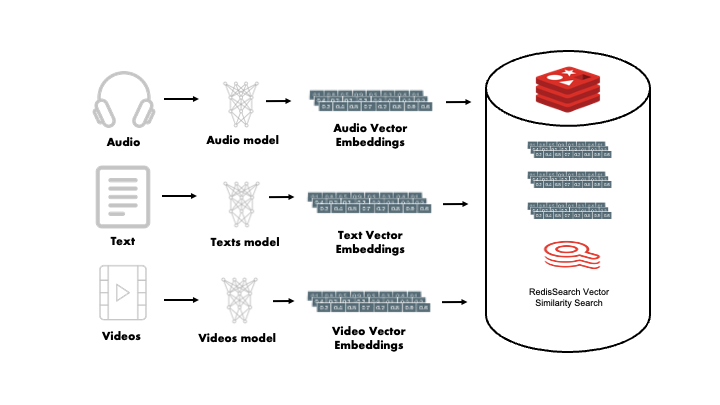
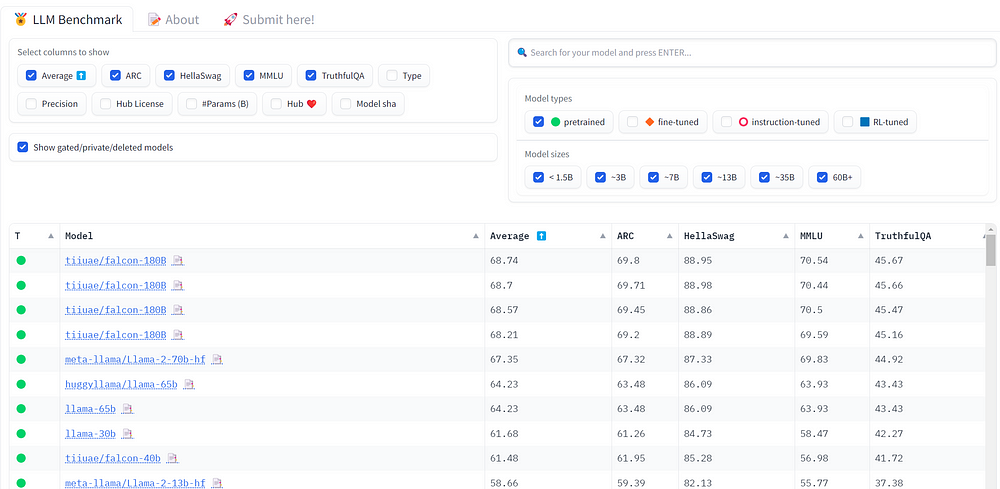
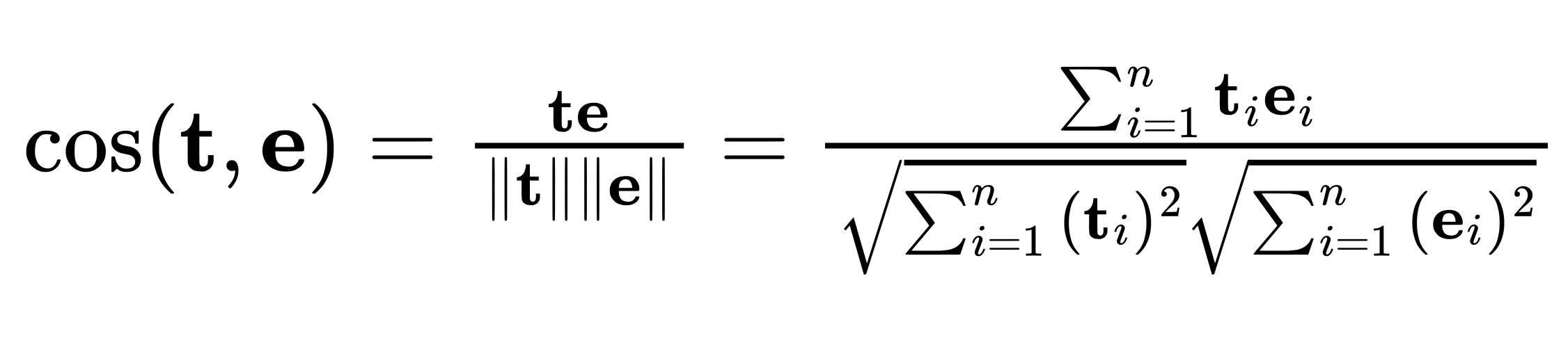介绍
Transformer模型于2017年发明,并首次在开创性论文“Attention is All You Need”(Vaswani等人,2017)中提出,它对深度学习做出了革命性的贡献,可以说是对整个计算机科学的贡献。作为一个神经机器翻译的工具,它已经被证明是深远的,扩展了它的适用性,超越了自然语言处理(NLP),巩固了它作为一个通用的、通用的神经网络架构的地位。
在这个全面的指南中,我们将剖析Transformer模型的核心,深入探索从其注意机制到编码器-解码器( encoder-decoder)结构的每个关键组件。我们不会停留在基础层面,我们将遍历利用transformer功能的大型语言模型,深入研究它们独特的设计属性和功能。进一步扩大视野,我们将探索transformer模型在NLP之外的应用,并探讨这一有影响力的架构当前的挑战和潜在的未来方向。此外,还将为那些有兴趣进一步探索的人提供一个精心策划的开源实现列表和补充资源。

图0:我们将在本文中深入探讨的Transformer体系结构。改编自(Vaswani et al. 2017)。
Transformer神经体系结构的设计者对寻找一种可以用于序列到序列建模的体系结构很感兴趣。这并不是说没有现有的序列建模体系结构,只是它们有很多缺点。还有哪些类型的神经网络可以用于序列建模?它们的缺点是什么?让我们在激励Transformers的过程中寻找这些问题的答案。
多层感知器(MLP)
让我们从多层感知器(MLP)开始,这是一种经典的神经网络方法。MLP本身并不是超级强大,但你会发现它们几乎集成在任何其他架构中(令人惊讶的是,甚至在transformer中)。MLP基本上是一个线性层序列或完全连接的层。

图1:多层感知器(MLP)。
在AI社区找到各种模式的最佳架构之前,MLP长期以来一直用于建模不同类型的数据,但有一点是肯定的,它们不适合序列建模。由于它们的前馈设计,它们不能保持序列中信息的顺序。当数据的顺序丢失时,序列数据就失去了意义。因此,MLP不能保持信息的顺序使其不适合序列建模。此外,MLP需要许多参数,这是神经网络可能具有的另一个不希望的属性。
卷积神经网络
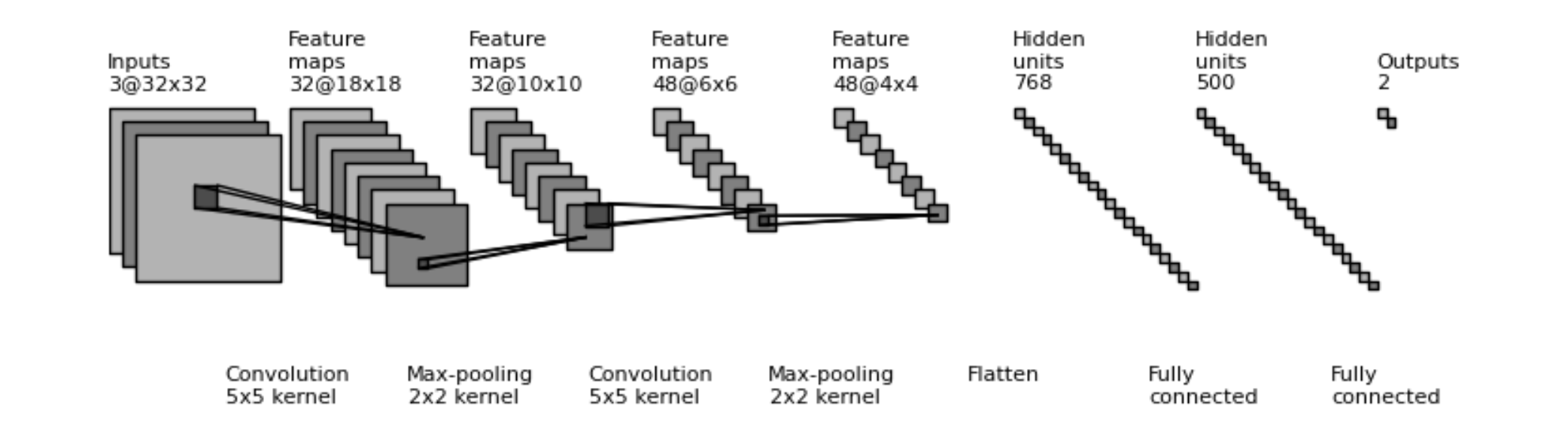
卷积神经网络(CNN 或ConvNets)是一类神经网络架构,以处理图像和其他模式(如文本和视频)而闻名。

