作为人类,我们可以阅读和理解文本(至少其中一些文本)。相反,计算机“用数字思考”,所以它们不能自动掌握单词和句子的意思。如果我们想让计算机理解自然语言,我们需要将这些信息转换成计算机可以处理的格式——数字向量。
许多年前,人们就学会了如何将文本转换为机器可理解的格式(最早的版本之一是ASCII)。这种方法有助于呈现和传输文本,但不编码单词的含义。当时,标准的搜索技术是搜索包含特定单词或N-gram的所有文档时使用的关键字搜索。
然后,几十年后,Embeddings出现了。我们可以计算单词、句子甚至图像的Embeddings。Embeddings也是数字向量,但它们可以捕捉到含义。因此,您可以使用它们进行语义搜索,甚至处理不同语言的文档。
在本文中,我想更深入地探讨Embedding主题并讨论所有细节:
- 在Embeddings之前是什么以及它们是如何进化的,
- 如何使用OpenAI工具计算Embeddings,
- 如何定义句子是否彼此接近,
- 如何可视化Embeddings,
- 最令人兴奋的部分是如何在实践中使用Embeddings。
让我们继续了解Embeddings的演变。
Embeddings的演变
我们将以简要介绍文本表示的历史开始我们的旅程。
词袋
将文本转换为矢量的最基本方法是一个单词包。让我们来看看理查德·费曼的一句名言:“We are lucky to live in an age in which we are still making discoveries。”我们将用它来说明一个词袋方法。
获得一袋单词向量的第一步是将文本分成单词或短句(tokens),然后将单词约简为基本形式。例如,“running”将转换为“run”。这个过程称为词干提取。我们可以使用NLTK Python包。
1 | from nltk.stem import SnowballStemmer |
现在,我们有了所有单词的基本形式的列表。下一步是计算它们的频率来创建一个向量。
1 | import collections |
实际上,如果我们想把文本转换成向量,我们不仅要考虑文本中的单词,还要考虑整个词汇表。假设我们的词汇表中还有“i”、“you”和“study”,让我们根据费曼的话创建一个向量。

这种方法非常基础,它没有考虑到单词的语义含义,所以句子“the girl is studying data science”和“the young woman is learning AI and ML”不会彼此接近。
TF-IDF
单词包方法的一个稍微改进的版本是TF-IDF (Term Frequency - Inverse Document Frequency)。它是两个度量的乘法。
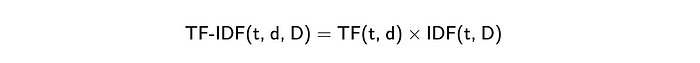
- Term Frequency(词频) 显示单词在文档中出现的频率。最常见的计算方法是将文档中术语的原始计数(如单词包中的术语)除以文档中术语(单词)的总数。然而,还有许多其他方法,如原始计数、布尔“频率”和不同的归一化方法。您可以在[Wikipedia](https://en.wikipedia.org/wiki/Tf -idf)上了解更多关于不同方法的信息。

- Inverse Document Frequency(逆文档频率) 表示单词提供的信息量。例如,单词“a”或“that”并不能提供关于文档主题的任何附加信息。相反,像“ChatGPT”或“生物信息学”这样的词可以帮助你定义领域(但不适用于这句话)。它被计算为文档总数与包含该单词的文档总数之比的对数。IDF越接近0——这个词越常见,它提供的信息就越少。

