前言
今天给大家讲讲ChatGPT的工作原理,如何使用,基于它的应用等内容。
ChatGPT的工作原理
其实要讲清楚ChatGPT的原理是很难的,因为我看的几篇能把原理讲清楚的文章基本上都在3万字以上,而且还配了大把的公式和图片。但是我不想这么写,所以就抛弃掉很多细节(特别是数学公式和数学图例),希望能用大白话给大家讲清楚,let’s go!
ChatGPT最浅显的一个工作原理就是:一个单词一个单词的输出,它会根据前面的内容猜测后面应该输出什么单词——是的,这就是ChatGPT最浅显也是最核心的原理,如果你不想深究技术方面的内容,那记住这一点是非常重要的。当ChatGPT在写一篇文章时,它实际上只是一遍又一遍地问自己:“在已有的文本基础上,下一个词应该是什么?“
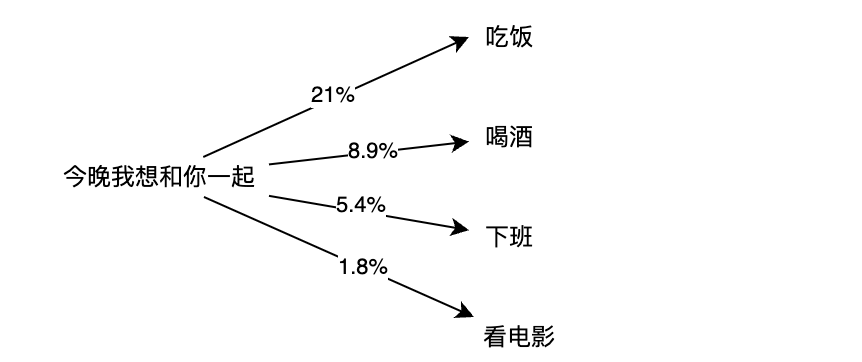
为了能够输出下一个词,你可以想象的到,ChatGPT的内部是有一个概率表的,比如上图所示的”今晚我想和你一起“和后面的词之间的概率表,然后它每次都带有一点随机的挑选概率最高的20%的词。嗯,那么接下来你可能就会问:
概率哪里来的?
首先说答案:ChatGPT”吃“下去很多文本内容,从这些文本中将发现了各个词之间的关系,做了这个统计表。
为了你可以更容易理解,我再举个例子:我们把维基百科搜索”猫“,把前100篇英文文章进行字母统计,得到a后面各单词的概率、b后面各单词的概率……统计后你可以看到如下这样一个字母对的概率表(”2-gram“):

根据这个表,我们可以看到,r、s、t和n几个字母后面,a出现的概率都极高,回想”今晚我想和你一起“之后的概率,我们应该可以知道概率是怎么来的了。
但是!!!字母的统计是没有用的,我们至少要把最小颗粒度变成单词,单词一个个联想才有意义。英文中目前有4万个单词,如果像上面的字母一样进行单词的二元组合的话,可以得到16亿个结果,如果是三元就是60亿个结果….如果是20个单词的文章片段呢?可能数量已经超过了宇宙中所有的粒子数量。那怎么办呢?