图2:用于文本理解的卷积神经网络(X。Zhang and LeCun 2015)。
迄今为止,卷积神经网络在小尺度和大尺度视觉识别方面取得了成功,但在序列建模方面并不十分成功。由于它们的局部性(计算被捆绑在输入数据的局部部分),它们很容易并行化(对GPU很好),它们需要许多层来处理长期依赖关系。与固定长度的图像相反,大多数顺序数据具有可变长度,这是ConvNets或MLP都无法处理的。
循环神经网络
与MLP或ConvNets不同,递归神经网络(RNN)的设计考虑了序列。RNN在其设计中具有反馈回路,这是其模拟序列数据能力的关键因素。RNN的另一个令人满意的特性是它们可以处理可变长度的数据。
RNN的连接方式存在一些基本问题。首先,由于它们的顺序设计,它们可能对长期序列不稳定。

图3:循环神经网络(RNN)。
循环网络有很多变体。其中一个著名的版本是长短期记忆(LSTM)。LSTM可以处理长期序列。它们有一个细胞状态(下图中的水平直线)和门,它们都平滑信息流。

图4:长短期记忆(LSTM)
LSTM的另一个稍微有效的版本是门循环单元(GRUs)。LSTM对于基本的序列建模问题非常有效,但它们的应用范围仍然有限。正如我们之前所说,它们不能被平行化,也就是说它们不能被缩放。此外,即使它们能够保持信息的顺序,它们也无法推断出它们正在处理的数据的全局上下文。背景很重要。以机器翻译为例(这个任务基本上给了我们transformer),被翻译的句子的上下文和顺序一样重要。
我们所做的基本上就是激励Transformers。到目前为止,我们已经看到,先前的神经网络要么不适合序列建模,要么不可并行化,要么不稳定,要么受上下文长度的限制,这些都是序列神经结构的主要特征。
现在我们有了正确的背景知识,让我们深入了解transformer架构。
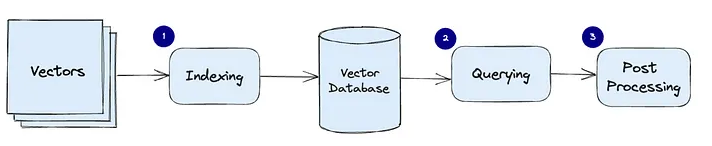
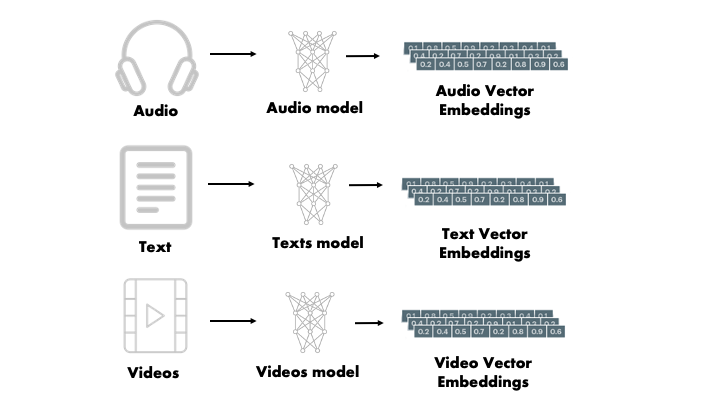
Transformer是一种神经网络架构,可以处理文本、音频、视频和图像等顺序数据(作为图像补丁的序列)。Transformer不使用任何循环层或卷积层。它的基础层叫做Attention(注意力)。它还包含其他基本层,如全连接层、规范化层[主要是LayerNorm](Ba, Kiros, and Hinton 2016)、Embedding层和位置编码层。在下一节中,我们将看到这些层的作用。

图5:Transformer体系结构。改编自(Vaswani et al. 2017)。
正如我们在开头提到的,transformer最初是为机器翻译引入的,这是一项需要处理两个序列(输入和输出都是序列)的任务。因此,transformer模型有两个部分:处理输入的encoder和生成输出的解码器。关于encoder、解码器和其他层的更多信息将在下面讨论。
Encoder(编码器)
编码器是transformer结构的主要模块之一,位于输入序列的输入端。编码器将输入序列转换为压缩表示。在原始的transformer架构中,encoder重复了6次(这取决于架构的整体尺寸,可以更改)。每个encoder块有3个主要层,即多头注意(MHA),层规范和mlp(或根据论文的前馈)。
多头注意和mlp在transformer论文中被称为子层。子层之间有层归一化,层之间有dropout和残差连接(各层的正确流程见图)。
如前所述,encoder层数为6层。encoder层的数量越多,模型就越大,模型就越有可能捕获输入序列的全局上下文,从而产生更好的任务泛化。
Decoder(解码器)
解码器几乎与encoder相同,除了在encoder的输出上操作额外的多头注意。解码器的目标是将encoder输出与目标序列融合,并进行预测(或预测下一个token)。
在解码器中占用目标序列的注意力被屏蔽,以防止当前(正在处理的)token关注目标序列中的后续tokens。如果解码器可以访问完整的目标序列,这基本上是作弊,并且可能导致模型不能泛化到训练数据之外。
解码器通常也与encoder重复相同的次数。在原transformer中,解码器块的数量也是6块。
Attention(注意力)
注意力到底是什么?
注意力是transformer结构的基本要素。从本质上讲,注意是一种机制,它可以让神经网络更多地关注输入数据中包含有意义信息的部分,而较少关注输入的其余部分。
早在transformer架构引入之前,注意力机制就被用于各种任务中。注意力的概念最早出现在神经机器翻译(NMT)方法中,该方法使用注意力来寻找输入句子中最相关信息集中的[位置集](Bahdanau, Cho, and Bengio 2014)。因为他们基于注意力的NMT可以联合或同时对齐和翻译,所以它比以前的方法表现得更好。如下图所示,该网络能够在翻译的句子中找到正确的单词顺序,这是之前的神经机器翻译方法难以实现的壮举。

图6:神经机器学习翻译中的源句和目标句对齐(Bahdanau, Cho, and Bengio 2014)。x轴和y轴分别表示源句和翻译句。每个像素表示源(输入)token与其对应的目标token的关注权重。对角线上的注意表示单词按相应的顺序排列(例如:对->L ‘ accord sur la)。注意可以找出正确的词序(例如:European Economic Area ->区域(欧洲)。
上面的图片是怎么回事?你能发现什么吗?在翻译的句子中,只要在目的语中有意义,单词的顺序就会被颠倒。因此,在翻译一个句子时,注意不仅可以赋予模型正确翻译句子的能力,而且还可以根据目标语言的上下文按照正确的顺序进行翻译。简而言之,在将一种语言翻译成另一种语言时,注意力可以识别和保存语境。
另一个使用注意力的早期工作是在神经图像字幕中发现的(Xu et al. 2015)。在这项工作中,作者使用卷积神经网络进行特征提取,并使用带有注意力机制的rnn来生成与输入图像最一致的标题。下图(取自论文)显示了模型大致关注的地方。

图7:用神经字幕模型生成字幕。白色区域显示了模型在生成标题“一个女人在公园里扔飞盘”时聚焦的位置。图片来自Xu et al. 2015)。
在全局层面上,在图像字幕模型中集成注意机制有助于模型在生成字幕时关注输入图像中有意义的部分。

图8:模型可以在生成标题时关注关键对象。图片取自Xu et al. 2015)。
我们上面使用的两个例子都证明了注意力的有效性。注意力确实是一种神奇的机制,它允许神经网络专注于包含有意义信息的部分输入数据,而较少关注其余输入数据。
现在我们了解了注意力,让我们看看transformer体系结构中注意力函数的输入:查询、键和值。
注意力功能:Query, Key, Value(查询、键、值)
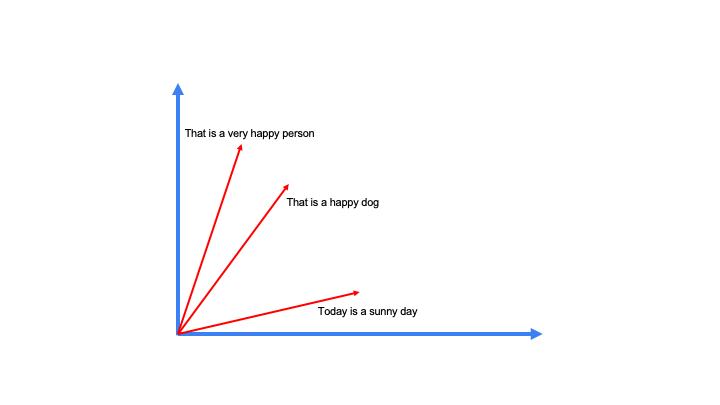
直观地说,注意力实际上是“关注输入数据中最重要的部分”。从技术上讲,注意力测量两个向量之间的“相似度”,并返回“加权相似度分数”。一个标准的注意力函数有三个主要输入:查询、键和值向量。在分解注意力函数之前,让我们试着理解键、值和查询的含义。
查询、键和值是搜索引擎和数据库系统中常用的术语。为了理解这些术语,让我们举一个简单的例子:1假设你正在搜索ArXiv上基于注意力的论文。理想情况下,您将在搜索框中输入查询。在内部,ArXiv可以通过一组预定义的键来组织论文。在ArXiv给出你所要求的论文之前,它会将你的查询与那些预定义的密钥集进行比较,并返回与查询和密钥对应最匹配的论文。Values仅指数据库中的所有论文。作为免责声明,我们使用这个示例来理解查询、键和值在搜索和数据库系统上下文中的含义。这并不是试图展示ArXiv系统是如何工作的。