因此,最后,我们将得到一些向量,其中常见单词(如“I”或“you”)的权重较低,而在文档中多次出现的罕见单词的权重较高。这种策略会得到更好的结果,但它仍然不能捕获语义。
这种方法的另一个挑战是它产生的向量非常稀疏。向量的长度等于语料库的大小。英语中大约有470K个独特的单词(来源),所以我们将有巨大的向量。由于句子中不超过50个唯一的单词,因此向量中99.99%的值将为0,不编码任何信息。看到这里,科学家们开始考虑密集向量表示。
Word2Vec
最著名的密集表示方法之一是word2vec,由Google于2013年在Mikolov等人的论文effective Estimation of Word Representations in Vector Space中提出。
文中提到了两种不同的word2vec方法:CBOW(当我们根据周围的词来预测单词时)和Skip-gram(相反的任务-当我们根据单词来预测上下文时)。
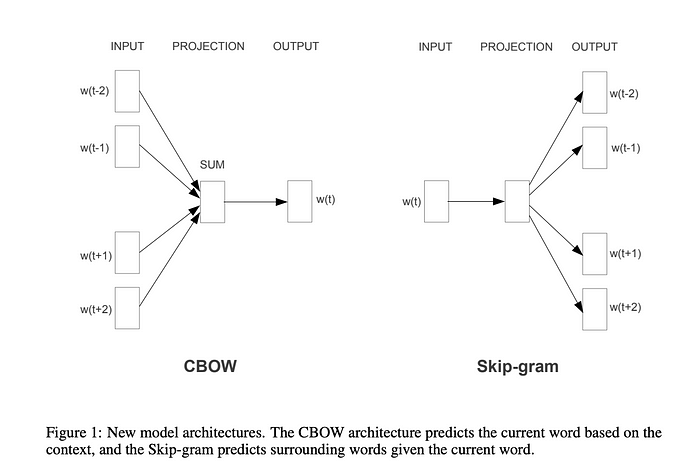
Figure from the paper by Mikolov et al. 2013 | source
密集向量表示的高级思想是训练两个模型:encoder和decoder。例如,在skip-gram的情况下,我们可能会将单词“christmas”传递给encoder。然后,encoder将产生一个向量,我们将其传递给decoder,期望得到单词“merry”,“to”和“you”。

Scheme by author
这个模型开始考虑单词的意思,因为它是根据单词的上下文进行训练的。然而,它忽略了词法(我们可以从单词部分获得的信息,例如,“-less”表示缺少某物)。这个缺点后来通过查看GloVe中的子词skip-gram来解决。
此外,word2vec只能处理单词,但我们想要编码整个句子。所以,让我们继续下一个与Transformers进化的步骤。
Transformers和句子Embeddings
下一个进化与Vaswani等人在“Attention Is All You Need”论文中介绍的Transformers方法有关。Transformers能够产生信息覆盖的密集向量,成为现代语言模型的主导技术。
我不会涉及Transformers架构的细节,因为它与我们的主题不太相关,而且会花费很多时间。如果你有兴趣了解更多,有很多关于Transformers的材料,例如,“Transformers, Explained”或“The Illustrated Transformer”。
Transformers允许您使用相同的“核心”模型,并针对不同的用例对其进行微调,而无需重新训练核心模型(这需要花费大量时间和相当昂贵)。这导致了预训练模型的兴起。最早流行的模型之一是谷歌AI的BERT(来自Transformers的双向编码器表示)。
在内部,BERT仍然在类似于word2vec的token级别上操作,但我们仍然希望得到句子Embeddings。简单的方法是取所有tokens向量的平均值。不幸的是,这种方法没有表现出良好的性能。
这个问题在2019年Sentence-BERT发布后得到了解决。它优于所有以前的方法语义文本相似性任务,并允许计算句子Embeddings。
这是一个很大的主题,所以我们无法在本文中涵盖所有内容。所以,如果你真的感兴趣,你可以在这篇文章中了解更多关于句子Embeddings的知识。