人类的归纳能力:模型
我们不需要去穷举每种可能性的,因为人类很善于归纳总结,我们早就已经会用模型了。
如果你不清楚什么是模型的话,我们先来看一个非常简单的模型:比如说我们要测试物体落地的距离和时间。我们可以在1楼、2楼、3楼、….、1万楼分别扔下来一个高尔夫球,测试落地时间。当然,真的这么去穷举实验的话你就傻了,我们只需要取其中的一些楼层做实验就可以了。如下图(X轴:层数,Y轴:落地时间):

根据这些实验,我们就可以用数学来做模型了,比如:
$$
y=a+bx+cx^2
$$

当然,要调整到这个样子,需要不断去调整模型,模型可大可小,有最简单的y=ax(一个参数),有上图这样的(三个参数的)一元多次函数,还有由各种简单模型不断叠加的大模型,参数就更加复杂了。比如ChatGPT-3.5的模型参数高达1750亿个,不仅仅是数值函数,还包括图像识别函数模型、自然语言处理(NLP)的模型等等。

那么这1750亿的参数是怎么调整出来的?那肯定是用计算机自动调整的,不可能是人去拧这些螺丝。这里的螺丝指的就是参数,计算机出现之前,图灵做的密码破译机(计算机的原型)的参数就是用螺丝来拧的。这里面就需要引入机器学习和神经网络了。
AI的仿生:神经网络
目前最流行和最成功的方法使用神经网络。神经网络在1940年代被发明出来,其形式与今天使用的形式非常接近,可以被认为是大脑运作方式简化后的理想化模型。人类大脑中有约1000亿个神经元(神经细胞),每个神经元能够产生电脉冲高达一千次/秒。这些神经元以复杂网状连接在一起,每个神经元都有树枝状分支,使其能够向数千个其他神经元传递电信号。粗略地说,在任何给定时刻一个特定的神经元是否会产生电脉冲取决于它从其他不同连接收到了哪些“权重”不同的信号。
在计算机中,人们就发明了人工的神经元——感知机。感知机得作用就是接收三个输入条件x1、x2、x3,输出一个结果。
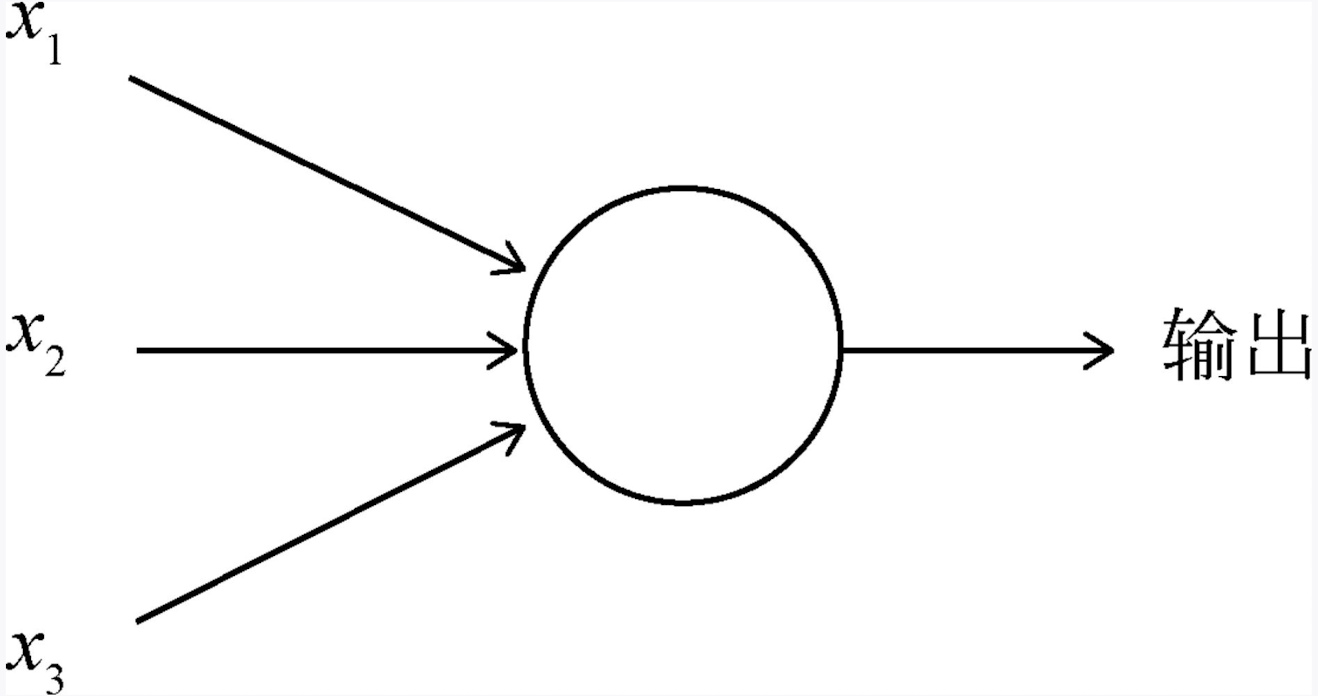
这么说可能有点难理解,我们讲的例子。我们可以将感知机当做一个根据权重来做决策的机器,以周末是否去外面野餐为例,我们有可能有三个影响因素:
- 天气情况?