图9:ArXiv论文搜索系统中的查询、键和值示例。
对查询、键和值有了这样直观的理解之后,让我们转向注意力函数的数学表示。

由上式可知,Q、K、V分别为查询矩阵、键矩阵、值矩阵。我们计算查询和键的点积,并将乘积除以一个比例因子dk的平方根。比例因子用于避免QK^T^的大值会导致小梯度的情况。然后,我们用softmax将点积归一化为概率分布(这基本上给了我们加权和),并通过将其与值相乘,我们得到加权值。

图10:点积注意力的图形表示。图改编自(Vaswani, 2017)。
上面描述的注意力被称为缩放点积注意力,一种改进的点积注意力(Luong, Pham, and Manning 2015)。还有其他类型的注意力,如添加性注意力(Bahdanau, Cho, and Bengio 2014),基于内容的注意力(Graves, Wayne, and Danihelka 2014),基于位置的注意力(Bahdanau, Cho, and Bengio 2014)和一般注意力(Luong, Pham,and Manning 2015)。每一种注意力类型都可以应用于全局(整个输入数据),因此是全局注意力,也可以应用于局部(输入数据的子部分),因此是局部注意力。
你可能听说过transformer是平行的,你可能想知道它是从哪里来的。变压器并联源于注意函数。如果查询、键和值都是矩阵,则可以在两个主要的矩阵乘法中执行注意力,因此不涉及循环或任何循环操作。gpu的计算注意力更快。对于更大的模型(数以十亿计的参数)和大量的训练数据(数以十亿/万亿计的tokens),注意力可能是昂贵的,因为每个token都要参加其他tokens,这需要二次时间复杂度。
注意
如果查询、键和值来自同一来源,则应用于它们的关注称为自关注。如果它们来自不同的来源,我们说***交叉注意。
多头注意力
我们在上面描述的是一个单一的注意层。在实践中,只有一个注意层通常不会得到好的结果。相反,人们倾向于并行计算多个注意层,并将结果串联起来。简而言之,这就是多头注意力。多头注意力基本上是在线性投影的QKV向量上计算的多个独立注意力。在下面的多头注意图中,将连接的注意值线性投影到模型维度。

图11:多头注意力。图改编自(Vaswani, 2017)。
正如transformer架构的设计者所解释的那样,并行计算多个关注点允许模型“共同关注来自不同位置的不同表示子空间的信息”。*(Vaswani et al. 2017)。关于多头注意力的一个令人惊讶的事情是,它不会增加总体计算成本,因为每个头像的维度是头像数量的十分之一(i。E、底座transformer的磁头是整体模型尺寸的8倍(即512倍)。因此,如果模型(文中dmodel)的维数为512,则多头注意中的头像数为8,则每个头像为512/8=64。
在ConvNets中,多头注意力可以被视为深度可分离卷积(Chollet 2017)。深度可分离卷积是一种特殊类型的卷积,它将输入张量分成多个通道,在每个通道上独立操作,连接各个输出,并将结果提供给点卷积(1x1卷积相当于线性投影)。
MLPs
MLPs或多层感知器2是encoder和解码器中的两个子层之一。Transformer中的MLPs由两个线性层组成,中间有ReLU激活,它们独立且相同地应用于每个位置。

图12:transformer中的多层感知器(MLP)。
Embeddings和位置编码层
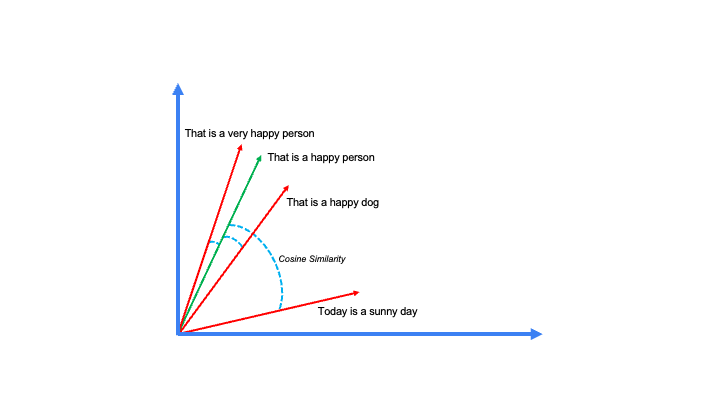
transformer架构包含两个Embedding层:一个在encoder处用于处理输入或源序列,另一个在解码器处用于处理目标或输出序列。这些Embedding层将输入或输出tokens转换为固定大小的密集向量,本质上是将序列中的每个token映射到特定的密集向量。利用Embeddings是语言建模的标准实践,因为它们提供了语义深度。有了这些嵌入的token向量,那些具有相似语义的向量倾向于在同一方向上对齐3。
基本transformer中的Embeddings尺寸为512(这是整个模型的尺寸)。作为旁注,transformer架构在整个网络中保持相同的尺寸,基本模型为512。这就是之前所说的dmodel模型。
位置编码在Transformer模型中的encoder和解码器的初始阶段都是不可或缺的组件。它们用于保持序列中tokens的顺序。有人可能会质疑这些位置Embeddings的必要性。这源于注意力机制固有的排列不变性,因此修改tokens的顺序不会改变输出加权值4。因此,注意机制本身缺乏对token顺序的意识。由于transformer架构不包含任何其他递归方法,因此引入位置编码以使模型具有序列中tokens的位置感知。实质上,如果没有位置编码,Transformer确实会表现出排列不变性。然而,这样的设计对于序列顺序具有重要意义的任务来说是不够的,就像大多数NLP任务一样。
为了在序列中编码位置信息,transformer的设计者使用了不同频率的正弦函数。他们还尝试了习得的位置Embeddings,但结果并没有什么不同。
残留连接,层规范化,和Dropout
残差连接是神经网络设计的核心,也是现代深度学习中流行的成分之一。自从深度残差网络在计算机视觉中证明了可观的性能(He et al. 2016)以来,残差连接已被用于几乎大多数神经网络,不仅用于视觉,还用于其他模式。事实上,现在几乎不可能看到一个不使用剩余连接的神经网络模型。残差连接缓解了梯度不稳定问题,有助于模型更快收敛。
transformer的作者之一Ashish Vaswani曾经说过,“在其他信息中,剩余连接将位置信息传递到更高层。”看看下面的图片!

图13:剩余连接将信号传递到更高层,从而改善了transformer模型的训练。第一幅图像的平滑对角线(带有残差)显示了残差连接的有效性。图片由Ashish Vaswani在CS224N拍摄。
层归一化(Ba, Kiros, and Hinton 2016)也是现代神经网络中最常用的归一化技术之一。层归一化通过用层均值和方差对层的激活进行归一化,显著减少了训练时间。与批归一化(Ioffe and Szegedy 2015)不同,批归一化是用在小批上计算的均值和方差对每一层进行归一化,而层归一化只是用每个激活的均值和方差对每一层进行归一化。层规范化在训练和测试阶段保持相似的行为,不像批规范化在这两个阶段表现出不同的行为。
有两种方法可以在transformer体系结构中实现层规范化。第一种方法称为后层规范化(Post- ln),其中层规范化放置在残馀块之间(或在每个子层之后(多头注意和mlp),但在加法之后)。第二种选择称为预层规范化(Pre- ln),其中层规范化放置在剩余块内的每个子层之前。标准transformer架构使用Post-LN,但在训练原始transformer的更新代码库5中,发现它是Pre-LN。纸张和代码之间的不匹配使得很难追溯到初始transformer中层规范化的实际位置,但从提交历史来看,似乎后来使用了Pre-LN。作者本可以更新这篇论文,但他们可能并不介意,因为没有人知道这篇论文会成为神经网络设计领域有影响力的参考论文之一。

