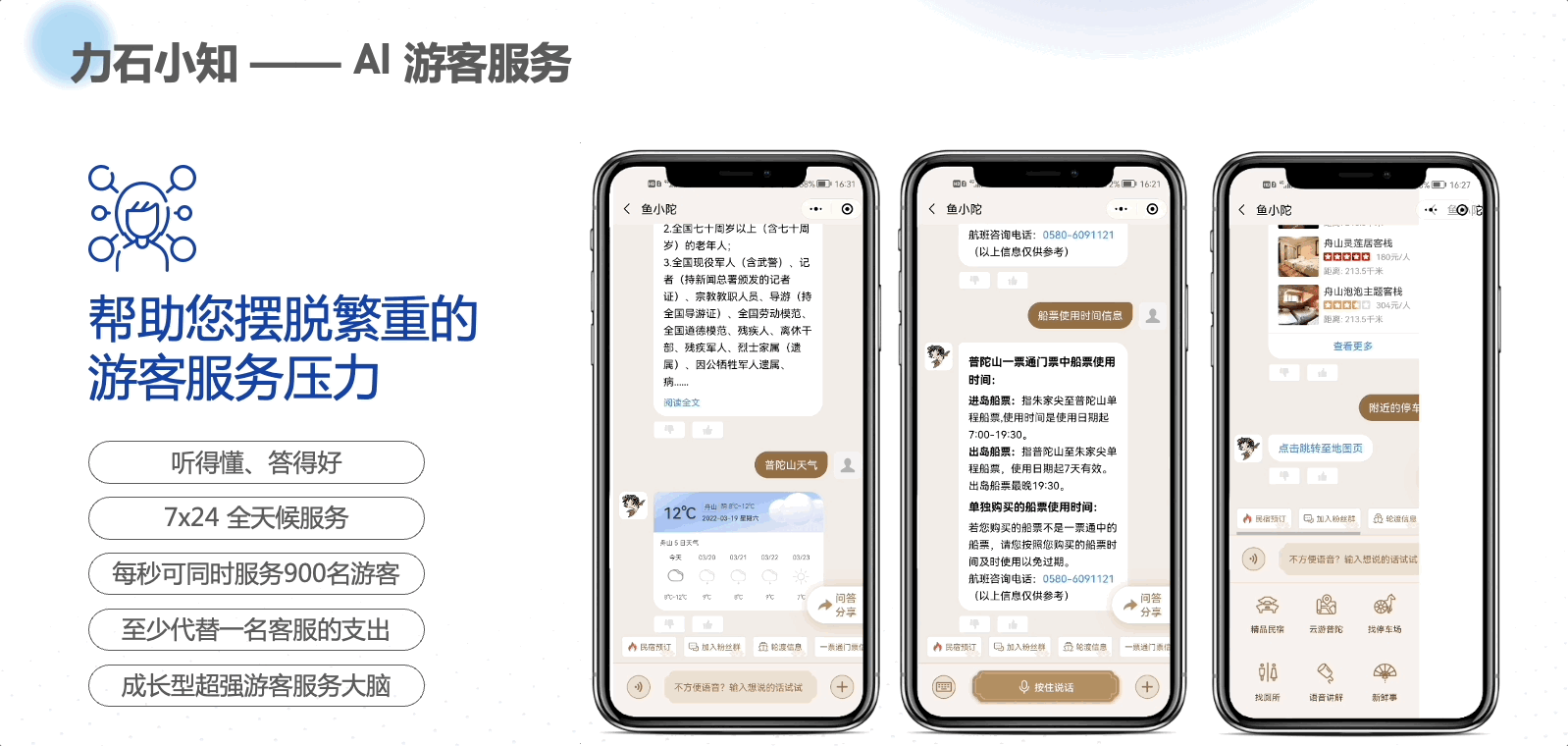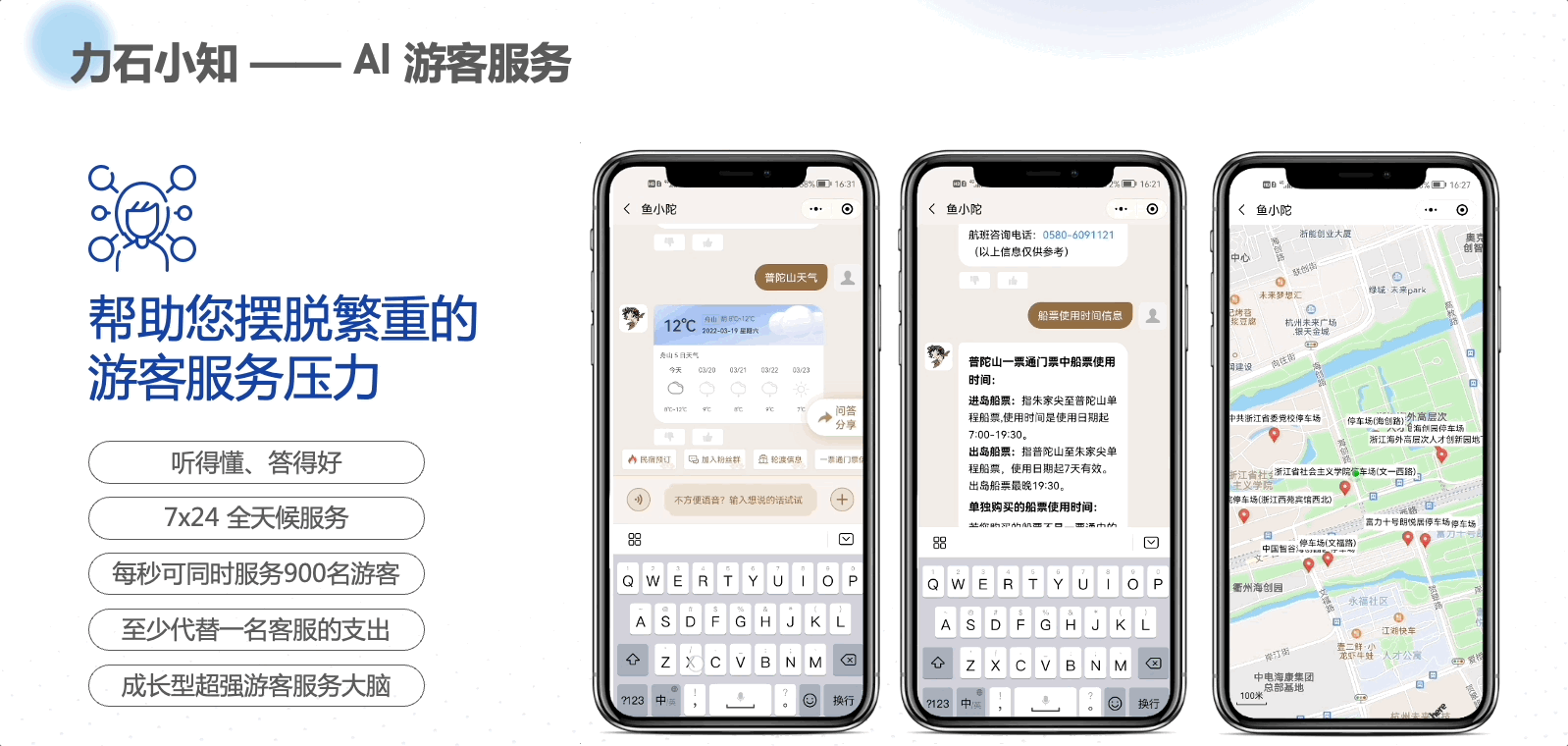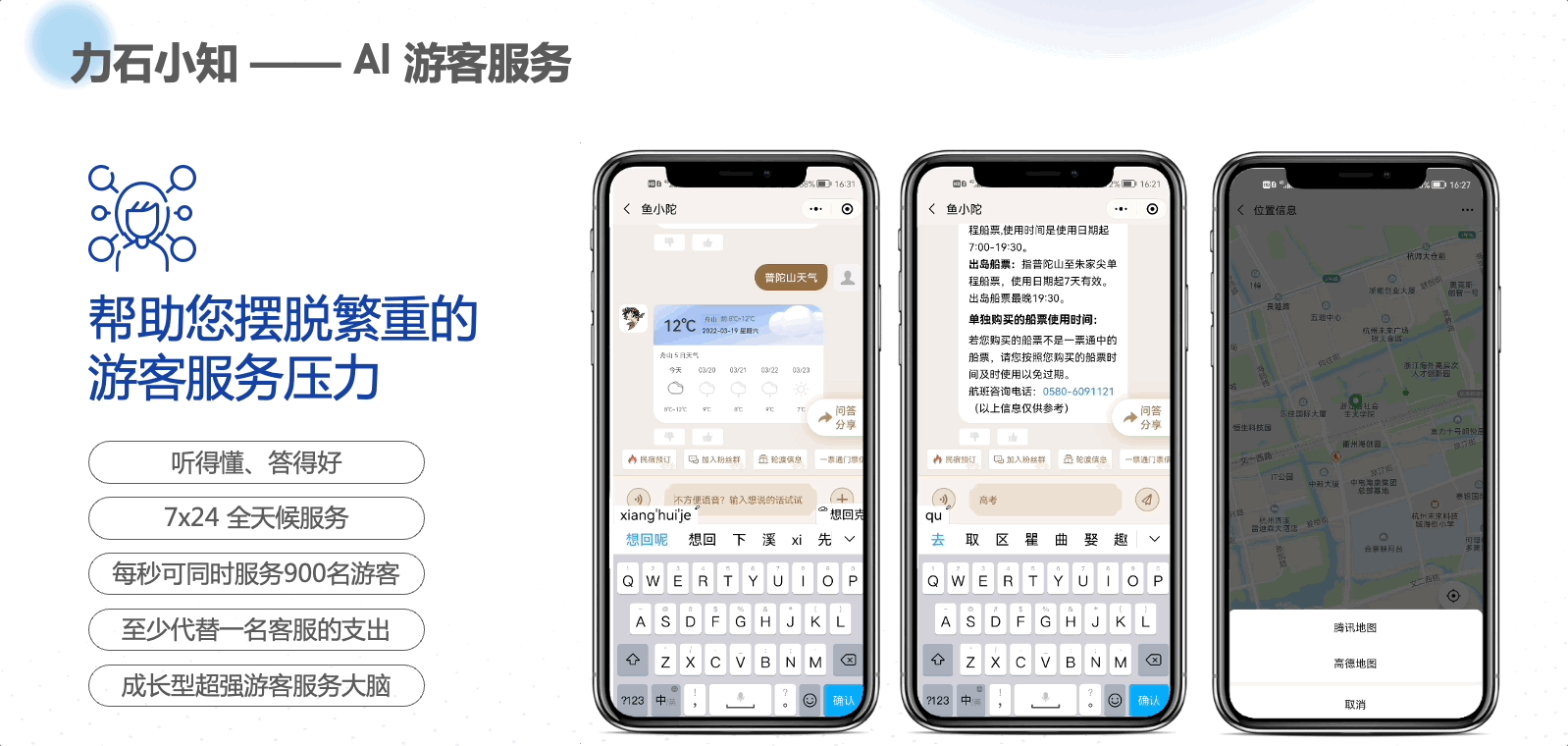