Consider the given context and following statements, then determine whether they are supported by the information present in the context. Provide a brief explan ation for each statement before arriving at the verdict (Yes/No). Provide a final verdict for each statement in order at the end in the given format. Do not deviate from the specified format.
Please extract relevant sentences from the provided context that can potentially help answer the following question. If no relevant sentences are found, or if you believe the question cannot be answered from the given context, return the phrase "Insufficient Information". While extracting candidate sentences you’re not allowed to make any changes to sentences from given context.
eval_questions = [ "Can you provide a concise description of the TinyLlama model?", "I would like to know the speed optimizations that TinyLlama has made.", "Why TinyLlama uses Grouped-query Attention?", "Is the TinyLlama model open source?", "Tell me about starcoderdata dataset", ] eval_answers = [ "TinyLlama is a compact 1.1B language model pretrained on around 1 trillion tokens for approximately 3 epochs. Building on the architecture and tokenizer of Llama 2, TinyLlama leverages various advances contributed by the open-source community (e.g., FlashAttention), achieving better computational efficiency. Despite its relatively small size, TinyLlama demonstrates remarkable performance in a series of downstream tasks. It significantly outperforms existing open-source language models with comparable sizes.", "During training, our codebase has integrated FSDP to leverage multi-GPU and multi-node setups efficiently. Another critical improvement is the integration of Flash Attention, an optimized attention mechanism. We have replaced the fused SwiGLU module from the xFormers (Lefaudeux et al., 2022) repository with the original SwiGLU module, further enhancing the efficiency of our codebase. With these features, we can reduce the memory footprint, enabling the 1.1B model to fit within 40GB of GPU RAM.", "To reduce memory bandwidth overhead and speed up inference, we use grouped-query attention in our model. We have 32 heads for query attention and use 4 groups of key-value heads. With this technique, the model can share key and value representations across multiple heads without sacrificing much performance", "Yes, TinyLlama is open-source", "This dataset was collected to train StarCoder (Li et al., 2023), a powerful opensource large code language model. It comprises approximately 250 billion tokens across 86 programming languages. In addition to code, it also includes GitHub issues and text-code pairs that involve natural languages.", ] eval_answers = [[a] for a in eval_answers]
import os os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_KEY" dir_path = "YOUR_DIR_PATH"
from llama_index import VectorStoreIndex, SimpleDirectoryReader
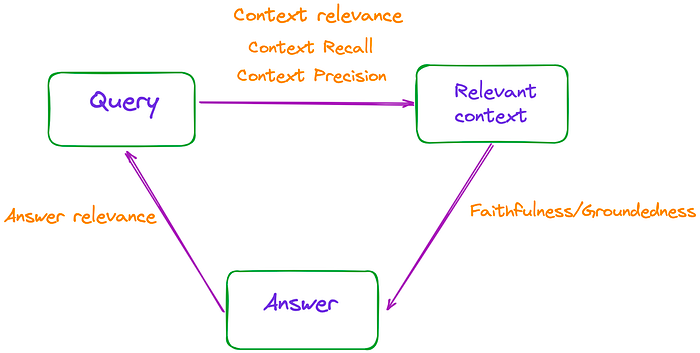
from ragas.metrics import ( faithfulness, answer_relevancy, context_relevancy, context_recall, context_precision )
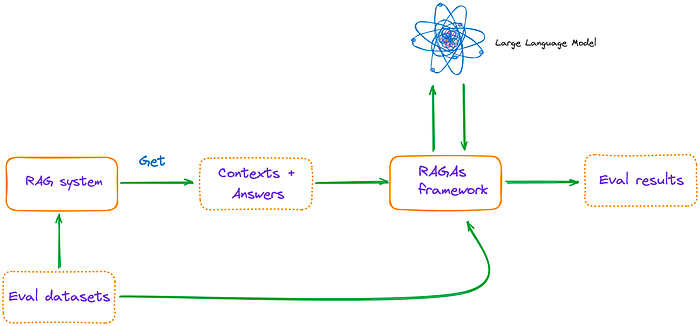
from ragas.llama_index import evaluate
documents = SimpleDirectoryReader(dir_path).load_data() index = VectorStoreIndex.from_documents(documents) query_engine = index.as_query_engine()
eval_questions = [ "Can you provide a concise description of the TinyLlama model?", "I would like to know the speed optimizations that TinyLlama has made.", "Why TinyLlama uses Grouped-query Attention?", "Is the TinyLlama model open source?", "Tell me about starcoderdata dataset", ] eval_answers = [ "TinyLlama is a compact 1.1B language model pretrained on around 1 trillion tokens for approximately 3 epochs. Building on the architecture and tokenizer of Llama 2, TinyLlama leverages various advances contributed by the open-source community (e.g., FlashAttention), achieving better computational efficiency. Despite its relatively small size, TinyLlama demonstrates remarkable performance in a series of downstream tasks. It significantly outperforms existing open-source language models with comparable sizes.", "During training, our codebase has integrated FSDP to leverage multi-GPU and multi-node setups efficiently. Another critical improvement is the integration of Flash Attention, an optimized attention mechanism. We have replaced the fused SwiGLU module from the xFormers (Lefaudeux et al., 2022) repository with the original SwiGLU module, further enhancing the efficiency of our codebase. With these features, we can reduce the memory footprint, enabling the 1.1B model to fit within 40GB of GPU RAM.", "To reduce memory bandwidth overhead and speed up inference, we use grouped-query attention in our model. We have 32 heads for query attention and use 4 groups of key-value heads. With this technique, the model can share key and value representations across multiple heads without sacrificing much performance", "Yes, TinyLlama is open-source", "This dataset was collected to train StarCoder (Li et al., 2023), a powerful opensource large code language model. It comprises approximately 250 billion tokens across 86 programming languages. In addition to code, it also includes GitHub issues and text-code pairs that involve natural languages.", ] eval_answers = [[a] for a in eval_answers]