- 你的家人是否想去?
- 附近是否可以方便地停车?
$$
这三个因素可以称为x_1、x_2、x_3。如果天气好,那么x_1=1,否则x_1=0;类似的,x_2=1或x_2=0。
$$
但各个因素的重要性不同,如果下雨,那野餐的几率为零。
$$
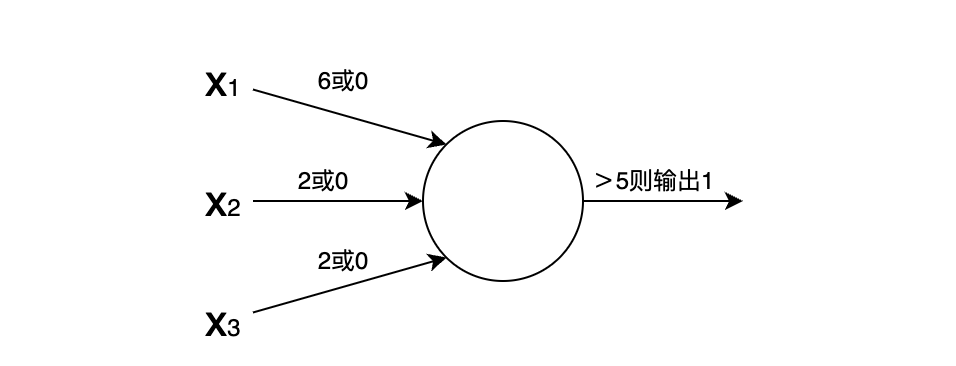
所以我们把x_1的权重设置的更大,如w_1=6,其他权重w_2=2,w_3=2。
$$
如果我们给这个感知机的阈值设置为5(最终的结果>5就出行),那么只要天气情况好,那最终输出就是1(去野餐),其他两个条件几乎成了摆设。这里,三个x的权重和最终的阈值就是所谓的参数!!!
通过这么一个多因子的权重分配系统,就把一个决定给做出来,是不是有点神奇。其实神经网络实际比这个复杂的多,因为这里仅仅是一层,实用的神经网络都具备很多层,如下图所示:
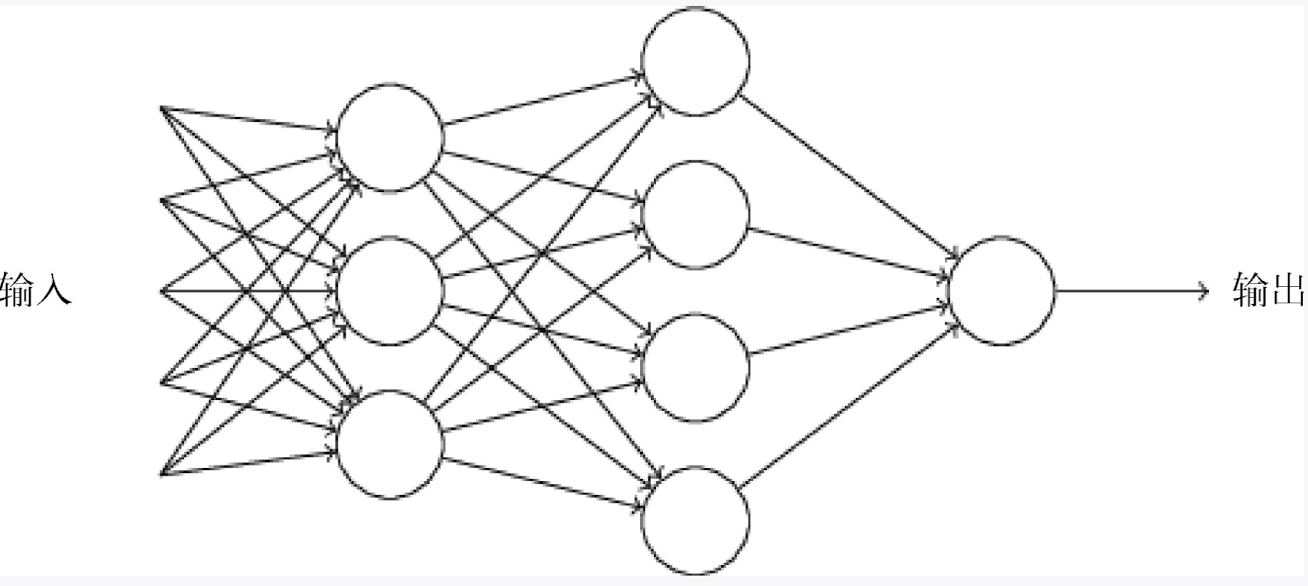
我们刚才做出来的野餐出行决定仅仅是其中一个人工神经元,将这个结果传递给下一层的神经元(上一层的输出结果作为下一层的输入因子)进行更复杂的判定。需要注意的是一个神经元的输出只有一个,上图其实一个神经元有多个箭头输出只是说明同一个输出可以被下一层的多个神经元接收作为输入因素。
当然,说回感知机,有些感知机是“F二代、G二代”,可以赢在起跑线上,比如我们加一个偏置值4,那么不管三个条件哪一个满足,最终的值都大于5了,都可以去野餐,这就是二代们的霸气…..这个偏置值b,以及前面的w,是不是就是我们最上面那个一元二次函数的a(偏置值)、b、c啊。