图14:层后归一化(Post- ln)和层前归一化(Pre- ln)
因此,层归一化应该在哪里并不明确,这是一个积极的研究问题。最近一项关于Pre-LN和Post-LN影响的研究(Xiong et al. 2020)表明,在多头注意力和mlp之前进行层归一化(Pre-LN)可以提高训练效果,并且比在多头注意力和mlp之后进行层归一化收敛得快得多。该研究还声称,使用Pre-LN,你不需要聪明地选择学习率调度器,因为Pre-LN有更好的初始化。前ln和后ln都不是完美的。最近的另一项研究引入了ResDual(Xie et al. 2023),通过引入层归一化的附加残差连接,基本上缓解了ln前和ln后的问题。
应该在哪里放置图层规范化仍然是一个问题,但这应该不是一个问题。正如许多人注意到的那样,transformer似乎是一种通用架构。在语言建模、视觉识别和多模态学习方面,原始的香草transformer(有一些调整,如yes LN)仍然是大多数新颖作品的背后,并且有数百万的作品声称可以改进transformer。因此,我们的目标应该是保持这种架构的普遍性。我们将在文章末尾的高效Transformers中看到更多这方面的内容。
在我们结束本节之前,让我们讨论一下transformer架构中的dropout(Srivastava et al. 2014)。层规范化可以作为一种副作用的正则化器,但您仍然需要其他形式的网络正则化来处理过拟合。Dropout应用于每个子层的输出(在加法和归一化之前)。它还适用于encoder和解码器堆栈中的Embeddings和位置编码之和。有关训练transformer中使用的其他正则化技术和其他训练细节,请查看论文以获取更多信息。
线性和Softmax图层
解码器后的线性层获取解码激活并将其投影到词汇表的大小。这个线性层基本上会产生对数。softmax层将获取这些逻辑并将它们转换为下一个令牌概率。下一个预测的token基本上是softmax输出的argmax。
可视化的关注
注意力可以从输入序列中捕获整体上下文,这通常会提高模型的性能。通过将注意力可视化,我们可以看到输入序列的哪些部分对模型的输出有显著影响。这有助于我们更好地理解Transformer神经网络的内部工作原理。

图15:使用ExBert可视化注意力。
上图描绘了GPT-2第8^th^层的注意力头(Radford et al. 2019)。从图中可以清楚地看出,即使在transformer的早期层中,大多数tokens也是相互关联的。
随着时间的推移,许多可视化注意力的工具已经发展起来,以帮助深度学习社区理解transformer模型内部的情况。其中最著名的工具是BertViz(Vig 2019) 6。我们用来进行上述可视化的ExBert也是一个优秀而简单的工具,用于可视化大多数基于transformer的模型(如GPT-2和BERT)的注意力(Devlin et al. 2019)。
注意力的利弊
注意机制导致了序列建模和其他可以作为序列框架的模式的重大转变。与其他序列网络(如循环网络和1D卷积)相比,注意力网络具有许多优势。下面简要讨论这些问题:
- 长期依赖:传统的循环神经网络(rnn),包括长短期记忆(LSTM)和门控循环单元(GRU)等变体,容易出现长期依赖的问题,即模型保留信息的能力随着时间的推移而减弱。注意机制允许模型直接访问输入序列中的任何点,从而保留整个上下文,从而帮助缓解了这个问题。
- 并行化:与需要顺序计算的rnn不同,基于注意力的模型,如transformer架构,可以并行处理输入序列中的所有tokens。这使得它们的计算效率更高,并且可以更好地与当前的硬件加速器配合使用。
- 可解释性:注意提供一定程度的可解释性,因为它突出了模型认为对产生特定输出最重要的输入部分。“注意图”可以帮助我们理解模型在“思考”什么。
- 全局上下文:在卷积神经网络(cnn)中,接受野通常是局部的,取决于核大小,可能导致更广泛的上下文丢失。然而,需要注意的是,每个输出token都可以考虑输入序列中每个token的信息,从而保留全局上下文。
- 提高性能:基于注意力的模型,特别是那些利用transformer架构的模型,在许多NLP任务中取得了最先进的性能,优于RNN和CNN同行。他们还推动了计算机视觉、语音识别、机器人、多模式学习等其他模式的发展……
在下面的图中,我们总结了基于注意力的模型与其他深度神经网络架构的特性。

图16:注意力与其他循环网络架构的对比。变压器几乎具有神经网络的所有优良特性。卷积神经网络类似于transformer,但需要很多层才能实现远程依赖。
尽管它们提供了许多优势,但就像生活中的其他事情一样,注意力机制也面临着相当大的挑战。例如,在几种类型的注意力中,内存消耗和计算成本都可以随序列长度呈二次增长。已经提出了各种策略,例如稀疏注意力或局部注意力,以缓解这些问题,但其中大多数在实践中很少使用(Tay等人,2020)。
虽然Transformers在训练过程中提供了并行化的优势,但推理过程的本质可能仍然需要顺序方法,这取决于特定的任务。由于它们的自回归性质,Transformers每次产生一个token输出,继续这个迭代过程,直到完全产生所需的输出序列。
此外,虽然注意力提供了一定程度的可解释性,但它远非完美。尽管它提供了对模型功能的一些见解,但完全基于注意力图来完全破译复杂的模型,至少可以说,是一项艰巨的任务,如果不是几乎不可能的话。
大型语言转换模型
大语言模型的演变
大型语言模型(大语言模型)已经彻底改变了人类与机器学习系统的互动。自然语言接口,如ChatGPT和Bard,由健壮的大语言模型提供支持。这些模型为实时执行自然语言下游任务或通过zero-shot学习铺平了道路。在过去,这样的任务需要收集下游或特定任务的数据集。
在这些大语言模型的核心,它基本上是一个transformer模型,我们看到这里和那里有一点调整。在本节中,我们将深入研究大型语言模型的压缩演化。此外,我们将探索垂直大语言模型的发展,专门为特定应用设计和微调。
变压器基本模型有65M个参数,但从那以后,语言模型变得越来越大(以数十亿计),因此被称为大型语言模型。下面是流行的大型语言模型的快速概述。

图17:流行的大语言模型概述。对于编码器-解码器模型,层是堆叠的编码器/解码器或两者的数量,宽度是模型的维度,头是多头注意中注意层的数量,参数是参数的数量。注意,GPT-2测试中出现正面的次数并不确切。
大多数大型语言模型(大语言模型)的训练过程遵循大致相似的模式。在最初的预训练阶段,大语言模型会接触到大量经过整理的文本数据,这些数据来自书籍、文章、代码片段和网站等各种各样的材料。这个庞大的数据集对于模型获得对世界的全面理解至关重要,使它们能够创建丰富的表示并生成与上下文相关的响应。公众对大语言模型在各个领域的表现抱有很高的期望。为了满足这些期望,预训练数据必须包含广泛的主题和学科([J]。Yang et al. 2023。
大语言模型的实际训练以无监督的方式进行,特别关注自我监督学习(SSL)。这种方法消除了对标记数据的需求,考虑到几乎不可能对整个在线内容进行标记,这是一个至关重要的特性。

图18:大型语言模型的典型训练工作流。大语言模型通常在大型未标记数据集上进行训练。之后,它们可以通过prompt工程直接使用,也可以在专门任务中进一步微调。
然而,基于未标记数据的训练模型需要巧妙地实现训练目标,因为没有可参考的基础真理。因此,大多数大语言模型使用下一个令牌预测(NTP)作为常见的训练目标。本质上,大语言模型被教导准确地预测序列中的下一个token,逐渐增强他们的理解和生成能力。另一个常用的训练目标是掩码语言建模(MLM)。蒙面语言模型被训练来预测序列中的蒙面token。BERT推广了这一目标(Devlin et al. 2019)。
在预训练阶段之后,模型可以通过zero-shot学习或少射击学习等技术来生成文本。在zero-shot学习中,提示模型执行任务(或回答给定的问题),而不需要演示如何完成任务。在几次学习中,在要求模型执行任务之前,会给模型一些如何完成任务的演示。zero-shot学习和Few-shot学习是情境学习是指大语言模型使用语义先验知识生成连贯文本的能力(Jerry Wei等人,2023),而不需要任何参数更新(akyrek等人,2023)。提示大型语言模型(也称为prompt工程)本身是一个相对较新的领域,还有其他prompt工程技术,如思维链(CoT)(Jason Wei, Nye, and Liang 2022)。
情境学习倾向于擅长那些被认为简单的任务,但不擅长那些无法在prompts中轻易描述的任务。复杂的任务需要的不仅仅是巧妙的prompts。用Karpathy的话来说,“达到顶级性能(在复杂任务上)将包括微调,特别是在具有明确定义的具体任务的应用程序中,可以收集大量数据并在其上“实践”。7。因此,为了让大语言模型在数学、医学、科学领域(如化学)等专业任务上获得良好的表现,人们通常会在下游数据集上对大语言模型进行微调。我们将在垂直大语言模型一节中看到这方面的例子。
既然我们已经简要介绍了大型语言模型(Large Language Models, llm),现在是时候研究一些最流行的大语言模型了,特别关注它们的设计选择:它们是作为编码器、解码器,还是采用编码器-解码器的组合架构。
Encoder, Decoder, Encoder-decoder大语言模型
标准的transformer模型有编码器-解码器,这与它要执行的任务有关,这是机器翻译,你必须处理输入句子和目标翻译。自transformer以来,AI研究界针对不同的任务提出了不同的架构变体。根据不同的任务,一些transformer模型保持编码器-解码器结构,一些只使用解码器或只使用encoder。让我们从后者开始。
仅仅Encoder的LLMs
只有编码器的大语言模型使用标准transformer模型的encoder部分。只有编码器的大语言模型通常用于NLP判别任务,如文本分类和情感分析。
BERT(Devlin et al. 2019)是最流行的纯编码语言模型之一。BERT是最早的工作之一,它表明您可以在大型未标记文本数据集上预训练transformer(encoder),并通过附加的任务特定头部在各种下游任务上微调相同的架构。BERT的预训练目标是掩模语言建模(MLM)和下一句预测(NSP)8。通过屏蔽语言建模,我们屏蔽了给定百分比(论文中提到的15%)的输入tokens,目标是预测被屏蔽的tokens。在下一个句子预测中,对于组成输入序列的两个句子对,目标是随机预测两个句子的顺序是否正确。