我们简要介绍了Embeddings的演变,并对该理论有了高层次的理解。现在,是时候继续练习并学习如何使用OpenAI工具计算Embeddings。
计算Embeddings
在本文中,我们将使用OpenAIEmbeddings。我们将尝试最近发布的新模型text-embeddings-3-small 与text-embeddings-ada-002 相比,新模型显示出更好的性能:
OpenAI还发布了一个新的更大的模型text-embedding-3-large。现在,这是他们表现最好的Embedding模型。
作为数据源,我们将使用Stack Exchange data Dump的一个小样本——一个在Stack Exchange网络上的所有用户贡献内容的匿名转储。我选择了一些我感兴趣的话题,并从每个话题中抽取了100个问题。主题范围从生成式AI到咖啡或自行车,因此我们将看到各种各样的主题。
首先,我们需要计算所有Stack Exchange问题的Embeddings。这样做一次并将结果存储在本地(在文件或向量存储中)是值得的。我们可以使用OpenAI Python包生成Embeddings。
1 | from openai import OpenAI |
结果,我们得到了一个1536维的浮点数向量。现在我们可以对所有数据重复此操作,并开始分析这些值。
你可能会问的主要问题是句子之间的意思有多接近。为了找到答案,让我们讨论一下向量之间距离的概念。
矢量间距离
Embeddings实际上是向量。所以,如果我们想了解两个句子之间的距离有多近,我们可以计算向量之间的距离。距离越小,语义越近。
可以使用不同的度量来度量两个向量之间的距离:
- 欧氏距离(L2);
- 曼哈顿距离(L1);
- 点积,
- 余弦距离。
我们来讨论一下。作为一个简单的例子,我们将使用两个二维向量。
1 | vector1 = [1, 4] |
欧氏距离(L2)
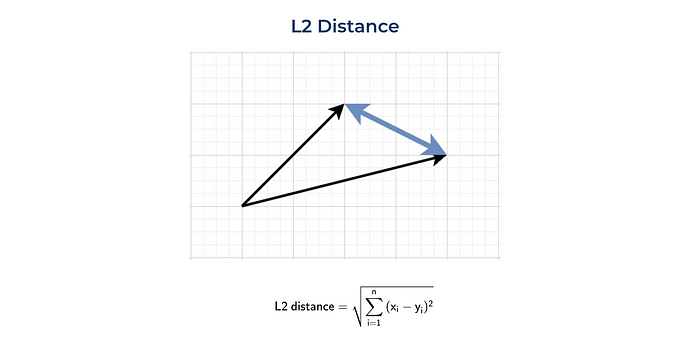
定义两点(或向量)之间距离的最标准方法是欧氏距离或L2范数。这个度量标准在日常生活中最常用,例如,当我们谈论两个城镇之间的距离时。
这是L2距离的直观表示和公式。
我们可以使用普通Python或利用numpy函数来计算这个度量。
1 | import numpy as np |
曼哈顿距离(L1)
另一种常用的距离是L1标准或曼哈顿距离。这段距离是以曼哈顿岛(纽约)命名的。这个岛有一个网格状的街道布局,在曼哈顿两个点之间的最短路线是L1距离,因为你需要遵循网格。
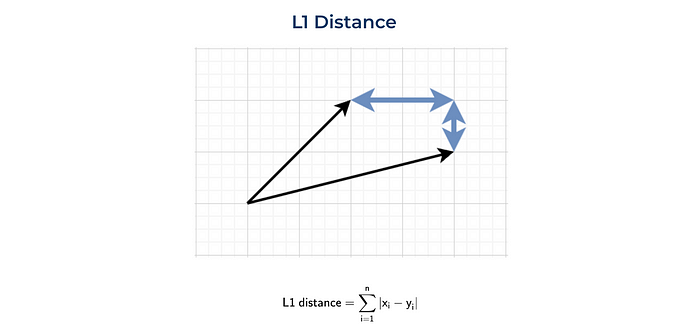
我们也可以从头开始实现它,或者使用numpy函数。
1 | sum(list(map(lambda x, y: abs(x - y), vector1, vector2))) |
点积
另一种计算向量间距离的方法是计算点积或标量积。这是一个公式,我们可以很容易地实现它。
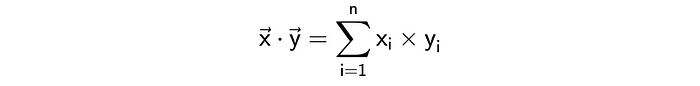
1 | sum(list(map(lambda x, y: x*y, vector1, vector2))) |
这个指标解释起来有点棘手。一方面,它告诉你向量是否指向一个方向。另一方面,结果高度依赖于向量的大小。例如,让我们计算两对向量之间的点积:
(1, 1)vs(1, 1)(1, 1)vs(10, 10).