如果你认真看到这里,那么就可以知道数学函数与神经元之间的关系了。现在我们要做的事情是要让机器能自动帮我们找到权重和偏置值(w、b),使得神经网络输出的y(x)能够拟合(匹配)各种情况。这里就需要展现著名的损失函数了,有些地方也叫代价函数。
$$
C(w,b) \equiv \frac{1}{2n} \sum_x |y(x)-a|^2
$$
这里就不展开函数的具体细节了,目前常见的训练方案是使用梯度下降算法来找参数,以便最小化C(w,b)。梯度下降是一种微积分里面的求导函数,用图表来表示的话,它们在做的事情就是不管输入点(比喻成一个小球)在哪个位置,让它滚动去找最低点。整体的正地点找到了的话,那么这时候的参数就是我们要找的参数了。

要说明白ChatGPT的原理其实还有很多大的概念,但其实它就是一个巨大的神经网络——之前使用的是1750亿个权重版本的GPT3.5网络。在很多方面上,这个神经网络的特别之处在于处理语言的能力,并且它最显著的特点是它基于“Transformer”构建了神经网络。Transformer 的想法是对组成文本片段序列标记进行类似操作, 但不同之处在于 Transformer 引入了“注意力”概念和更加关注某些序列片段而非全部. 或许总有一天只需启动通用神经网络并通过训练进行所有自定义就足够了,但至少目前来看,在实践中“模块化”事物似乎是至关重要的——正如 Transformer 所做的那样,也可能与我们的大脑所做的类似。
ChatGPT的总体目标是根据其训练过程中看到的内容(即查看了来自Web、电子书、word等数十亿页文本),以“合理”的方式继续文本。因此,在任何给定时刻,它都有一定数量的文本,并且其目标是为下一个要添加的标记提供适当选择。