图19:BERT中的掩码语言建模(MLM)。在图中所示的句子示例中,训练BERT的目标是预测被屏蔽词“network”。在下一个句子预测目标中,工作流程大致相同,但我们不是预测被屏蔽的tokens,而是预测由SEPtoken分隔的两个句子对是否顺序正确。
BERT是一项真正革命性的技术,它在无所不在的NLP下游任务上改进了SOTA。它也启发了其他用于NLP预训练的高效双向架构,如RoBERTa(Y。Liu et al. 2019](https://deeprevision.github.io/posts/001-transformer/#ref-liu2019roberta))代表鲁棒优化的BERT方法。RoBERTa介绍的主要设计选择之一是不使用下一个句子预测目标。
仅仅Decoder的LLMs
纯解码器大语言模型基于标准transformer的解码器部分。在transformer架构中,解码器与encoder非常相似,只是解码器中的自关注被屏蔽,以防止模型在生成当前token时查看后续tokens。
解码器大语言模型使用下一个token预测目标进行训练9。因此,它们一次只能生成一个token或自回归。总的来说,解码器模型用于生成任务。
最流行的解码器模型是GPT(生成预训练变压器)模型家族,最著名的是GPT-3(Brown等人。2020)和GPT-4(OpenAI 2023)。GPT-3和GPT-4是早期GPT模型的直接放大(Radford et al. 2018)。与任何其他大型语言模型一样,GPT模型是在大量未标记数据(数十亿到数万亿个tokens)上进行训练的。由于大规模的预训练和合适的训练目标,GPT模型开发了令人印象深刻的上下文学习能力,它们可以执行一系列NLP下游任务,而无需梯度更新或特定于任务的微调(Brown等人。2020)。事实上,GPT模型只需在zero-shot或Few-shot设置中提示模型,就可以执行文本分类、摘要、问题回答等任务10。这种卓越的情境学习能力通常被称为大型语言模型的“涌现能力”(Jason Wei等人,2022)。
GPT模型并不是唯一基于解码器的模型。事实上,大多数著名的大语言模型都是解码器。例如PaLM(Chowdhery等人。2022)、BLOOM(Le Scao等人。2022)、Chinchilla(Hoffmann等人。2022)、Llama(Touvron等人。2023)等等。
Encoder-Decoder LLMs
编码器-解码器大语言模型看起来像标准transformer。它们通常用于需要处理两个序列的任务中。(输入和目标都是序列)如机器翻译。与我们所见过的其他模型风格相比,编码器-解码器风格并没有被广泛使用。这类最著名的模型是T5(rafael et al. 2019)、BART(Lewis et al. 2019)、UL2(Tay et al. 2022)、FlanT5(Chung et al. 2022)、mT5(Xue et . 2021)等…
编码器-解码器风格也用于多模态学习,最著名的是视觉语言预训练(VLP)。工作原理类似SimVLM([Z]。Wang等。2021](https://deeprevision.github.io/posts/001-transformer/#ref-wang2021simvlm))和pal -X([X。Chen等人2023)使用encoder来学习图像和文本的联合表示,使用解码器来生成输出。
Vertical(垂直) LLMs
我们上面概述的大多数大语言模型通常被称为基础或前沿大语言模型。基础模型通常在具有自我监督的大量数据上进行训练,并且可以对其进行微调,以适应广泛的下游任务(Bommasani et al. 2022)。
垂直大语言模型是一类适用于特定应用的大语言模型。基础大语言模型可以推广到情感分析等简单任务,但它们在复杂任务或需要领域专业知识的任务上表现不佳。例如,基础LLM不太可能在医学问答任务中表现良好,因为它没有医学专业知识。更多的例子:基础LLM不太可能在法律问题回答任务中表现良好,因为它没有法律专业知识。在金融、物理、化学等其他领域也是如此……垂直大语言模型就是为了解决这个问题而设计的。他们在一个特定的领域受过训练,他们可以很好地完成需要该领域专业知识的任务。基础模型的目标是成为通才,但大多数时候,我们关心的是能把一件事做得很好的模型。
最近的垂直大语言模型的例子包括MedPaLM(Singhal et al. 2022)和Med-PaLM 2, ClinicalGPT(G。Wang等。2023), FinGPT([H.]Yang, Liu, and Wang 2023), bloomberg pt (Wu et al. 2023), Galactica(Taylor et al. 2022), Minerva(Lewkowycz et al. 2022)等。

图20:大语言模型拓扑。改编自[J]Yang et al. 2023。
Transformer被引入到自然语言处理(NLP)领域,更准确地说,是用于神经机器翻译。在大多数NLP任务中,Transformers的表现很快就超过了先前的神经网络,并迅速扩展到其他模式。在本节中,我们将简要讨论Transformers在视觉识别和其他模式中的出现。
视觉识别是最早受到Transformers显著影响的模式之一。在很长一段时间里,卷积神经网络是视觉识别领域的最新技术。因此,问为什么研究人员关心卷积神经网络的替代品是一个关键问题。卷积神经网络的主要缺点是其空间归纳偏差11。
transformer在图像处理中的最早应用之一是image transformer (Parmar et al. 2018),它将图像生成作为一个自回归问题,类似于文本生成。Image Transformer是一个应用于一系列像素的标准transformer,经过训练可以自回归地生成这些像素,直到创建完整的图像。这是一个很棒的想法,但事实证明,图像通常具有很大的分辨率,因此,对256x256的图像应用自关注是不可行的。有几部作品试图将transformer应用于图像域,但第一批成功的作品之一是视觉变压器(Dosovitskiy等人,2021),它将transformerencoder应用于一系列图像补丁。利用图像拼接思想克服了自关注的计算复杂性,标志着变换向计算机视觉领域的扩展迈出了重要的一步。
正如我们之前看到的,NLP中Transformers成功的巨大贡献是对大量未标记数据的无监督预训练。Vision transformer的成功也归功于数以百万计的训练图像,JFT-300M(C。Sun et al. 2017),尽管后来的MAE(He et al. 2021)和(Steiner et al. 2021)在经典的计算机视觉基准(如ImageNet)上取得了相当不错的性能。MAE是一种编码器-解码器自监督模型,它遵循BERT预训练的目标,预测随机掩码补丁,而BERT则探索巧妙的增强和正则化来训练ViT。ViT已被用作许多有影响力的论文的主干,如CLIP(Radford et al. 2021), DALLE•2(Ramesh et al. 2022),Stable Diffusion(Rombach et al. 2022),以及其他最近在视觉语言模型方面的研究。除了ViT支持视觉和语言的联合建模之外,它还被卷积神经网络增强,以在计算机视觉下游任务中获得这两个世界。ConvNets和Vision Transformer拓扑的著名作品有DETR(Carion et al. 2020)、PatchConvNet(Touvron et al. 2021)、MobileViT(Mehta and Rastegari 2022)等。
当涉及到人机交互时,视觉和语言是最重要的两种形式,所以大多数结合Transformers的作品都是在语言、视觉或视觉语言学习中进行的,这并不奇怪。也就是说,Transformers已用于其他模式,如强化学习(L。Chen et al. 2021](https://deeprevision.github.io/posts/001-transformer/#ref-chen2021decision))、机器人技术(Brohan et al. 2022)、机器猫(Bousmalis et al. 2023)和语音识别(Radford et al. 2022)。最后,像Gato(Reed et al. 2022)和ImageBind(Girdhar et al. 2023)这样的作品在几乎所有模式的建模方面都走得更远。
Transformer已经确立了自己作为通用架构的地位,最近跨不同模式的工作证明了这一点,但仍然存在挑战。
Transformer在语言、视觉、机器人和强化学习等各种模式上都表现出了显著的性能。Transformer神经网络体系结构具有一系列特征,使其成为适合这些领域的体系结构:它具有表现力,与当前的优化技术配合得很好,并且可以并行化。从这些特点来看,我们可以说transformer是一种高效的架构。然而,由于transformer自注意的二次时间和内存复杂度,其效率带来了巨大的计算成本。transformer的计算需求限制了其可扩展性及其在智能手机和微控制器等低预算设备中的应用。
在开发和部署机器学习系统时,模型效率是一个重要的考虑因素,因为模型在推理过程中的表现会影响用户体验(Dehghani et al. 2022)。已经有无数的transformer模型声称可以提高transformer架构的效率(内存占用和计算成本)(这些模型通常被称为“xformers”),但这些模型通常倾向于针对一个特定的基准或设备。大多数声称可以降低自关注的二次时间和内存复杂度的新型*** **模型都比普通transformer慢得多,在实践中很少使用,也不具备原始transformer的通用性(Tay et al. 2020)。
正如(Tay et al. 2020)在“高效Transformers”的调查中很好地指出的那样,理想的变形金刚应该减少自我关注的二次时间复杂度,但应该保持普遍性,并在所有任务和模式中表现良好。它也不应该为了内存而牺牲速度,不应该是硬设计的,应该保持优雅和简单。*更多信息,我建议您阅读[高效Transformers]的调查报告(https://arxiv.org/abs/2009.06732)。
 图21:高效Transformers的分类。图片来自Tay et al. 2020)。
图21:高效Transformers的分类。图片来自Tay et al. 2020)。
几乎所有改进的transformer模型都计算了注意力的近似值,以降低成本。与这些方法相反,实际上有一种注意力可以精确地计算出标准注意力值,但速度更快。这种方法就是FlashAttention(Dao et al. 2022),我们将在高层次上讨论它。
FlashAttention是快速和内存效率的算法,计算准确的注意力。FlashAttention比标准attention快2-4倍。它通过使用两种主要技术实现了计算效率的巨大提高:平铺和重新计算。平铺发生在向前传递中,涉及将注意力(K键和V值)的大矩阵分成块。FlashAttention不是在整个矩阵上计算注意力,而是在块上计算注意力,并将结果块连接起来,从而节省了大量内存。重新计算发生在向后传递,它基本上意味着重新计算注意力矩阵,而不是向前存储它。FlashAttention的想法归结为提高内存,而不是减少计算,因为现代gpu具有高理论FLOPs(Floaping Point Operations,意味着你想要最大化),但有限的内存12(means在内存中的任何节省都可以提高训练速度)。HBM(高带宽内存)通常很大,但它并不比片上SRAM(静态随机存取内存)快,因此,对块(K和V)的计算发生在SRAM中(因为它更快),但所有完整矩阵都存储在HBM中(因为它很大)。这种高层次的解释可能过于简单化,因为FlashAttention是在GPU层面实现的(使用CUDA软件),这实际上是IO感知的原因,但希望这能解释这个快速算法中发生的事情。
下图显示了GPU, FlashAttention算法的内存层次结构,以及GPT-2注意与FlashAttention的每个中间步骤所花费的时间(毫秒)。理想情况下,我们希望大量的计算由矩阵乘法(matmul)操作来完成,但令人惊讶的是,dropout、softmax和mask(i)。(例如,GPT-2是解码器模型)最终会占用GPT-2的整个运行时间,因为它们是在完整矩阵上计算的。Matmuls比那些其他操作花费更少的运行时间,因为gpu的设计正是为了快速处理矩阵乘法(它们具有非常高的理论FLOPs,最大化FLOPs的使用并不会减少运行时间)。通过使用平铺和重新计算技术,FlashAttention的计算时间明显低于标准注意,如下图所示。