在这两种情况下,向量都是共线的,但是第二种情况下的点积要大十倍:2比20。
余弦相似度
通常使用余弦相似度。余弦相似度是由向量的大小(或模)归一化的点积。
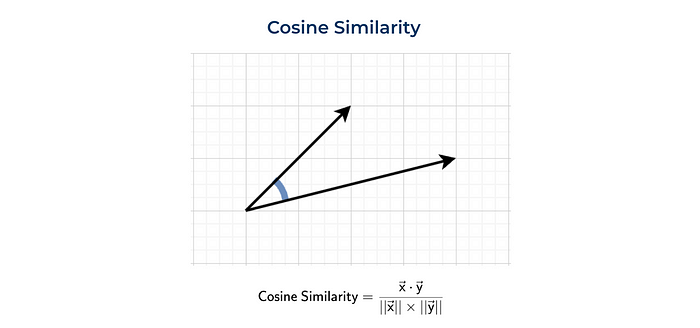
我们既可以自己计算(像以前一样),也可以使用来自sklearn的函数。
1 | dot_product = sum(list(map(lambda x, y: x*y, vector1, vector2))) |
函数cosine_similarity需要2D数组。这就是为什么我们需要重塑numpy数组。
我们来谈谈这个度规的物理意义。余弦相似度等于两个向量之间的余弦。向量越接近,度规值越高。
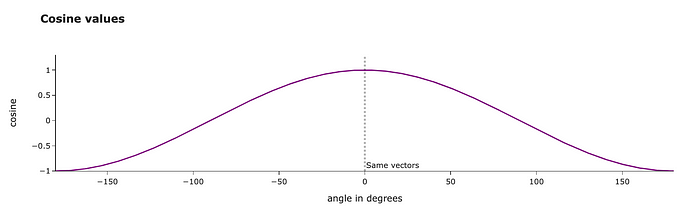
我们甚至可以用角度来计算向量之间的夹角。我们在30度左右得到结果,看起来很合理。
1 | import math |
使用什么度量标准?
我们已经讨论了计算两个向量之间距离的不同方法,您可能会开始考虑使用哪一种方法。
你可以用任何距离来比较你的Embeddings。例如,我计算了不同集群之间的平均距离。L2距离和余弦相似度显示了相似的图像:
- 集群内的对象之间的距离比集群内的对象之间的距离更近。解释我们的结果有点棘手,因为对于L2距离,距离越近意味着距离越小,而对于余弦相似度,距离越近的物体度量越高。别搞混了。
- 我们可以发现一些话题彼此非常接近,例如“politics”和“economics”或“ai”和“datascience”。
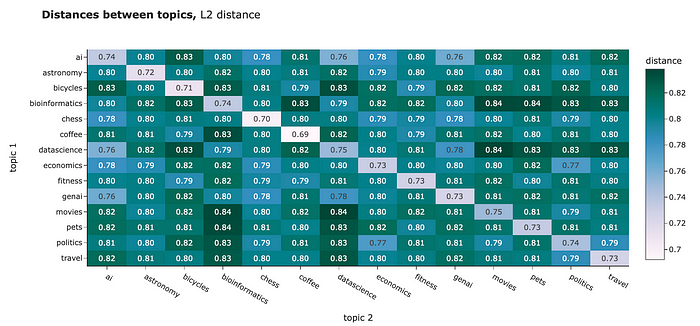
Image by author
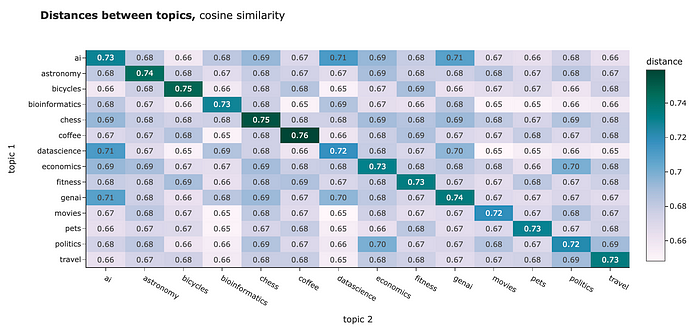
Image by author
然而,对于NLP任务,最佳实践通常是使用余弦相似度。这背后的一些原因:
- 余弦相似度在-1到1之间,而L1和L2是无界的,所以更容易解释。
- 从实用的角度来看,计算欧几里得距离的点积比计算平方根更有效。
- 余弦相似度受维度诅咒的影响较小(我们稍后会讨论)。
OpenAI的Embedding模型已经规范,所以点积和余弦相似度在这种情况下是相等的。
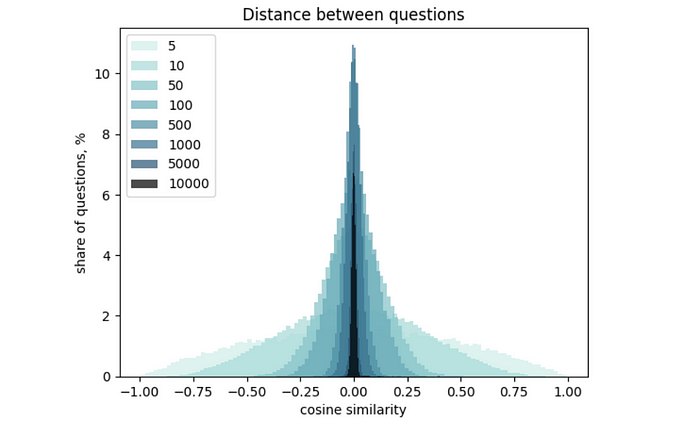