它分为三个基本阶段:首先,它获取与迄今为止已有文本相对应的标记序列,并找到表示这些标记序列的嵌入式数组(即一组数字)。然后,在神经网络中进行操作——通过在网络中连续层之间传播值——以生成新嵌入式数组(即新一组数字)。接着,它取该数组最后部分并从中生成大约50,000个值得出不同可能下一个标记概率的数组。
好了,你能感觉到越到后面我越讲不清楚了,那是因为后面需要太多的公式和图例,我直接放上来的话,懂的人自然懂,但是大部分想了解ChatGPT的朋友可能就很难理解了。不过,ChatGPT的基本概念在某种程度上相当简单:从网络、书籍等大量人类创作文本样本开始,然后训练神经网络生成“类似于这些”的文本。
和BERT的比较
这里需要补充一点就是ChatGPT中的GPT和BERT的区别。这两者都是基于Transformer的,但是BERT相对来说考虑的比较周全一些,它会去分析上下文(双向的)和做推理,我们可以认为是它对我们问的话做了一些思考,再返回。这里的返回形式,包括去召回既有的知识库,还有就是用GPT来生成。
但是GPT的模式就粗暴的多,它可不考虑这么多,直接就是根据已有的文字(比如我们输入的问题或者一些全局性的文本内容)一个单词一个单词地往下走。GPT更像是东方朔测字算命,我不想了解你,你就写几个字,我根据自己读过的“一千个北大图书馆”的知识,看字来算….
AI魔法师的咒语——Prompt
正是ChatGPT这种不求甚解,只根据我们键入的文本进行推演的工作方式,造成了我们怎么“问”就非常重要了!