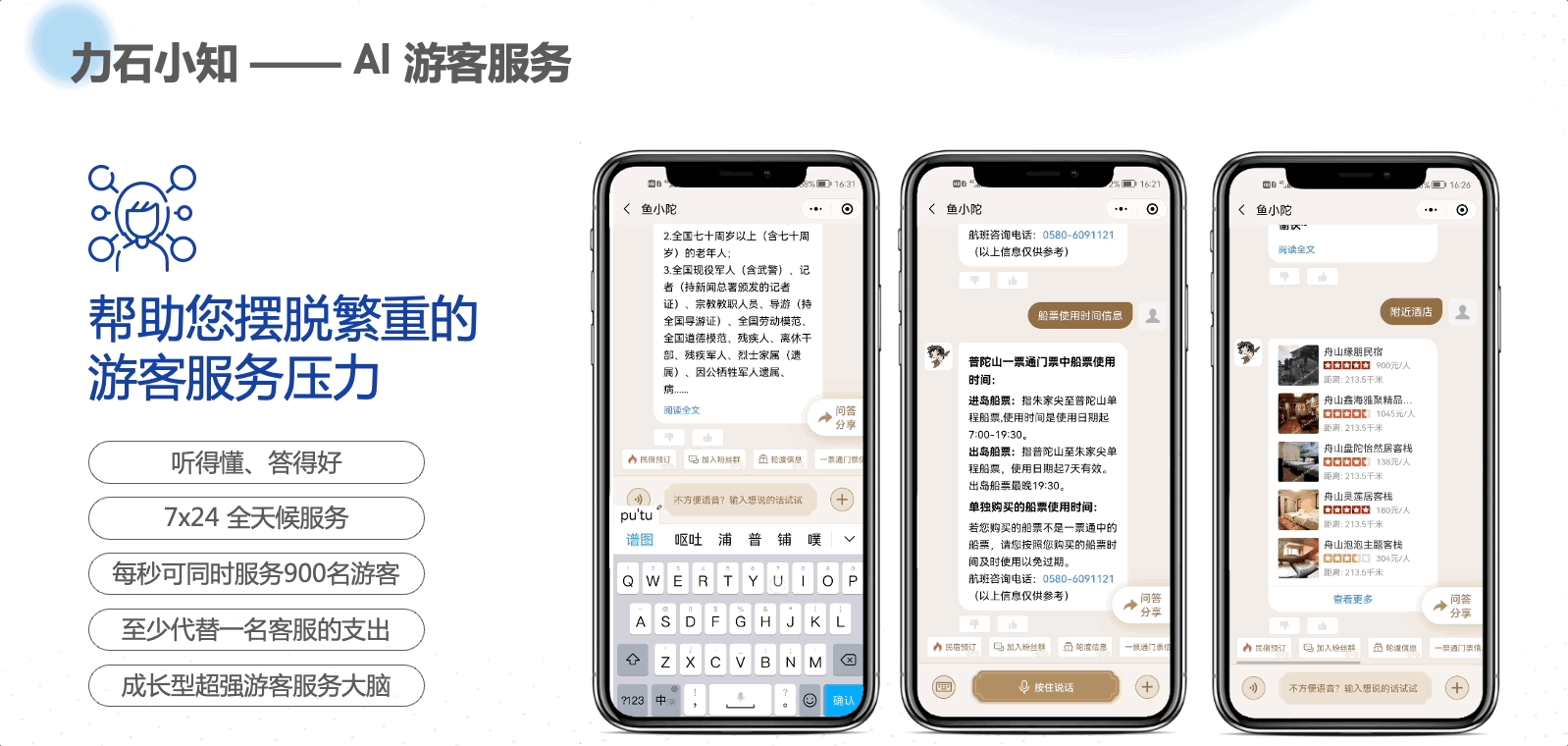
本文是根据《Effective Java 3rd》英文版翻译的,仅供自己学习用!
