户问是否可以给他们升级大模型,嗯,这是必须的!但我们要先内部试用一下,以免出现一些暂未发现的问题。
DeepSeek已经这么强了,为什么还要部署私有化模型?
最主要还是数据安全。
企业在业务运作上,肯定不仅仅只向外部求索,更多的还是基于企业内部数据进行业务处理,不希望自己的数据隐私被泄露,特别是关乎到财务、工艺、计划和合同等方面的内容。虽然上文中提到的源文件本地化方案可以在一定程度上保护客户数据安全,但是依然不能做到绝对安全,所以大模型私有化就成了一件非常重要的事情,Llama、Qwen和DeepSeek贡献巨大。
抛开2.1描述的对外信息获取这种方式,企业在内部AI使用中主要依赖的是AI应用。但要创造一个出色的AI应用需要具备以下条件:
- 能力:这里的能力指的就是AI能力,主要代表是大模型,还有配合大模型一起使用的RAG、微调等技术;
- 数据:特别在toB场景中,脱离自身业务数据(和知识)玩AI是没有太大意义的,我们需要借助AI处理的对象可能就是数据,又或者数据是可以将企业能力传承的数字基因;
- 逻辑:有了能力和数据之后,我们还需要针对业务逻辑进行应用创造(传统软件部分),逻辑可能来自于数据,如工艺流程,也可以是人类在执行并完成某项任务时的执行流程。
AI应用 = 能力 + 数据 + 逻辑。
3、企业如何更进一步拥抱AI
企业引入AI提升业务能力和效率已经是一个全民级别的共识了,特别DeepSeek这波所谓“国运级”的热度,更是起到了直接催化需求的效果。年后回来,我们和客户交流的过程中就发现,很多客户和潜在客户的高层负责人对AI的态度已经从谨慎、你们可以试试看,上升到企业要加快AI转型。那么企业如何更进一步拥抱AI呢?
从上一节的AI应用 = 能力 + 数据 + 逻辑展开来说,从我们服务的那些AI转型有所进展的客户经验来看,企业要成功把AI引入到业务中可能需要真正做好三件事,尤其是最后一件,非常重要!!!
3.1 业务逻辑
这是企业自身目前就已经具备的能力,但是企业也需要去收集AI转型需求,先从“一直想做但以前没办法做”、“效率一直被诟病,存在明显问题”的业务入手,配合使用部门挖掘需求。过程中可以和AI应用厂商一起讨论需求,优化业务逻辑,以匹配AI改造。
小结:企业内部人员本身是最了解业务逻辑的。
3.2 先从简单的AI应用开始
最简单的方式就是鼓励员工在日常工作中使用各类大模型,如DeepSeek、豆包、千问和Kimi等,直接在网页和APP上使用时免费的,培养全员的AI使用意识很重要。我们的理念一直都是人机共生,而不是机器直接替代人,要的是更高的效率,是能做以往做不了的事情。
当然,在企业层面,可以先尝试搭建大模型应用,最常见的包括知识问答、内容生成和分类归类等应用场景。只有内部先使用起来,各条业务线人员才能提出更准确的AI转型需求。
小结:先引入大模型能力,从简单场景开始,培养全员AI意识。
3.3 注重数据积累和知识管理
我们发现在AI大模型这一波转型升级进程中,原本就具备良好数据积累和知识管理能力的企业是非常有优势的,他们可以很快将AI应用的价值显现出来。而那些AI转型遇阻或者效果不佳的企业,其实也都有一些共性,比如没有数据规划和知识管理。数据方面常见的问题包括:
- 无积累:数据和知识(包括各类文档、纪要、产品说明、技术手册、项目过程文档,以及机器和系统产生的各类数据等等)规划缺失,使用过就丢弃,造成要使用数据的时候无处可寻,数据资产流失严重;
- 缺管理:数据和知识没有分类、归纳和标签等,很难找到数据(更多是知识)之间的关系,以及知识本身的说明(元数据);
- 没法汇聚:在AI应用中,数据和知识集中使用的效果肯定是最好的,比如进行embedding或者SFT等。但大多数企业其实很难将各部门的数据汇聚,因为害怕权限问题造成数据安全。
小结:没有数据积累和知识管理,企业AI转型会遇阻。
在这三件事中,对于企业来说最急迫的是要先把数据积累和知识管理做起来。这也是为什么我们在TorchV AI(大模型应用框架系统)之后把TorchV KB(大模型知识协作系统)作为第二款核心研发的产品。
本文不过多讨论TorchV KB,标准产品正在接近推出,预计3月初会正式发布在线试用系统,下面可以先简单一睹为快:
预览1:主要功能

预览2:页面编辑
预览3:管理后台【角色控制】

预览4::AI知识问答
4.最后
很开心看到DeepSeek这样的中国大模型公司达到顶尖水平,对于toB的AI应用来说更多的是福音,特别是性能更强的蒸馏(distill)模型的出现。但是企业的AI转型升级绝不是有更强的大模型就可以完成的,必须要注意数据积累和知识管理,才能让AI转型达到极高的成功率。
蛇年第一篇文章,感觉关注我的兄弟姐妹们,给大家拜个晚年,祝大家蛇年大吉!