图22:GPT-2注意与FlashAttention的内存层次、FlashAttention算法和运行时。
FlashAttention集成在PyTorch 2.0,Hugging FaceTransformers,微软的DeepSpeed, MosaicML作曲家库和许多其他库中。您可以在论文中了解更多FlashAttention,或观看核心作者的此视频和发布博客。在撰写本节时,FlashAttention2(Dao 2023)也发布了,它甚至比FlashAttention版本1要快几个数量级。FlashAttention2通过并行化序列长度维度而不是批大小和注意头的数量来提高并行性,并拆分Q(查询)矩阵而不是K和v。这篇博文(https://crfm.stanford.edu/2023/07/17/flash2.html)很好地解释了FlashAttention2给张量表带来了什么。
处理长上下文长度是Transformer大型模型研究的主要活跃领域之一。由于注意力的二次时间和记忆复杂性的直接后果,transformer不能处理长上下文窗口。研究扩展transformer架构上下文窗口的技术是一件很重要的事情,因为上下文窗口决定了在推理期间transformer内存中可以容纳的信息量。像长对话、总结长文档和执行长期计划这样的任务可能需要支持长上下文窗口的模型。Chen et al. 2023。
已经有很多关于上下文窗口和扩展它们的文章,例如S.Sun etal.2021,但我想强调最近的一篇论文,该论文围绕长上下文提出了显著的发现。最近的语言模型(基于transformer)可以接受较长的上下文,但不清楚长上下文是否真的有帮助。如图[N]所示。F. Liu et al. 2023,语言模型的性能随着输入上下文长度的增加而下降。因此,即使对于具有扩展上下文长度的模型,它们的性能对于更长的输入上下文仍然会下降。此外,该工作还发现,当相关信息被放置在输入上下文的开头或结尾时,语言模型表现良好,而当相关信息被放置在中间时,语言模型显著下降,这表明语言模型是u形推理器。
上面强调的研究结果很有吸引力,并提供了广泛的含义,可以适用于微调数据集的设计和上下文学习,但重要的是要注意,如果“transformer模型如何在长上下文窗口上执行”是一个活跃的研究领域,那么这些都不是既定的理解。我们希望未来的transformer模型能够在长输入序列上运行,同时无论放置的相关信息如何,都能表现良好。这实际上是大型语言模型的圣杯。
 图23:当相关信息位于输入上下文的开头或结尾时,语言模型(基于transformer)往往表现良好(左图),而对于较长的上下文(右图),它们的性能会下降。图表取自[N]。刘峰等。2023。
图23:当相关信息位于输入上下文的开头或结尾时,语言模型(基于transformer)往往表现良好(左图),而对于较长的上下文(右图),它们的性能会下降。图表取自[N]。刘峰等。2023。
神经网络设计的一个主要目标是构建一个单一的通用模型,该模型可以有效地处理多个模态,而无需特定于模态的编码器或预处理。实际上,transformer模型已经被广泛应用于各种领域,包括文本、图像、机器人和语音。然而,创造一种真正通用的transformer的目标仍然是一个挑战,这种变压器在所有模式下都能同样有效地工作,而不需要进行特定的调整。这一挑战来自数据类型和transformer模型本身的固有差异和复杂性,它们经常需要特定于模式的修改。
例如,处理文本、图像和语音的过程由于其各自的特征而具有独特的考虑。Transformers在数据可以被框架为一系列tokens的场景中表现出色,然而,将特定模态转置到这样一个序列的方法在不同的模态之间显着不同。因此,挑战在于设计一种能够以相当的效率统一地从所有数据类型中提取有价值的见解的单一体系结构。
这种架构的实现将标志着多模态学习领域的巨大进步,为可以在不同类型的数据之间无缝转换的模型铺平了道路,并有可能开启多模态表示学习的新探索途径。
目前几乎所有的多模态学习技术都是为每个模态使用单独的标记器和encoder,其中大多数也是为视觉语言学习而设计的。本节不会深入讨论当前基于Transformers的多模式方法的细节,但我们为有兴趣深入研究的人提供了示例:Flamingo(视觉语言)(Alayrac等人,2022), Gato(Reed等人,2022), ImageBind(Girdhar等人,2023), OFA(P。Wang et al. 2022), Unified-IO(Lu et al. 2022), Meta-Transformer([Y。Zhang et al. 2023)等。
请注意
几乎所有的transformer挑战都源于其极端的计算和内存要求。像FlashAttention这样真正高效的Transformers可能会缓解这些挑战。
最初的transformer模型是在Tensor2Tensor库中实现的13,但最近已经弃用了。Tensor2Tensor的继承者是基于JAX的Trax 14。
有许多transformer模型体系结构的开源实现。让我们简要讨论一下最流行的三种实现。HuggingFace Transformer库(Wolf etal . 2020)可以说是最流行的Transformers实现之一。该库简化了NLP(和视觉)下游任务的推理管道,并可用于训练或微调基于变压器的模型。HuggingFace Transformer库易于使用,它很干净,并且有一个庞大的开发人员和贡献者社区。Andrej Karpathy的minGPT和nanoGPT也是开源和研究社区中流行的实现。此外,x-transformers提供了各种transformer模型的简明和实验实现,通常来自新的研究论文。
最后,你不太可能需要从头开始实现transformer模型或它的一部分,因为现代深度学习框架,如PyTorch, Keras和JAX(Via flex)提供了可以轻松导入的层的实现,就像导入卷积或线性层一样。
补充的资源
本文对现有的围绕transformer神经网络体系结构理解的知识库做出了贡献。因此,不强调一些关于transformer体系结构的宝贵资源是疏忽的,我们将在下面简要地提供:
结论
Transformer神经网络体系结构在深度学习和计算机科学领域的重要性不容忽视。最初为神经机器翻译引入的transformer模型已经发展成为一种通用的通用架构,展示了超越自然语言处理的令人印象深刻的性能。
在本文中,我们深入研究了transformer的核心机制及其基本组件——它的encoder和解码器结构、注意机制、多头注意、mlp、Embedding、位置编码层等等。我们已经探讨了自我关注的几个好处,以及潜在的缺点。此外,通过研究注意力的可视化,我们对Transformers如何聚焦于输入序列的不同部分以产生输出有了更深入的了解。
Transformers是最近风靡全球的大型语言模型(大语言模型)的核心。我们已经看到了大语言模型及其不同设计风格的演变,以及Transformers在NLP之外的应用。我们还讨论了他们当前面临的挑战,包括对更高效模型的需求和对上下文窗口的有效使用。这些挑战为未来的研究和改进提供了令人兴奋的机会。
随着深度学习领域的不断发展,transformer架构仍然是现代机器学习系统的基础构建块。transformer架构有许多变化,但无论Transformers的未来如何,有一件事是肯定的-注意力是你所需要的。保持好奇,不断学习,时刻关注!
参考文献
Akyürek, Ekin, Dale Schuurmans, Jacob Andreas, Tengyu Ma, and Denny Zhou. 2023. “What Learning Algorithm Is in-Context Learning? Investigations with Linear Models.” arXiv Preprint arXiv:2211.15661.
Alayrac, Jean-Baptiste, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, et al. 2022. “Flamingo: A Visual Language Model for Few-Shot Learning.” arXiv Preprint arXiv:2204.14198.
Ba, Jimmy Lei, Jamie Ryan Kiros, and Geoffrey E Hinton. 2016. “Layer Normalization.” arXiv Preprint arXiv:1607.06450.
Bahdanau, Dzmitry, Kyunghyun Cho, and Yoshua Bengio. 2014. “Neural Machine Translation by Jointly Learning to Align and Translate.” arXiv Preprint arXiv:1409.0473.
Bommasani, Rishi, Drew A Hudson, Ehsan Adeli, Russ Altman, Simran Arora, Sydney von Arx, Michael S Bernstein, et al. 2022. “On the Opportunities and Risks of Foundation Models.” arXiv Preprint arXiv:2108.07258.
Bousmalis, Konstantinos, Giulia Vezzani, Dushyant Rao, Coline Devin, Alex X Lee, Maria Bauza, Todor Davchev, et al. 2023. “RoboCat: A Self-Improving Foundation Agent for Robotic Manipulation.” arXiv Preprint arXiv:2306.11706.
Brohan, Anthony, Noah Brown, Justice Carbajal, Yevgen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, et al. 2022. “RT-1: Robotics Transformer for Real-World Control at Scale.” arXiv Preprint arXiv:2212.06817.
Brown, Tom B, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, et al. 2020. “Language Models Are Few-Shot Learners.” arXiv Preprint arXiv:2005.14165.
Carion, Nicolas, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. 2020. “End-to-End Object Detection with Transformers.” arXiv Preprint arXiv:2005.12872.
Chen, Lili, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Michael Laskin, Pieter Abbeel, Aravind Srinivas, and Igor Mordatch. 2021. “Decision Transformer: Reinforcement Learning via Sequence Modeling.” arXiv Preprint arXiv:2106.01345.
Chen, Shouyuan, Sherman Wong, Liangjian Chen, and Yuandong Tian. 2023. “Extending Context Window of Large Language Models via Positional Interpolation.” arXiv Preprint arXiv:2306.15595.
Chen, Xi, Josip Djolonga, Piotr Padlewski, Basil Mustafa, Soravit Changpinyo, Jialin Wu, Carlos Riquelme Ruiz, et al. 2023. “PaLI-x: On Scaling up a Multilingual Vision and Language Model.” arXiv Preprint arXiv:2305.18565.
Chollet, François. 2017. “Xception: Deep Learning with Depthwise Separable Convolutions.” arXiv Preprint arXiv:1610.02357.
Chowdhery, Aakanksha, Sharan Narang, Jacob Devlin, Bosma Maarten, Mishra Gaurav, Roberts Adam, Barham Paul, et al. 2022. “PaLM: Scaling Language Modeling with Pathways.” arXiv Preprint arXiv:2204.02311.
Chung, Hyung Won, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Yunxuan Li, et al. 2022. “Scaling Instruction-Finetuned Language Models.” arXiv Preprint arXiv:2210.11416.
Dao, Tri. 2023. “FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning.” arXiv Preprint arXiv:2307.08691.
Dao, Tri, Daniel Y. Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. 2022. “FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness.” arXiv Preprint arXiv:2205.14135.
Dehghani, Mostafa, Anurag Arnab, Lucas Beyer, Ashish Vaswani, and Yi Tay. 2022. “The Efficiency Misnomer.” arXiv Preprint arXiv:2110.12894.