11. 重写equals方法时同时也要重写hashcode方法
在每个类中,在重写 equals 方法的时侯,一定要重写 hashcode 方法。如果不这样做,你的类违反了hashCode的通用约定,这会阻止它在HashMap和HashSet这样的集合中正常工作。根据 Object 规范,以下时具体约定。
- 当在一个应用程序执行过程中,如果在equals方法比较中没有修改任何信息,在一个对象上重复调用hashCode方法时,它必须始终返回相同的值。从一个应用程序到另一个应用程序的每一次执行返回的值可以是不一致的。
- 如果两个对象根据equals(Object)方法比较是相等的,那么在两个对象上调用hashCode就必须产生的结果是相同的整数。
- 如果两个对象根据equals(Object)方法比较并不相等,则不要求在每个对象上调用hashCode都必须产生不同的结果。 但是,程序员应该意识到,为不相等的对象生成不同的结果可能会提高散列表(hash tables)的性能。
当无法重写hashCode时,所违反第二个关键条款是:相等的对象必须具有相等的哈希码( hash codes)。根据类的equals方法,两个不同的实例可能在逻辑上是相同的,但是对于Object 类的hashCode方法,它们只是两个没有什么共同之处的对象。因此, Object 类的hashCode方法返回两个看似随机的数字,而不是按约定要求的两个相等的数字。
举例说明,假设你使用条目 10中的PhoneNumber类的实例做为HashMap的键(key):
1 | Map<PhoneNumber, String> m = new HashMap<>(); |
你可能期望m.get(new PhoneNumber(707, 867, 5309))方法返回Jenny字符串,但实际上,返回了 null。注意,这里涉及到两个PhoneNumber实例:一个实例插入到 HashMap 中,另一个作为判断相等的实例用来检索。PhoneNumber类没有重写 hashCode 方法导致两个相等的实例返回了不同的哈希码,违反了 hashCode 约定。put 方法把PhoneNumber实例保存在了一个哈希桶( hash bucket)中,但get方法却是从不同的哈希桶中去查找,即使恰好两个实例放在同一个哈希桶中,get 方法几乎肯定也会返回 null。因为HashMap 做了优化,缓存了与每一项(entry)相关的哈希码,如果哈希码不匹配,则不会检查对象是否相等了。
解决这个问题很简单,只需要为PhoneNumber类重写一个合适的 hashCode 方法。hashCode方法是什么样的?写一个不规范的方法的是很简单的。以下示例,虽然永远是合法的,但绝对不能这样使用:
1 | // The worst possible legal hashCode implementation - never use! |
这是合法的,因为它确保了相等的对象具有相同的哈希码。这很糟糕,因为它确保了每个对象都有相同的哈希码。因此,每个对象哈希到同一个桶中,哈希表退化为链表。应该在线性时间内运行的程序,运行时间变成了平方级别。对于数据很大的哈希表而言,会影响到能够正常工作。
一个好的 hash 方法趋向于为不相等的实例生成不相等的哈希码。这也正是 hashCode 约定中第三条的表达。理想情况下,hash 方法为集合中不相等的实例均匀地分配int 范围内的哈希码。实现这种理想情况可能是困难的。 幸运的是,要获得一个合理的近似的方式并不难。 以下是一个简单的配方:
声明一个 int 类型的变量result,并将其初始化为对象中第一个重要属性
c的哈希码,如下面步骤2.a中所计算的那样。(回顾条目10,重要的属性是影响比较相等的领域。)对于对象中剩余的重要属性
f,请执行以下操作:a. 比较属性
f与属性c的 int 类型的哈希码: – i. 如果这个属性是基本类型的,使用Type.hashCode(f)方法计算,其中Type类是对应属性 f 基本类型的包装类。 – ii 如果该属性是一个对象引用,并且该类的equals方法通过递归调用equals来比较该属性,并递归地调用hashCode方法。 如果需要更复杂的比较,则计算此字段的“范式(“canonical representation)”,并在范式上调用hashCode。 如果该字段的值为空,则使用0(也可以使用其他常数,但通常来使用0表示)。 – iii 如果属性f是一个数组,把它看作每个重要的元素都是一个独立的属性。 也就是说,通过递归地应用这些规则计算每个重要元素的哈希码,并且将每个步骤2.b的值合并。 如果数组没有重要的元素,则使用一个常量,最好不要为0。如果所有元素都很重要,则使用Arrays.hashCode方法。b. 将步骤2.a中属性
c计算出的哈希码合并为如下结果:result = 31 * result + c;返回 result 值。
当你写完hashCode方法后,问自己是否相等的实例有相同的哈希码。 编写单元测试来验证你的直觉(除非你使用AutoValue框架来生成你的equals和hashCode方法,在这种情况下,你可以放心地忽略这些测试)。 如果相同的实例有不相等的哈希码,找出原因并解决问题。
可以从哈希码计算中排除派生属性(derived fields)。换句话说,如果一个属性的值可以根据参与计算的其他属性值计算出来,那么可以忽略这样的属性。您必须排除在equals比较中没有使用的任何属性,否则可能会违反hashCode约定的第二条。
步骤2.b中的乘法计算结果取决于属性的顺序,如果类中具有多个相似属性,则产生更好的散列函数。 例如,如果乘法计算从一个String散列函数中被省略,则所有的字符将具有相同的散列码。 之所以选择31,因为它是一个奇数的素数。 如果它是偶数,并且乘法溢出,信息将会丢失,因为乘以2相当于移位。 使用素数的好处不太明显,但习惯上都是这么做的。 31的一个很好的特性,是在一些体系结构中乘法可以被替换为移位和减法以获得更好的性能:31 * i ==(i << 5) - i。 现代JVM可以自动进行这种优化。
让我们把上述办法应用到PhoneNumber类中:
1 | // Typical hashCode method |
因为这个方法返回一个简单的确定性计算的结果,它的唯一的输入是PhoneNumber实例中的三个重要的属性,所以显然相等的PhoneNumber实例具有相同的哈希码。 实际上,这个方法是PhoneNumber的一个非常好的hashCode实现,与Java平台类库中的实现一样。 它很简单,速度相当快,并且合理地将不相同的电话号码分散到不同的哈希桶中。
虽然在这个项目的方法产生相当好的哈希函数,但并不是最先进的。 它们的质量与Java平台类库的值类型中找到的哈希函数相当,对于大多数用途来说都是足够的。 如果真的需要哈希函数而不太可能产生碰撞,请参阅Guava框架的的com.google.common.hash.Hashing [Guava]方法。
Objects类有一个静态方法,它接受任意数量的对象并为它们返回一个哈希码。 这个名为hash的方法可以让你编写一行hashCode方法,其质量与根据这个项目中的上面编写的方法相当。 不幸的是,它们的运行速度更慢,因为它们需要创建数组以传递可变数量的参数,以及如果任何参数是基本类型,则进行装箱和取消装箱。 这种哈希函数的风格建议仅在性能不重要的情况下使用。 以下是使用这种技术编写的PhoneNumber的哈希函数:
1 | // One-line hashCode method - mediocre performance |
如果一个类是不可变的,并且计算哈希码的代价很大,那么可以考虑在对象中缓存哈希码,而不是在每次请求时重新计算哈希码。 如果你认为这种类型的大多数对象将被用作哈希键,那么应该在创建实例时计算哈希码。 否则,可以选择在首次调用hashCode时延迟初始化(lazily initialize)哈希码。 需要注意确保类在存在延迟初始化属性的情况下保持线程安全(项目83)。 PhoneNumber类不适合这种情况,但只是为了展示它是如何完成的。 请注意,属性hashCode的初始值(在本例中为0)不应该是通常创建的实例的哈希码:
1 | // hashCode method with lazily initialized cached hash code |
不要试图从哈希码计算中排除重要的属性来提高性能。 由此产生的哈希函数可能运行得更快,但其质量较差可能会降低哈希表的性能,使其无法使用。 具体来说,哈希函数可能会遇到大量不同的实例,这些实例主要在你忽略的区域中有所不同。 如果发生这种情况,哈希函数将把所有这些实例映射到少许哈希码上,而应该以线性时间运行的程序将会运行平方级的时间。
这不仅仅是一个理论问题。 在Java 2之前,String 类哈希函数在整个字符串中最多使用16个字符,从第一个字符开始,在整个字符串中均匀地选取。 对于大量的带有层次名称的集合(如URL),此功能正好显示了前面描述的病态行为。
不要为hashCode返回的值提供详细的规范,因此客户端不能合理地依赖它; 你可以改变它的灵活性。 Java类库中的许多类(例如String和Integer)都将hashCode方法返回的确切值指定为实例值的函数。 这不是一个好主意,而是一个我们不得不忍受的错误:它妨碍了在未来版本中改进哈希函数的能力。 如果未指定细节并在散列函数中发现缺陷,或者发现了更好的哈希函数,则可以在后续版本中对其进行更改。
总之,每次重写equals方法时都必须重写hashCode方法,否则程序将无法正常运行。你的hashCode方法必须遵从Object类指定的常规约定,并且必须执行合理的工作,将不相等的哈希码分配给不相等的实例。如果使用第51页的配方,这很容易实现。如条目 10所述,AutoValue框架为手动编写equals和hashCode方法提供了一个很好的选择,IDE也提供了一些这样的功能。
12. 始终重写 toString 方法
虽然Object类提供了toString方法的实现,但它返回的字符串通常不是你的类的用户想要看到的。 它由类名后跟一个“at”符号(@)和哈希码的无符号十六进制表示组成,例如PhoneNumber@163b91。 toString的通用约定要求,返回的字符串应该是“一个简洁但内容丰富的表示,对人们来说是很容易阅读的”。虽然可以认为PhoneNumber@163b91简洁易读,但相比于707-867-5309,但并不是很丰富 。 toString通用约定“建议所有的子类重写这个方法”。好的建议,的确如此!