在上面的结果中,您可能会发现集群之间和集群内部距离的差异并不是那么大。根本原因是向量的高维数。这种效应被称为“维度诅咒”:维度越高,向量之间的距离分布越窄。您可以在本文中了解更多有关它的详细信息。
我想简单地向你们展示一下它是如何工作的,这样你们就有了一些直觉。我计算了OpenAIEmbedding值的分布,生成了300个不同维数的向量集。然后,我计算了所有向量之间的距离,并绘制了直方图。您可以很容易地看到,向量维数的增加使分布变窄。
Graph by author
我们已经学会了如何测量Embeddings之间的相似性。我们已经完成了理论部分,并转向更实际的部分(可视化和实际应用)。让我们从可视化开始,因为先看到你的数据总是更好。
可视化Embeddings
理解数据的最好方法是将其可视化。不幸的是,Embeddings有1536个维度,所以查看数据非常具有挑战性。然而,有一种方法:我们可以使用降维技术在二维空间中投影向量。
PCA
最基本的降维技术是PCA(主成分分析)。让我们试着使用它。
首先,我们需要将Embeddings转换为二维numpy数组,并将其传递给sklearn。
1 | import numpy as np |
然后,我们需要初始化一个n_components = 2的PCA模型(因为我们想要创建一个2D可视化),在整个数据上训练模型并预测新的值。
1 | from sklearn.decomposition import PCA |
结果,我们得到了一个矩阵,每个问题只有两个特征,所以我们可以很容易地在散点图上可视化它。
1 | fig = px.scatter( |
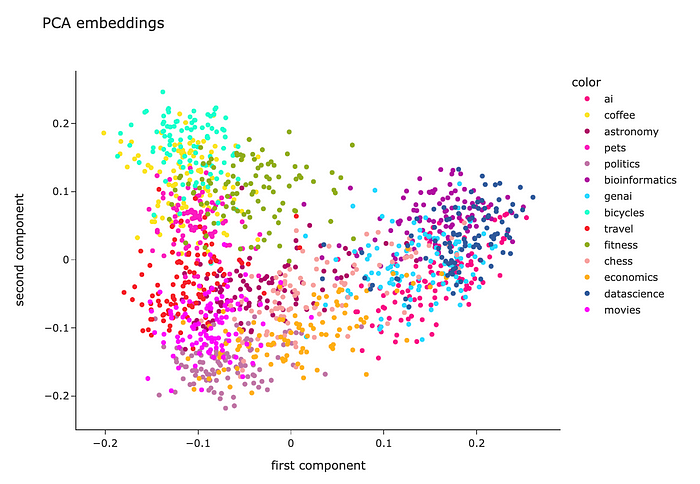
Image by author
我们可以看到,每个主题的问题都非常接近,这很好。然而,所有的集群都是混合的,所以还有改进的空间。
t-SNE
PCA是一种线性算法,而现实生活中大多数关系都是非线性的。因此,由于非线性,我们可能无法分离聚类。让我们尝试使用非线性算法t-SNE,看看它是否能够显示更好的结果。
代码几乎是一样的。我只是用了t-SNE模型而不是PCA。
1 | from sklearn.manifold import TSNE |