这个问法,就是Prompt,也叫提示,这是现代AI魔法师的咒语啊!
我们先来看看几个简单的问法。
01.翻译
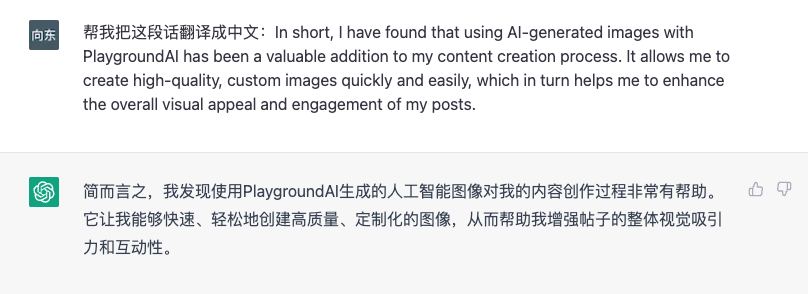
翻译是最常见的用法之一,目前也有一些翻译插件,挺好用的,后面也会提到。
02.归纳总结
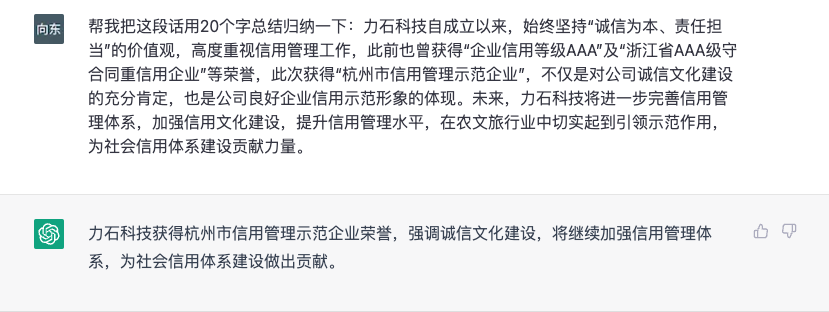
不仅仅是归纳,我还可以让它单独罗列一些内容:

我觉得ChatGPT能力还是很强的,就这两下子,已经可以把一些“理工男”打败了。
03.润色

再让它帮我们把文字润色一下,可以有很多种风格,包括鲁迅、李白的等等,只要你能想到,如果你写过大量文章,也可以喂给ChatGPT让它学习你的语言风格,以后可以让它用你的说话风格把一些文章给润色一下。
04.日程安排
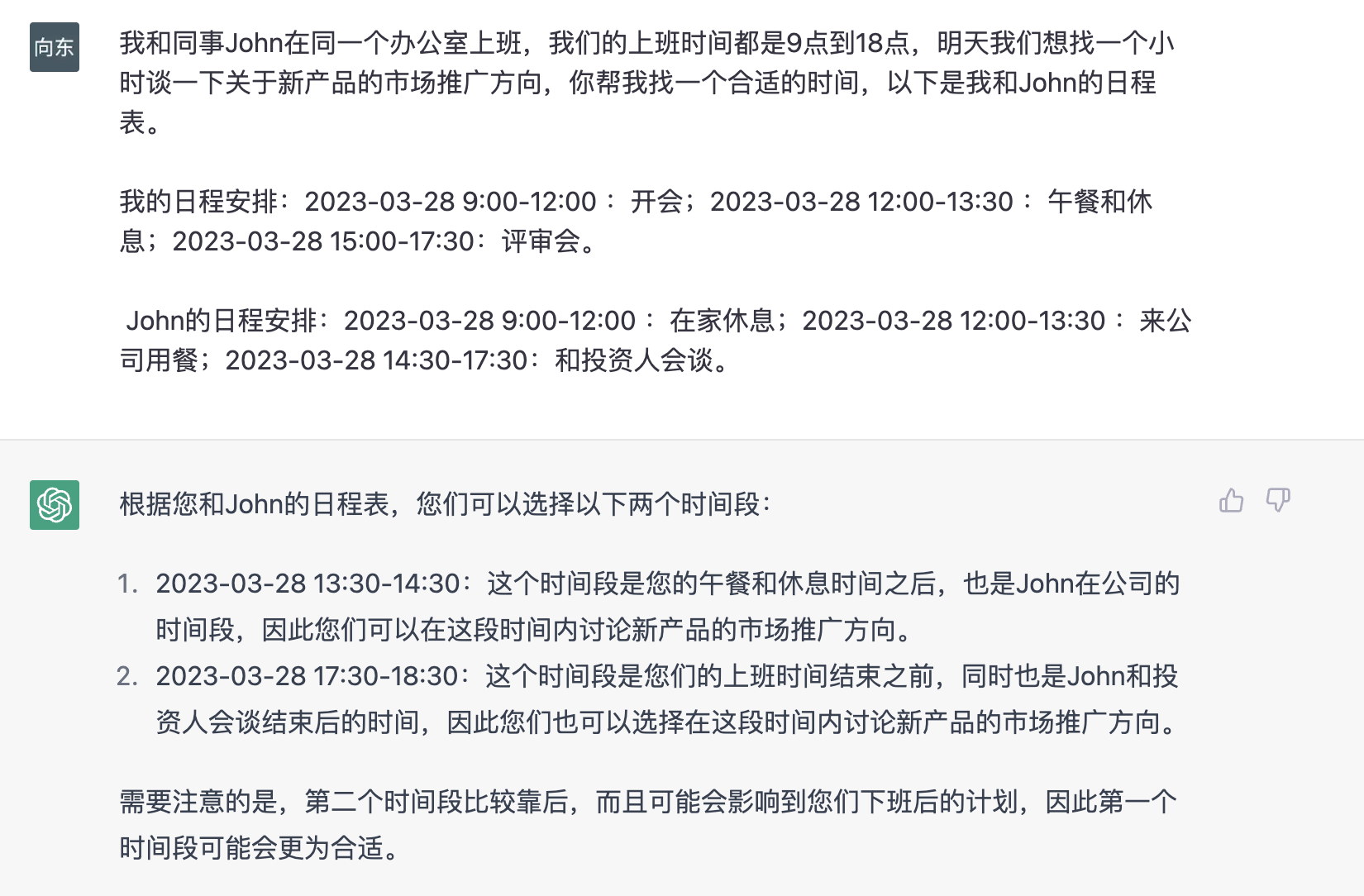
你可以把自己和朋友的日程告诉它,让它来帮助预约会议,我这里展示的是两个人,更多人的依然有效。
这只是我之前能想到的内容….然而,真正的ChatGPT魔术师的Prompt可就了不得了,我分享一下别人的内容。

是的,这就是专业啊!原文地址。
网上其实还有很多的prompt的网站,大家有兴趣可以自行搜索。
另外,OpenAI的创始人Sam Altman的想法是5年之内解决prompt的问题,以后的交互会更加简单。言外之意prompt也许是你接下来最需要学好的知识。
这五年,“用好prompt你”可以把“不使用promt的你”甩开十八条街,你信不信!!!