虽然它并不像遵守equals和hashCode约定那样重要(条目 10和11),但是提供一个良好的toString实现使你的类更易于使用,并对使用此类的系统更易于调试。当对象被传递到println、printf、字符串连接操作符或断言,或者由调试器打印时,toString方法会自动被调用。即使你从不调用对象上的toString,其他人也可以。例如,对对象有引用的组件可能包含在日志错误消息中对象的字符串表示。如果未能重写toString,则消息可能是无用的。
如果为PhoneNumber提供了一个很好的toString方法,那么生成一个有用的诊断消息就像下面这样简单:
1 | System.out.println("Failed to connect to " + phoneNumber); |
程序员将以这种方式生成诊断消息,不管你是否重写toString,但是除非你这样做,否则这些消息将不会有用。 提供一个很好的toString方法的好处不仅包括类的实例,同样有益于包含实例引用的对象,特别是集合。 打印map 对象时你会看到哪一个,{Jenny=PhoneNumber@163b91}还是{Jenny=707-867-5309}?
实际上,toString方法应该返回对象中包含的所有需要关注的信息,如电话号码示例中所示。 如果对象很大或者包含不利于字符串表示的状态,这是不切实际的。 在这种情况下,toString应该返回一个摘要,如 Manhattan residential phone directory (1487536 listings)或线程[main,5,main]。 理想情况下,字符串应该是不言自明的(线程示例并没有遵守这点)。 如果未能将所有对象的值得关注的信息包含在字符串表示中,则会导致一个特别烦人的处罚:测试失败报告如下所示:
1 | Assertion failure: expected {abc, 123}, but was {abc, 123}. |
实现toString方法时,必须做出的一个重要决定是:在文档中指定返回值的格式。 建议你对值类进行此操作,例如电话号码或矩阵类。 指定格式的好处是它可以作为标准的,明确的,可读的对象表示。 这种表示形式可以用于输入、输出以及持久化可读性的数据对象,如CSV文件。 如果指定了格式,通常提供一个匹配的静态工厂或构造方法,是个好主意,所以程序员可以轻松地在对象和字符串表示之间来回转换。 Java平台类库中的许多值类都采用了这种方法,包括BigInteger,BigDecimal和大部分基本类型包装类。
指定toString返回值的格式的缺点是,假设你的类被广泛使用,一旦指定了格式,就会终身使用。程序员将编写代码来解析表达式,生成它,并将其嵌入到持久数据中。如果在将来的版本中更改了格式的表示,那么会破坏他们的代码和数据,并且还会抱怨。但通过选择不指定格式,就可以保留在后续版本中添加信息或改进格式的灵活性。
无论是否决定指定格式,你都应该清楚地在文档中表明你的意图。如果指定了格式,则应该这样做。例如,这里有一个toString方法,该方法在条目 11中使用PhoneNumber类:
1 | /** |
如果你决定不指定格式,那么文档注释应该是这样的:
1 | /** |
在阅读了这条注释之后,那些生成依赖于格式细节的代码或持久化数据的程序员,在这种格式发生改变的时候,只能怪他们自己。
无论是否指定格式,都可以通过编程方式访问toString返回的值中包含的信息。 例如,PhoneNumber类应该包含 areaCode, prefix, lineNum这三个属性。 如果不这样做,就会强迫程序员需要这些信息来解析字符串。 除了降低性能和程序员做不必要的工作之外,这个过程很容易出错,如果改变格式就会中断,并导致脆弱的系统。 由于未能提供访问器,即使已指定格式可能会更改,也可以将字符串格式转换为事实上的API。
在静态工具类(条目 4)中编写toString方法是没有意义的。 你也不应该在大多数枚举类型(条目 34)中写一个toString方法,因为Java为你提供了一个非常好的方法。 但是,你应该在任何抽象类中定义toString方法,该类的子类共享一个公共字符串表示形式。 例如,大多数集合实现上的toString方法都是从抽象集合类继承的。
Google的开放源代码AutoValue工具在条目 10中讨论过,它为你生成一个toString方法,就像大多数IDE工具一样。 这些方法非常适合告诉你每个属性的内容,但并不是专门针对类的含义。 因此,例如,为我们的PhoneNumber类使用自动生成的toString方法是不合适的(因为电话号码具有标准的字符串表示形式),但是对于我们的Potion类来说,这是完全可以接受的。 也就是说,自动生成的toString方法比从Object继承的方法要好得多,它不会告诉你对象的值。
回顾一下,除非父类已经这样做了,否则在每个实例化的类中重写Object的toString实现。 它使得类更加舒适地使用和协助调试。 toString方法应该以一种美观的格式返回对象的简明有用的描述。
13. 谨慎地重写 clone 方法
Cloneable接口的目的是作为一个mixin接口(条目 20),公布这样的类允许克隆。不幸的是,它没有达到这个目的。它的主要缺点是缺少clone方法,而Object的clone方法是受保护的。你不能,不借助反射(条目 65),仅仅因为它实现了Cloneable接口,就调用对象上的 clone 方法。即使是反射调用也可能失败,因为不能保证对象具有可访问的 clone方法。尽管存在许多缺陷,该机制在合理的范围内使用,所以理解它是值得的。这个条目告诉你如何实现一个行为良好的 clone方法,在适当的时候讨论这个方法,并提出替代方案。
既然Cloneable接口不包含任何方法,那它用来做什么? 它决定了Object的受保护的clone 方法实现的行为:如果一个类实现了Cloneable接口,那么Object的clone方法将返回该对象的逐个属性(field-by-field)拷贝;否则会抛出CloneNotSupportedException异常。这是一个非常反常的接口使用,而不应该被效仿。 通常情况下,实现一个接口用来表示可以为客户做什么。但对于Cloneable接口,它会修改父类上受保护方法的行为。
虽然规范并没有说明,但在实践中,实现Cloneable接口的类希望提供一个正常运行的公共 clone方法。为了实现这一目标,该类及其所有父类必须遵循一个复杂的、不可执行的、稀疏的文档协议。由此产生的机制是脆弱的、危险的和不受语言影响的(extralinguistic):它创建对象而不需要调用构造方法。
clone方法的通用规范很薄弱的。 以下内容是从 Object 规范中复制出来的:
创建并返回此对象的副本。 “复制(copy)”的确切含义可能取决于对象的类。 一般意图是,对于任何对象x,表达式x.clone() != x返回 true,并且x.clone().getClass() == x.getClass()也返回 true,但它们不是绝对的要求,但通常情况下,x.clone().equals(x)返回 true,当然这个要求也不是绝对的。
根据约定,这个方法返回的对象应该通过调用super.clone方法获得的。 如果一个类和它的所有父类(Object除外)都遵守这个约定,情况就是如此,x.clone().getClass() == x.getClass()。
根据约定,返回的对象应该独立于被克隆的对象。 为了实现这种独立性,在返回对象之前,可能需要修改由super.clone返回的对象的一个或多个属性。
这种机制与构造方法链(chaining)很相似,只是它没有被强制执行;如果一个类的clone方法返回一个通过调用构造方法获得而不是通过调用super.clone的实例,那么编译器不会抱怨,但是如果一个类的子类调用了super.clone,那么返回的对象包含错误的类,从而阻止子类 clone 方法正常执行。如果一个类重写的 clone 方法是有 final 修饰的,那么这个约定可以被安全地忽略,因为子类不需要担心。但是,如果一个final类有一个不调用super.clone的clone方法,那么这个类没有理由实现Cloneable接口,因为它不依赖于Object的clone实现的行为。