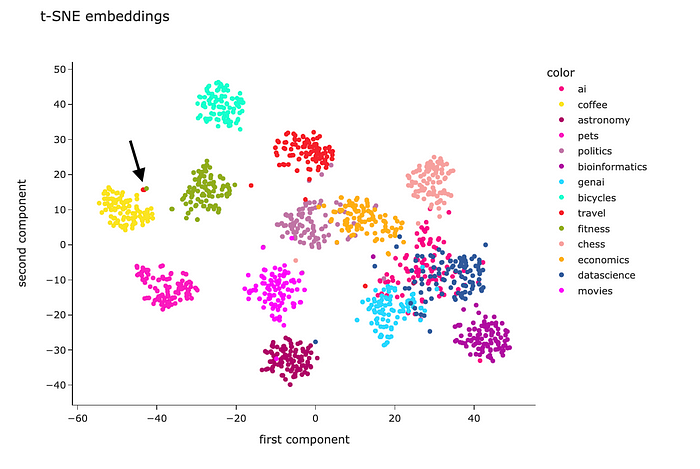
t-SNE的结果看起来要好得多。除了“genai”、“datascience”和“ai”外,大多数聚类是分开的。然而,这是很值得期待的——我怀疑我自己能把这些话题分开。
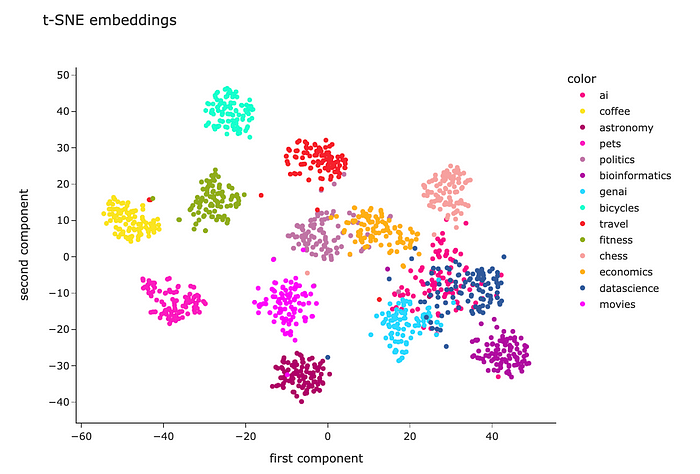
看看这个可视化图,我们看到Embeddings非常擅长编码语义。
此外,你可以做一个三维空间的投影,并将其可视化。我不确定它是否实用,但在3D中处理数据可能是富有洞察力和吸引力的。
1 | tsne_model_3d = TSNE(n_components=3, random_state=42) |
Barcodes
理解Embeddings的方法是将其中的几个可视化为条形码,并查看其相关性。我选择了三个Embeddings的例子:两个是彼此最近的,另一个是我们数据集中最远的例子。
1 | embedding1 = df.loc[1].embedding |

Graph by author
在这种情况下,由于高维数,很难看出向量是否彼此接近。然而,我仍然喜欢这种视觉化。在某些情况下,这可能会有所帮助,所以我与你分享这个想法。
我们已经学会了如何可视化Embeddings,并且毫不怀疑它们掌握文本含义的能力。现在,是时候进入最有趣和最迷人的部分,并讨论如何在实践中利用Embeddings。
实际应用
当然,Embeddings的主要目标并不是将文本编码为数字向量,或者仅仅是为了将它们可视化。我们可以从捕捉文本含义的能力中获益良多。让我们看一些更实际的例子。
聚类
让我们从集群开始。聚类是一种无监督学习技术,它允许您在没有任何初始标签的情况下将数据分成组。集群可以帮助您理解数据中的内部结构模式。
我们将使用最基本的聚类算法之一——K-means。对于K-means算法,我们需要指定簇的数量。我们可以使用剪影分数来定义最佳簇数。
我们试试k(集群数量)在2到50之间。对于每个k,我们将训练一个模型并计算轮廓分数。轮廓值越高,聚类效果越好。
1 | from sklearn.cluster import KMeans |
在我们的例子中,剪影分数在k = 11 时达到最大值。那么,让我们用这个数量的聚类来建立最终的模型。