Devlin, Jacob, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. “BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding.” In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), 4171–86.
Dosovitskiy, Alexey, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, et al. 2021. “An Image Is Worth 16x16 Words: Transformers for Image Recognition at Scale.” In International Conference on Learning Representations.
Girdhar, Rohit, Alaaeldin El-Nouby, Zhuang Liu, Mannat Singh, Kalyan Vasudev Alwala, Armand Joulin, and Ishan Misra. 2023. “ImageBind: One Embedding Space to Bind Them All.” arXiv Preprint arXiv:2305.05665.
Graves, Alex, Greg Wayne, and Ivo Danihelka. 2014. “Neural Turing Machines.” arXiv Preprint arXiv:1410.5401.
He, Kaiming, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross Girshick. 2021. “Masked Autoencoders Are Scalable Vision Learners.” arXiv Preprint arXiv:2111.06377.
He, Kaiming, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. “Deep Residual Learning for Image Recognition.” In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 770–78.
Hoffmann, Jordan, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, et al. 2022. “Training Compute-Optimal Large Language Models.” arXiv Preprint arXiv:2203.15556.
Ioffe, Sergey, and Christian Szegedy. 2015. “Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift.” In International Conference on Machine Learning, 448–56.
Le Scao, Teven, Angela Fan, Christopher Akiki, Pavlick Ellie, Ilić Suzana, Hesslow Daniel, Castagné Roman, et al. 2022. “BLOOM: A 176B-Parameter Open-Access Multilingual Language Model.” arXiv Preprint arXiv:2211.05100.
Lewis, Mike, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Veselin Stoyanov, and Luke Zettlemoyer. 2019. “BART: Denoising Sequence-to-Sequence Pre-Training for Natural Language Generation, Translation, and Comprehension.” arXiv Preprint arXiv:1910.13461.
Lewkowycz, Aitor, Anders Andreassen, David Dohan, Ethan Dyer, Henryk Michalewski, Vinay Ramasesh, Ambrose Slone, et al. 2022. “Solving Quantitative Reasoning Problems with Language Models.” arXiv Preprint arXiv:2206.14858.
Liu, Nelson F., Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. 2023. “Lost in the Middle: How Language Models Use Long Contexts.” arXiv Preprint arXiv:2307.03172.
Liu, Yinhan, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. “RoBERTa: A Robustly Optimized BERT Pretraining Approach.” arXiv Preprint arXiv:1907.11692.
Lu, Jiasen, Christopher Clark, Rowan Zellers, Roozbeh Mottaghi, and Aniruddha Kembhavi. 2022. “Unified-IO: A Unified Model for Vision, Language, and Multi-Modal Tasks.” arXiv Preprint arXiv:2206.08916.
Luong, Minh-Thang, Hieu Pham, and Christopher D Manning. 2015. “Effective Approaches to Attention-Based Neural Machine Translation.” arXiv Preprint arXiv:1508.04025.
Mehta, Sachin, and Mohammad Rastegari. 2022. “MobileViT: Light-Weight, General-Purpose, and Mobile-Friendly Vision Transformer.” arXiv Preprint arXiv:2110.02178.
OpenAI. 2023. “GPT-4 Technical Report.” arXiv Preprint arXiv:2303.08774.
Parmar, Niki, Ashish Vaswani, Jakob Uszkoreit, Łukasz Kaiser, Noam Shazeer, Alexander Ku, and Dustin Tran. 2018. “Image Transformer.” In Proceedings of the 35th International Conference on Machine Learning, 4055–64.
Radford, Alec, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, et al. 2021. “Learning Transferable Visual Models from Natural Language Supervision.” In International Conference on Machine Learning, 8748–63.
Radford, Alec, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. 2022. “Robust Speech Recognition via Large-Scale Weak Supervision.” arXiv Preprint arXiv:2212.04356.
Radford, Alec, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. 2018. “Improving Language Understanding by Generative Pre-Training.”
Radford, Alec, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. 2019. “Language Models Are Unsupervised Multitask Learners.” OpenAI Blog 1 (8).
Raffel, Colin, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. 2019. “Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer.” arXiv Preprint arXiv:1910.10683.
Ramesh, Aditya, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. 2022. “Hierarchical Text-Conditional Image Generation with CLIP Latents.” arXiv Preprint arXiv:2204.06125.
Reed, Scott, Konrad Zolna, Emilio Parisotto, Sergio Gomez Colmenarejo, Alexander Novikov, Gabriel Barth-Maron, Mai Gimenez, et al. 2022. “A Generalist Agent.” arXiv Preprint arXiv:2205.06175.
Rombach, Robin, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. 2022. “High-Resolution Image Synthesis with Latent Diffusion Models.” In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 10684–95.
Singhal, Karan, Shekoofeh Azizi, Tao Tu, S Sara Mahdavi, Jason Wei, Hyung Won Chung, Nathan Scales, et al. 2022. “Large Language Models Encode Clinical Knowledge.” arXiv Preprint arXiv:2212.13138.
Srivastava, Nitish, Geoffrey Hinton, Alex Krizhevsky, Ilya Sutskever, and Ruslan Salakhutdinov. 2014. “Dropout: A Simple Way to Prevent Neural Networks from Overfitting.” Journal of Machine Learning Research 15 (56): 1929–58.
Steiner, Andreas, Alexander Kolesnikov, Xiaohua Zhai, Ross Wightman, Jakob Uszkoreit, and Lucas Beyer. 2021. “How to Train Your ViT? Data, Augmentation, and Regularization in Vision Transformers.” arXiv Preprint arXiv:2106.10270.
Sun, Chen, Abhinav Shrivastava, Saurabh Singh, and Abhinav Gupta. 2017. “Revisiting Unreasonable Effectiveness of Data in Deep Learning Era.” In Proceedings of the IEEE International Conference on Computer Vision, 843–52.
Sun, Simeng, Kalpesh Krishna, Andrew Mattarella-Micke, and Mohit Iyyer. 2021. “Do Long-Range Language Models Actually Use Long-Range Context?” In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP), 807–22. Online; Punta Cana, Dominican Republic: Association for Computational Linguistics. https://doi.org/10.18653/v1/2021.emnlp-main.62.
Tay, Yi, Mostafa Dehghani, Dara Bahri, and Donald Metzler. 2020. “Efficient Transformers: A Survey.” arXiv Preprint arXiv:2009.06732.
Tay, Yi, Mostafa Dehghani, Vinh Q Tran, Xavier Garcia, Jason Wei, Xuezhi Wang, Hyung Won Chung, et al. 2022. “UL2: Unifying Language Learning Paradigms.” arXiv Preprint arXiv:2205.05131.
Taylor, Ross, Marcin Kardas, Guillem Cucurull, Thomas Scialom, Anthony Hartshorn, Elvis Saravia, Andrew Poulton, Viktor Kerkez, and Robert Stojnic. 2022. “Galactica: A Large Language Model for Science.” arXiv Preprint arXiv:2211.09085.