假设你希望在一个类中实现Cloneable接口,它的父类提供了一个行为良好的 clone方法。首先调用super.clone。 得到的对象将是原始的完全功能的复制品。 在你的类中声明的任何属性将具有与原始属性相同的值。 如果每个属性包含原始值或对不可变对象的引用,则返回的对象可能正是你所需要的,在这种情况下,不需要进一步的处理。 例如,对于条目 11中的PhoneNumber类,情况就是这样,但是请注意,不可变类永远不应该提供clone方法,因为这只会浪费复制。 有了这个警告,以下是PhoneNumber类的clone方法:
1 | // Clone method for class with no references to mutable state |
为了使这个方法起作用,PhoneNumber的类声明必须被修改,以表明它实现了Cloneable接口。 虽然Object类的clone方法返回Object类,但是这个clone方法返回PhoneNumber类。 这样做是合法和可取的,因为Java支持协变返回类型。 换句话说,重写方法的返回类型可以是重写方法的返回类型的子类。 这消除了在客户端转换的需要。 在返回之前,我们必须将Object的super.clone的结果强制转换为PhoneNumber,但保证强制转换成功。
super.clone的调用包含在一个try-catch块中。 这是因为Object声明了它的clone方法来抛出CloneNotSupportedException异常,这是一个检查时异常。 由于PhoneNumber实现了Cloneable接口,所以我们知道调用super.clone会成功。 这里引用的需要表明CloneNotSupportedException应该是未被检查的(条目 71)。
如果对象包含引用可变对象的属性,则前面显示的简单clone实现可能是灾难性的。 例如,考虑条目 7中的Stack类:
1 | public class Stack { |
假设你想让这个类可以克隆。 如果clone方法仅返回super.clone()调用的对象,那么生成的Stack实例在其size 属性中具有正确的值,但elements属性引用与原始Stack实例相同的数组。 修改原始实例将破坏克隆中的不变量,反之亦然。 你会很快发现你的程序产生了无意义的结果,或者抛出NullPointerException异常。
这种情况永远不会发生,因为调用Stack类中的唯一构造方法。 实际上,clone方法作为另一种构造方法; 必须确保它不会损坏原始对象,并且可以在克隆上正确建立不变量。 为了使Stack上的clone方法正常工作,它必须复制stack 对象的内部。 最简单的方法是对元素数组递归调用clone方法:
1 | // Clone method for class with references to mutable state |
请注意,我们不必将elements.clone的结果转换为Object[]数组。 在数组上调用clone会返回一个数组,其运行时和编译时类型与被克隆的数组相同。 这是复制数组的首选习语。 事实上,数组是clone 机制的唯一有力的用途。
还要注意,如果elements属性是final的,则以前的解决方案将不起作用,因为克隆将被禁止向该属性分配新的值。 这是一个基本的问题:像序列化一样,Cloneable体系结构与引用可变对象的final 属性的正常使用不兼容,除非可变对象可以在对象和其克隆之间安全地共享。 为了使一个类可以克隆,可能需要从一些属性中移除 final修饰符。
仅仅递归地调用clone方法并不总是足够的。 例如,假设您正在为哈希表编写一个clone方法,其内部包含一个哈希桶数组,每个哈希桶都指向“键-值”对链表的第一项。 为了提高性能,该类实现了自己的轻量级单链表,而没有使用java内部提供的java.util.LinkedList:
1 | public class HashTable implements Cloneable { |
假设你只是递归地克隆哈希桶数组,就像我们为Stack所做的那样:
1 | // Broken clone method - results in shared mutable state! |
虽然被克隆的对象有自己的哈希桶数组,但是这个数组引用与原始数组相同的链表,这很容易导致克隆对象和原始对象中的不确定性行为。 要解决这个问题,你必须复制包含每个桶的链表。 下面是一种常见的方法:
1 | // Recursive clone method for class with complex mutable state |
私有类HashTable.Entry已被扩充以支持“深度复制”方法。 HashTable上的clone方法分配一个合适大小的新哈希桶数组,迭代原来哈希桶数组,深度复制每个非空的哈希桶。 Entry上的deepCopy方法递归地调用它自己以复制由头节点开始的整个链表。 如果哈希桶不是太长,这种技术很聪明并且工作正常。但是,克隆链表不是一个好方法,因为它为列表中的每个元素消耗一个栈帧(stack frame)。 如果列表很长,这很容易导致堆栈溢出。 为了防止这种情况发生,可以用迭代来替换deepCopy中的递归:
1 | // Iteratively copy the linked list headed by this Entry |
克隆复杂可变对象的最后一种方法是调用super.clone,将结果对象中的所有属性设置为其初始状态,然后调用更高级别的方法来重新生成原始对象的状态。 以HashTable为例,bucket属性将被初始化为一个新的bucket数组,并且 put(key, value)方法(未示出)被调用用于被克隆的哈希表中的键值映射。 这种方法通常产生一个简单,合理的优雅clone方法,其运行速度不如直接操纵克隆内部的方法快。 虽然这种方法是干净的,但它与整个Cloneable体系结构是对立的,因为它会盲目地重写构成体系结构基础的逐个属性对象复制。
与构造方法一样,clone 方法绝对不可以在构建过程中,调用一个可以重写的方法(条目 19)。如果 clone 方法调用一个在子类中重写的方法,则在子类有机会在克隆中修复它的状态之前执行该方法,很可能导致克隆和原始对象的损坏。因此,我们在前面讨论的 put(key, value)方法应该时 final 或 private 修饰的。(如果时 private 修饰,那么大概是一个非 final 公共方法的辅助方法)。
Object 类的 clone方法被声明为抛出CloneNotSupportedException异常,但重写方法时不需要。 公共clone方法应该省略throws子句,因为不抛出检查时异常的方法更容易使用(条目 71)。
在为继承设计一个类时(条目 19),通常有两种选择,但无论选择哪一种,都不应该实现 Clonable 接口。你可以选择通过实现正确运行的受保护的 clone方法来模仿Object的行为,该方法声明为抛出CloneNotSupportedException异常。 这给了子类实现Cloneable接口的自由,就像直接继承Object一样。 或者,可以选择不实现工作的 clone方法,并通过提供以下简并clone实现来阻止子类实现它:
1 | // clone method for extendable class not supporting Cloneable |
还有一个值得注意的细节。 如果你编写一个实现了Cloneable的线程安全的类,记得它的clone方法必须和其他方法一样(条目 78)需要正确的同步。 Object 类的clone方法是不同步的,所以即使它的实现是令人满意的,也可能需要编写一个返回super.clone()的同步clone方法。