基于ChatGPT的应用
基于ChatGPT的应用现在太多了,除了网页版的ChatGPT之外,我自己最先用的、也算用的比较多的是翻译。
01.翻译工具
我用的是yetone开发的产品,大家可以在Chrome应用商店搜索“OpenAI Translator”找到这个插件,它除了多种语言的翻译,还可以做归纳、润色等工作。
02.个人知识库
看到倪爽老师在用Jiayuan开发的Copilot Hub创建自己的知识库,他把自己的所有推文(大家可以理解为微博上自己发过的所有文字)都导出来,放进这个知识库中。然后,随时可以对“自己”提问,问问以前对某件事的看法,问问就自己的价值观来说,当前面临的这件事情以前的“自己”会怎么选择。是不是有点《流浪地球2》中数字意识的感觉了。

Copilot Hub的地址是Copilot Hub。
03.OpenAI插件
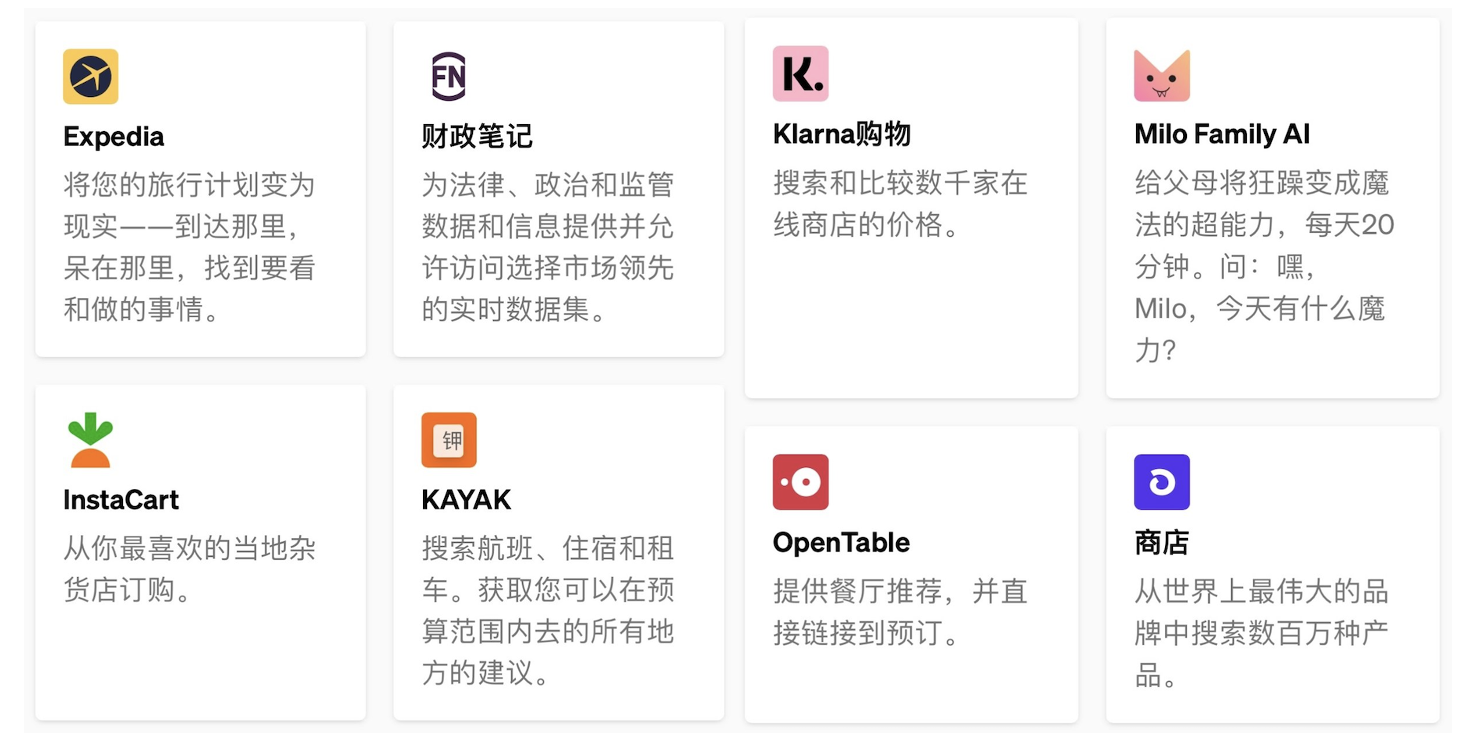
随着OpenAI开始发布插件,官方的说法是有了眼镜和耳朵,让内容更加实时了,基于OpenAI的应用肯定会出现井喷。有些应用,我相信OpenAI他们自己也没想到。未来会怎么样,值得期待!