Touvron, Hugo, Matthieu Cord, Alaaeldin El-Nouby, Piotr Bojanowski, Armand Joulin, Gabriel Synnaeve, and Hervé Jégou. 2021. “Augmenting Convolutional Networks with Attention-Based Aggregation.” arXiv Preprint arXiv:2112.13692.
Touvron, Hugo, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, et al. 2023. “LLaMA: Open and Efficient Foundation Language Models.” arXiv Preprint arXiv:2302.13971.
Vaswani, Ashish, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and Illia Polosukhin. 2017. “Attention Is All You Need.” arXiv Preprint arXiv:1706.03762.
Vig, Jesse. 2019. “A Multiscale Visualization of Attention in the Transformer Model.” In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics: System Demonstrations, 37–42.
Wang, Guangyu, Guoxing Yang, Zongxin Du, Longjun Fan, and Xiaohu Li. 2023. “ClinicalGPT: Large Language Models Finetuned with Diverse Medical Data and Comprehensive Evaluation.” arXiv Preprint arXiv:2306.09968.
Wang, Peng, An Yang, Rui Men, Junyang Lin, Shuai Bai, Zhikang Li, Jianxin Ma, Chang Zhou, Jingren Zhou, and Hongxia Yang. 2022. “OFA: Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence Learning Framework.” In Proceedings of the 39th International Conference on Machine Learning, 23318–40. PMLR.
Wang, Zirui, Jiahui Yu, Adams Wei Yu, Zihang Dai, Yulia Tsvetkov, and Yuan Cao. 2021. “SimVLM: Simple Visual Language Model Pretraining with Weak Supervision.” arXiv Preprint arXiv:2108.10904.
Wei, Jason, Max Nye, and Percy Liang. 2022. “Chain-of-Thought Prompting Elicits Reasoning in Large Language Models.” arXiv Preprint arXiv:2201.11903.
Wei, Jason, Yi Tay, Rishi Bommasani, Colin Raffel, Barret Zoph, Sebastian Borgeaud, Dani Yogatama, et al. 2022. “Emergent Abilities of Large Language Models.” arXiv Preprint arXiv:2206.07682.
Wei, Jerry, Jason Wei, Yi Tay, Dustin Tran, Albert Webson, Yifeng Lu, Xinyun Chen, et al. 2023. “Larger Language Models Do in-Context Learning Differently.” arXiv Preprint arXiv:2303.03846.
Wolf, Thomas, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, et al. 2020. “Transformers: State-of-the-Art Natural Language Processing.” In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, 38–45. Online: Association for Computational Linguistics. https://doi.org/10.18653/v1/2020.emnlp-demos.6.
Wu, Shijie, Ozan Irsoy, Steven Lu, Vadim Dabravolski, Mark Dredze, Sebastian Gehrmann, Prabhanjan Kambadur, David Rosenberg, and Gideon Mann. 2023. “BloombergGPT: A Large Language Model for Finance.” arXiv Preprint arXiv:2303.17564.
Xie, Shufang, Huishuai Zhang, Junliang Guo, Xu Tan, Jiang Bian, Hany Hassan Awadalla, Arul Menezes, Tao Qin, and Rui Yan. 2023. “ResiDual: Transformer with Dual Residual Connections.” arXiv Preprint arXiv:2304.14802.
Xiong, Ruibin, Yunchang Yang, Di He, Kai Zheng, Shuxin Zheng, Chen Xing, Huishuai Zhang, Yanyan Lan, Liwei Wang, and Tie-Yan Liu. 2020. “On Layer Normalization in the Transformer Architecture.” In International Conference on Machine Learning, 10524–33.
Xu, Kelvin, Jimmy Ba, Ryan Kiros, Kyunghyun Cho, Aaron Courville, Ruslan Salakhutdinov, Richard S Zemel, and Yoshua Bengio. 2015. “Show, Attend and Tell: Neural Image Caption Generation with Visual Attention.” In International Conference on Machine Learning, 2048–57.
Xue, Linting, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, and Colin Raffel. 2021. “mT5: A Massively Multilingual Pre-Trained Text-to-Text Transformer.” In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 483–98.
Yang, Hongyang, Xiao-Yang Liu, and Christina Dan Wang. 2023. “FinGPT: Open-Source Financial Large Language Models.” arXiv Preprint arXiv:2306.06031.
Yang, Jingfeng, Hongye Jin, Ruixiang Tang, Xiaotian Han, Qizhang Feng, Haoming Jiang, Bing Yin, and Xia Hu. 2023. “Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond.” arXiv Preprint arXiv:2304.13712.
Zhang, Xiang, and Yann LeCun. 2015. “Text Understanding from Scratch.” arXiv Preprint arXiv:1502.01710.
Zhang, Yiyuan, Kaixiong Gong, Kaipeng Zhang, Hongsheng Li, Yu Qiao, Wanli Ouyang, and Xiangyu Yue. 2023. “Meta-Transformer: A Unified Framework for Multimodal Learning.” arXiv Preprint arXiv:2307.10802.
- Example adapted from Deep Learning with Python by Francois Chollet↩︎
- In the transformer paper, MLPs are what referred to as feed-forward networks(FFNs). I find the terminology of FFNs confusing sometime. MLPs are feed-forward networks but not the other way around.↩︎
- If you want to see how embeddings look like and how words with same semantic meaning tend to be closer to each other, you can play with Embedding Projector↩︎
- The core operation in attention is the dot product between query and keys, which, being a summation operation, is permutation invariant↩︎
- Hat tip to Sebastian Raschka for sharing this in his newsletter↩︎
- BertViz be accessed at https://github.com/jessevig/bertviz[↩︎](https://deeprevision.github.io/posts/001-transformer/#fnref6)
- Karpathy said that in a Twitter thread. Available here: https://twitter.com/karpathy/status/1655994367033884672?s=20[↩︎](https://deeprevision.github.io/posts/001-transformer/#fnref7)
- Next sentence prediction in BERT and next token prediction in standard transformer are different. The idea is roughly similar, but the former is usually for discriminative modelling while the later is for auto-regressive generative modelling↩︎
- Next token prediction in decoder LLMs is different to next sentence prediction in BERT. The former operates on token level while the later operates on sentence level↩︎
- It’s fair to say that GPT-3 popularized prompt engineering.↩︎
- The inductive biases in ConvNets are the results of their translation invariance. Convolution itself is translation equivariance(changing the position of pixels changes the output) but pooling which is often used after convolution is translation invariant(changing the position of pixels doesn’t change the output) and this make the overall ConvNets translation invariant architecture↩︎
- GPU main memory is called HBM which stands for High Bandwidth Memory↩︎
- Available at https://github.com/tensorflow/tensor2tensor[↩︎](https://deeprevision.github.io/posts/001-transformer/#fnref13)
- Available at https://github.com/google/trax[↩︎](https://deeprevision.github.io/posts/001-transformer/#fnref14)
原文:The Transformer Blueprint: A Holistic Guide to the Transformer Neural Network Architecture