回顾一下,实现Cloneable的所有类应该重写公共clone方法,而这个方法的返回类型是类本身。 这个方法应该首先调用super.clone,然后修复任何需要修复的属性。 通常,这意味着复制任何包含内部“深层结构”的可变对象,并用指向新对象的引用来代替原来指向这些对象的引用。虽然这些内部拷贝通常可以通过递归调用clone来实现,但这并不总是最好的方法。 如果类只包含基本类型或对不可变对象的引用,那么很可能是没有属性需要修复的情况。 这个规则也有例外。 例如,表示序列号或其他唯一ID的属性即使是基本类型的或不可变的,也需要被修正。
这么复杂是否真的有必要?很少。 如果你继承一个已经实现了Cloneable接口的类,你别无选择,只能实现一个行为良好的clone方法。 否则,通常你最好提供另一种对象复制方法。 对象复制更好的方法是提供一个复制构造方法或复制工厂。 复制构造方法接受参数,其类型为包含此构造方法的类,例如,
1 | // Copy constructor |
复制工厂类似于复制构造方法的静态工厂:
1 | // Copy factory |
复制构造方法及其静态工厂变体与Cloneable/clone相比有许多优点:它们不依赖风险很大的语言外的对象创建机制;不要求遵守那些不太明确的惯例;不会与final 属性的正确使用相冲突; 不会抛出不必要的检查异常; 而且不需要类型转换。
此外,复制构造方法或复制工厂可以接受类型为该类实现的接口的参数。 例如,按照惯例,所有通用集合实现都提供了一个构造方法,其参数的类型为Collection或Map。 基于接口的复制构造方法和复制工厂(更适当地称为转换构造方法和转换工厂)允许客户端选择复制的实现类型,而不是强制客户端接受原始实现类型。 例如,假设你有一个HashSet,并且你想把它复制为一个TreeSet。 clone方法不能提供这种功能,但使用转换构造方法很容易:new TreeSet<>(s)。
考虑到与Cloneable接口相关的所有问题,新的接口不应该继承它,新的可扩展类不应该实现它。 虽然实现Cloneable接口对于final类没有什么危害,但应该将其视为性能优化的角度,仅在极少数情况下才是合理的(条目67)。 通常,复制功能最好由构造方法或工厂提供。 这个规则的一个明显的例外是数组,它最好用 clone方法复制。
14.考虑实现Comparable接口
与本章讨论的其他方法不同,compareTo方法并没有在Object类中声明。 相反,它是Comparable接口中的唯一方法。 它与Object类的equals方法在性质上是相似的,除了它允许在简单的相等比较之外的顺序比较,它是泛型的。 通过实现Comparable接口,一个类表明它的实例有一个自然顺序( natural ordering)。 对实现Comparable接口的对象数组排序非常简单,如下所示:
1 | Arrays.sort(a); |
它很容易查找,计算极端数值,以及维护Comparable对象集合的自动排序。例如,在下面的代码中,依赖于String类实现了Comparable接口,去除命令行参数输入重复的字符串,并按照字母顺序排序:
1 | public class WordList { |
通过实现Comparable接口,可以让你的类与所有依赖此接口的通用算法和集合实现进行互操作。 只需少量的努力就可以获得巨大的能量。 几乎Java平台类库中的所有值类以及所有枚举类型(条目 34)都实现了Comparable接口。 如果你正在编写具有明显自然顺序(如字母顺序,数字顺序或时间顺序)的值类,则应该实现Comparable接口:
1 | public interface Comparable<T> { |
compareTo方法的通用约定与equals相似:
将此对象与指定的对象按照排序进行比较。 返回值可能为负整数,零或正整数,因为此对象对应小于,等于或大于指定的对象。 如果指定对象的类型与此对象不能进行比较,则引发ClassCastException异常。
下面的描述中,符号sgn(expression)表示数学中的 signum 函数,它根据表达式的值为负数、零、正数,对应返回-1、0和1。
- 实现类必须确保所有
x和y都满足sgn(x.compareTo(y)) == -sgn(y. compareTo(x))。 (这意味着当且仅当y.compareTo(x)抛出异常时,x.compareTo(y)必须抛出异常。) - 实现类还必须确保该关系是可传递的:
(x. compareTo(y) > 0 && y.compareTo(z) > 0)意味着x.compareTo(z) > 0。 - 最后,对于所有的z,实现类必须确保
[x.compareTo(y) == 0意味着sgn(x.compareTo(z)) == sgn(y.compareTo(z))。 - 强烈推荐
x.compareTo(y) == 0) == (x.equals(y)),但不是必需的。 一般来说,任何实现了Comparable接口的类违反了这个条件都应该清楚地说明这个事实。 推荐的语言是“注意:这个类有一个自然顺序,与equals不一致”。
与equals方法一样,不要被上述约定的数学特性所退缩。这个约定并不像看起来那么复杂。 与equals方法不同,equals方法在所有对象上施加了全局等价关系,compareTo不必跨越不同类型的对象:当遇到不同类型的对象时,compareTo被允许抛出ClassCastException异常。 通常,这正是它所做的。 约定确实允许进行不同类型间比较,这种比较通常在由被比较的对象实现的接口中定义。
正如一个违反hashCode约定的类可能会破坏依赖于哈希的其他类一样,违反compareTo约定的类可能会破坏依赖于比较的其他类。 依赖于比较的类,包括排序后的集合TreeSet和TreeMap类,以及包含搜索和排序算法的实用程序类Collections和Arrays。
我们来看看compareTo约定的规定。 第一条规定,如果反转两个对象引用之间的比较方向,则会发生预期的事情:如果第一个对象小于第二个对象,那么第二个对象必须大于第一个; 如果第一个对象等于第二个,那么第二个对象必须等于第一个; 如果第一个对象大于第二个,那么第二个必须小于第一个。 第二项约定说,如果一个对象大于第二个对象,而第二个对象大于第三个对象,则第一个对象必须大于第三个对象。 最后一条规定,所有比较相等的对象与任何其他对象相比,都必须得到相同的结果。
这三条规定的一个结果是,compareTo方法所实施的平等测试必须遵守equals方法约定所施加的相同限制:自反性,对称性和传递性。 因此,同样需要注意的是:除非你愿意放弃面向对象抽象(条目 10)的好处,否则无法在保留compareTo约定的情况下使用新的值组件继承可实例化的类。 同样的解决方法也适用。 如果要将值组件添加到实现Comparable的类中,请不要继承它;编写一个包含第一个类实例的不相关的类。 然后提供一个返回包含实例的“视图”方法。 这使你可以在包含类上实现任何compareTo方法,同时客户端在需要时,把包含类的实例视同以一个类的实例。
compareTo约定的最后一段是一个强烈的建议,而不是一个真正的要求,只是声明compareTo方法施加的相等性测试,通常应该返回与equals方法相同的结果。 如果遵守这个约定,则compareTo方法施加的顺序被认为与equals相一致。 如果违反,顺序关系被认为与equals不一致。 其compareTo方法施加与equals不一致顺序关系的类仍然有效,但包含该类元素的有序集合可能不服从相应集合接口(Collection,Set或Map)的一般约定。 这是因为这些接口的通用约定是用equals方法定义的,但是排序后的集合使用compareTo强加的相等性测试来代替equals。 如果发生这种情况,虽然不是一场灾难,但仍是一件值得注意的事情。