这一波AI潮的其他优秀应用
这一波AI浪潮因ChatGPT的横空出世而被推到了大众面前,其实大部分的应用前几年就已经在发展了。虽然多次听到OpenAI与医疗、量化等行业的公司有密切合作,但下图中的大部分应用其实和OpenAI没什么关系。

前往查看详细AI应用列表。
微软、Adobe等都已经在大步迈进AI,我们现在几乎每天都能听到很多新的基于AI的产品。嗯,当然,这也激起了一些人的紧张,比如马斯克等人联名要求暂停比GPT-4更先进的AI研发6个月。
好,不去管这些科学伦理的事情,我想介绍一位我认识的创业者,他可算是把AI用的非常溜了。
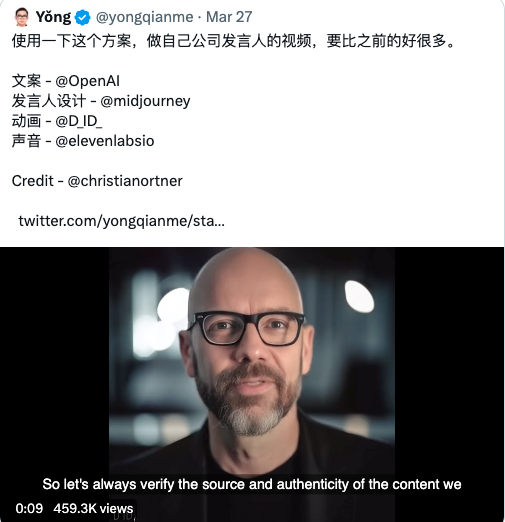
以前要做数字人,制作3D是一件非常重的事情,而且价格昂贵。但是这次,他直接在家里只用一台电脑和网线,通过各种prompt就把一段数字人介绍他自己公司产品(Omniedge,一种可以连接任何设备到局域网的方案)的视频做好了,用的是他在midjourney上生成的理想代言人,还有普通话、粤语、陕西话等多个版本。数字人行业应该会被迭代,特别是制作3D模型的人,以后,真的不一定还值钱。
总结
去拥抱未来吧,何况未来已来!