例如,考虑BigDecimal类,其compareTo方法与equals不一致。 如果你创建一个空的HashSet实例,然后添加new BigDecimal("1.0")和new BigDecimal("1.00"),则该集合将包含两个元素,因为与equals方法进行比较时,添加到集合的两个BigDecimal实例是不相等的。 但是,如果使用TreeSet而不是HashSet执行相同的过程,则该集合将只包含一个元素,因为使用compareTo方法进行比较时,两个BigDecimal实例是相等的。 (有关详细信息,请参阅BigDecimal文档。)
编写compareTo方法与编写equals方法类似,但是有一些关键的区别。 因为Comparable接口是参数化的,compareTo方法是静态类型的,所以你不需要输入检查或者转换它的参数。 如果参数是错误的类型,那么调用将不会编译。 如果参数为null,则调用应该抛出一个NullPointerException异常,并且一旦该方法尝试访问其成员,它就会立即抛出这个异常。
在compareTo方法中,比较属性的顺序而不是相等。 要比较对象引用属性,请递归调用compareTo方法。 如果一个属性没有实现Comparable,或者你需要一个非标准的顺序,那么使用Comparator接口。 可以编写自己的比较器或使用现有的比较器,如在条目 10中的CaseInsensitiveString类的compareTo方法中:
1 | // Single-field Comparable with object reference field |
请注意,CaseInsensitiveString类实现了Comparable <CaseInsensitiveString>接口。 这意味着CaseInsensitiveString引用只能与另一个CaseInsensitiveString引用进行比较。 当声明一个类来实现Comparable接口时,这是正常模式。
在本书第二版中,曾经推荐如果比较整型基本类型的属性,使用关系运算符“<” 和 “>”,对于浮点类型基本类型的属性,使用Double.compare和[Float.compare静态方法。在Java 7中,静态比较方法被添加到Java的所有包装类中。 在compareTo方法中使用关系运算符“<” 和“>”是冗长且容易出错的,不再推荐。
如果一个类有多个重要的属性,那么比较他们的顺序是至关重要的。 从最重要的属性开始,逐步比较所有的重要属性。 如果比较结果不是零(零表示相等),则表示比较完成; 只是返回结果。 如果最重要的字段是相等的,比较下一个重要的属性,依此类推,直到找到不相等的属性或比较剩余不那么重要的属性。 以下是条目 11中PhoneNumber类的compareTo方法,演示了这种方法:
1 | // Multiple-field Comparable with primitive fields |
在Java 8中Comparator接口提供了一系列比较器方法,可以使比较器流畅地构建。 这些比较器可以用来实现compareTo方法,就像Comparable接口所要求的那样。 许多程序员更喜欢这种方法的简洁性,尽管它的性能并不出众:在我的机器上排序PhoneNumber实例的数组速度慢了大约10%。 在使用这种方法时,考虑使用Java的静态导入,以便可以通过其简单名称来引用比较器静态方法,以使其清晰简洁。 以下是PhoneNumber的compareTo方法的使用方法:
1 | // Comparable with comparator construction methods |
此实现在类初始化时构建比较器,使用两个比较器构建方法。第一个是comparingInt方法。它是一个静态方法,它使用一个键提取器函数式接口( key extractor function)作为参数,将对象引用映射为int类型的键,并返回一个根据该键排序的实例的比较器。在前面的示例中,comparingInt方法使用lambda表达式,它从PhoneNumber中提取区域代码,并返回一个Comparator<PhoneNumber>,根据它们的区域代码来排序电话号码。注意,lambda表达式显式指定了其输入参数的类型(PhoneNumber pn)。事实证明,在这种情况下,Java的类型推断功能不够强大,无法自行判断类型,因此我们不得不帮助它以使程序编译。
如果两个电话号码实例具有相同的区号,则需要进一步细化比较,这正是第二个比较器构建方法,即thenComparingInt方法做的。 它是Comparator上的一个实例方法,接受一个int类型键提取器函数式接口( key extractor function)作为参数,并返回一个比较器,该比较器首先应用原始比较器,然后使用提取的键来打破连接。 你可以按照喜欢的方式多次调用thenComparingInt方法,从而产生一个字典顺序。 在上面的例子中,我们将两个调用叠加到thenComparingInt,产生一个排序,它的二级键是prefix,而其三级键是lineNum。 请注意,我们不必指定传递给thenComparingInt的任何一个调用的键提取器函数式接口的参数类型:Java的类型推断足够聪明,可以自己推断出参数的类型。
Comparator类具有完整的构建方法。对于long和double基本类型,也有对应的类似于comparingInt和thenComparingInt的方法,int版本的方法也可以应用于取值范围小于 int的类型上,如short类型,如PhoneNumber实例中所示。对于double版本的方法也可以用在float类型上。这提供了所有Java的基本数字类型的覆盖。
也有对象引用类型的比较器构建方法。静态方法comparing有两个重载方式。第一个方法使用键提取器函数式接口并按键的自然顺序。第二种方法是键提取器函数式接口和比较器,用于键的排序。thenComparing方法有三种重载。第一个重载只需要一个比较器,并使用它来提供一个二级排序。第二次重载只需要一个键提取器函数式接口,并使用键的自然顺序作为二级排序。最后的重载方法同时使用一个键提取器函数式接口和一个比较器来用在提取的键上。
有时,你可能会看到compareTo或compare方法依赖于两个值之间的差值,如果第一个值小于第二个值,则为负;如果两个值相等则为零,如果第一个值大于,则为正值。这是一个例子:
1 | // BROKEN difference-based comparator - violates transitivity! |
不要使用这种技术!它可能会导致整数最大长度溢出和IEEE 754浮点运算失真的危险[JLS 15.20.1,15.21.1]。 此外,由此产生的方法不可能比使用上述技术编写的方法快得多。 使用静态compare方法:
1 | **// Comparator based on static compare method** |
或者使用Comparator的构建方法:
1 | // Comparator based on Comparator construction method |
总而言之,无论何时实现具有合理排序的值类,你都应该让该类实现Comparable接口,以便在基于比较的集合中轻松对其实例进行排序,搜索和使用。 比较compareTo方法的实现中的字段值时,请避免使用”<”和”>”运算符。 相反,使用包装类中的静态compare方法或Comparator接口中的构建方法。
15. 使类和成员的可访问性最小化
将设计良好的组件与设计不佳的组件区分开来的最重要的因素是,组件将其内部数据和其他组件的其他实现细节隐藏起来。一个设计良好的组件隐藏了它的所有实现细节,干净地将它的API与它的实现分离开来。然后,组件只通过它们的API进行通信,并且对彼此的内部工作一无所知。这一概念,被称为信息隐藏或封装,是软件设计的基本原则[Parnas72]。
信息隐藏很重要有很多原因,其中大部分来源于它将组成系统的组件分离开来,允许它们被独立地开发,测试,优化,使用,理解和修改。这加速了系统开发,因为组件可以并行开发。它减轻了维护的负担,因为可以更快速地理解组件,调试或更换组件,而不用担心损害其他组件。虽然信息隐藏本身并不会导致良好的性能,但它可以有效地进行性能调整:一旦系统完成并且分析确定了哪些组件导致了性能问题(条目 67),则可以优化这些组件,而不会影响别人的正确的组件。信息隐藏增加了软件重用,因为松耦合的组件通常在除开发它们之外的其他环境中证明是有用的。最后,隐藏信息降低了构建大型系统的风险,因为即使系统不能运行,各个独立的组件也可能是可用的。
Java提供了许多机制来帮助信息隐藏。 访问控制机制(access control mechanism)[JLS,6.6]指定了类,接口和成员的可访问性。 实体的可访问性取决于其声明的位置,以及声明中存在哪些访问修饰符(private,protected和public)。 正确使用这些修饰符对信息隐藏至关重要。
经验法则很简单:让每个类或成员尽可能地不可访问。换句话说,使用尽可能低的访问级别,与你正在编写的软件的对应功能保持一致。
对于顶层(非嵌套的)类和接口,只有两个可能的访问级别:包级私有(package-private)和公共的(public)。如果你使用public修饰符声明顶级类或接口,那么它是公开的;否则,它是包级私有的。如果一个顶层类或接口可以被做为包级私有,那么它应该是。通过将其设置为包级私有,可以将其作为实现的一部分,而不是导出的API,你可以修改它、替换它,或者在后续版本中消除它,而不必担心损害现有的客户端。如果你把它公开,你就有义务永远地支持它,以保持兼容性。
如果一个包级私有顶级类或接口只被一个类使用,那么可以考虑这个类作为使用它的唯一类的私有静态嵌套类(条目 24)。这将它的可访问性从包级的所有类减少到使用它的一个类。但是,减少不必要的公共类的可访问性要比包级私有的顶级类更重要:公共类是包的API的一部分,而包级私有的顶级类已经是这个包实现的一部分了。
对于成员(属性、方法、嵌套类和嵌套接口),有四种可能的访问级别,在这里,按照可访问性从小到大列出:
- private——该成员只能在声明它的顶级类内访问。
- package-private——成员可以从被声明的包中的任何类中访问。从技术上讲,如果没有指定访问修饰符(接口成员除外,它默认是公共的),这是默认访问级别。
- protected——成员可以从被声明的类的子类中访问(受一些限制,JLS,6.6.2),以及它声明的包中的任何类。
- public——该成员可以从任何地方被访问。
在仔细设计你的类的公共API之后,你的反应应该是让所有其他成员设计为私有的。 只有当同一个包中的其他类真的需要访问成员时,需要删除私有修饰符,从而使成员包成为包级私有的。 如果你发现自己经常这样做,你应该重新检查你的系统的设计,看看另一个分解可能产生更好的解耦的类。 也就是说,私有成员和包级私有成员都是类实现的一部分,通常不会影响其导出的API。 但是,如果类实现Serializable接口(条目 86和87),则这些属性可以“泄漏(leak)”到导出的API中。
对于公共类的成员,当访问级别从包私有到受保护级时,可访问性会大大增加。 受保护(protected)的成员是类导出的API的一部分,并且必须永远支持。 此外,导出类的受保护成员表示对实现细节的公开承诺(条目 19)。 对受保护成员的需求应该相对较少。
有一个关键的规则限制了你减少方法访问性的能力。 如果一个方法重写一个超类方法,那么它在子类中的访问级别就不能低于父类中的访问级别[JLS,8.4.8.3]。 这对于确保子类的实例在父类的实例可用的地方是可用的(Liskov替换原则,见条目 15)是必要的。 如果违反此规则,编译器将在尝试编译子类时生成错误消息。 这个规则的一个特例是,如果一个类实现了一个接口,那么接口中的所有类方法都必须在该类中声明为public。
为了便于测试你的代码,你可能会想要让一个类,接口或者成员更容易被访问。 这没问题。 为了测试将公共类的私有成员指定为包级私有是可以接受的,但是提高到更高的访问级别却是不可接受的。 换句话说,将类,接口或成员作为包级导出的API的一部分来促进测试是不可接受的。 幸运的是,这不是必须的,因为测试可以作为被测试包的一部分运行,从而获得对包私有元素的访问。
公共类的实例属性很少公开(条目 16)。如果一个实例属性是非final的,或者是对可变对象的引用,那么通过将其公开,你就放弃了限制可以存储在属性中的值的能力。这意味着你放弃了执行涉及该属性的不变量的能力。另外,当属性被修改时,就放弃了采取任何操作的能力,因此公共可变属性的类通常不是线程安全的。即使属性是final的,并且引用了一个不可变的对象,通过使它公开,你就放弃切换到不存在属性的新的内部数据表示的灵活性。
同样的建议适用于静态属性,但有一个例外。 假设常量是类的抽象的一个组成部分,你可以通过public static final属性暴露常量。 按照惯例,这些属性的名字由大写字母组成,字母用下划线分隔(条目 68)。 很重要的一点是,这些属性包含基本类型的值或对不可变对象的引用(条目 17)。 包含对可变对象的引用的属性具有非final属性的所有缺点。 虽然引用不能被修改,但引用的对象可以被修改,并会带来灾难性的结果。
请注意,非零长度的数组总是可变的,所以类具有公共静态final数组属性,或返回这样一个属性的访问器是错误的。 如果一个类有这样的属性或访问方法,客户端将能够修改数组的内容。 这是安全漏洞的常见来源:
1 | // Potential security hole! |
要小心这样的事实,一些IDE生成的访问方法返回对私有数组属性的引用,导致了这个问题。 有两种方法可以解决这个问题。 你可以使公共数组私有并添加一个公共的不可变列表:
1 | private static final Thing[] PRIVATE_VALUES = { ... }; |
或者,可以将数组设置为private,并添加一个返回私有数组拷贝的公共方法:
1 | private static final Thing[] PRIVATE_VALUES = { ... }; |
要在这些方法之间进行选择,请考虑客户端可能如何处理返回的结果。 哪种返回类型会更方便? 哪个会更好的表现?
在Java 9中,作为模块系统(module system)的一部分引入了两个额外的隐式访问级别。模块包含一组包,就像一个包包含一组类一样。模块可以通过模块声明中的导出(export)声明显式地导出某些包(这是module-info.java的源文件中包含的约定)。模块中的未导出包的公共和受保护成员在模块之外是不可访问的;在模块中,可访问性不受导出(export)声明的影响。使用模块系统允许你在模块之间共享类,而不让它们对整个系统可见。在未导出的包中,公共和受保护的公共类的成员会产生两个隐式访问级别,这是普通公共和受保护级别的内部类似的情况。这种共享的需求是相对少见的,并且可以通过重新安排包中的类来消除。
与四个主要访问级别不同,这两个基于模块的级别主要是建议(advisory)。 如果将模块的JAR文件放在应用程序的类路径而不是其模块路径中,那么模块中的包将恢复为非模块化行为:包的公共类的所有公共类和受保护成员都具有其普通的可访问性,不管包是否由模块导出[Reinhold,1.2]。 新引入的访问级别严格执行的地方是JDK本身:Java类库中未导出的包在模块之外真正无法访问。
对于典型的Java程序员来说,不仅程序模块所提供的访问保护存在局限性,而且在本质上是很大程度上建议性的;为了利用它,你必须把你的包组合成模块,在模块声明中明确所有的依赖关系,重新安排你的源码树层级,并采取特殊的行动来适应你的模块内任何对非模块化包的访问[Reinhold ,3]。 现在说模块是否会在JDK之外得到广泛的使用还为时尚早。 与此同时,除非你有迫切的需要,否则似乎最好避免它们。
总而言之,应该尽可能地减少程序元素的可访问性(在合理范围内)。 在仔细设计一个最小化的公共API之后,你应该防止任何散乱的类,接口或成员成为API的一部分。 除了作为常量的公共静态final属性之外,公共类不应该有公共属性。 确保public static final属性引用的对象是不可变的。