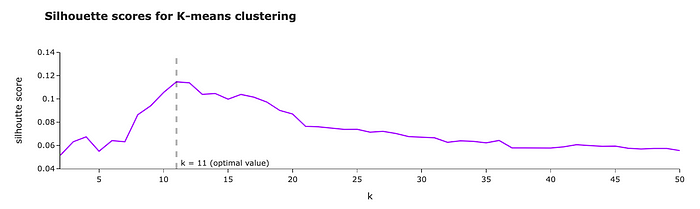
Graph by author
让我们像之前一样使用t-SNE进行降维来可视化集群。
1 | tsne_model = TSNE(n_components=2, random_state=42) |
从视觉上看,我们可以看到该算法能够很好地定义聚类——它们被很好地分离。
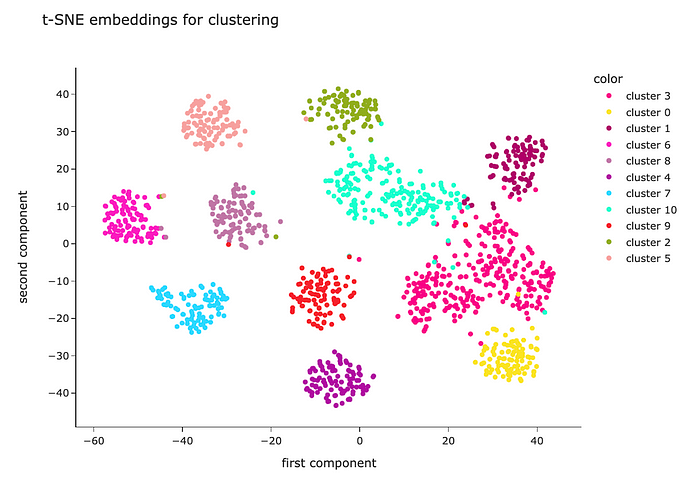
我们有事实主题标签,所以我们甚至可以评估集群有多好。让我们看看每个集群的主题组合。
1 | df['cluster'] = list(map(lambda x: 'cluster %s' % x, kmeans_labels)) |
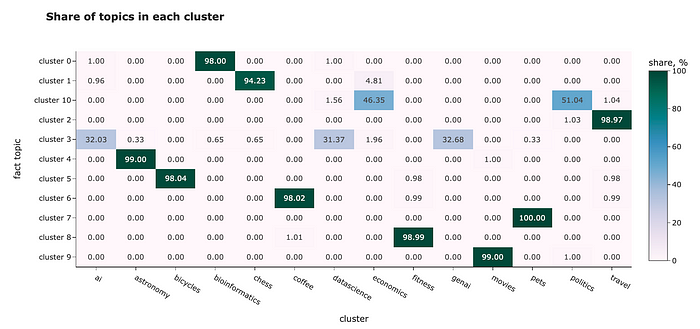
在大多数情况下,集群运作完美。例如,集群5几乎只包含关于自行车的问题,而集群6则是关于咖啡的问题。然而,它无法区分相近的话题:
- “ai”、“genai”和“datascience”都在一个集群中,
- “economics”和“politics”相同的集群。
在本例中,我们只使用Embeddings作为特征,但是如果您有任何其他信息(例如,提出问题的用户的年龄、性别或国家),您也可以将其包含在模型中。
Classification
我们可以将Embeddings用于分类或回归任务。例如,你可以用它来预测顾客评论的情绪(分类)或NPS分数(回归)。
因为分类和回归是监督学习,你需要有标签。幸运的是,我们知道问题的主题,并且可以用一个模型来预测它们。
我将使用随机森林分类器。如果你需要快速复习一下随机森林,你可以在这里找到它(https://medium.com/towards-data-science/interpreting-random-forests-638bca8b49ea)。为了正确评估分类模型的性能,我们将数据集分为训练集和测试集(80% vs 20%)。然后,我们可以在训练集上训练我们的模型,并在测试集(模型以前没有见过的问题)上测量质量。
1 | from sklearn.ensemble import RandomForestClassifier |
为了估计模型的性能,让我们计算一个混淆矩阵。在理想情况下,所有非对角元素都应该是0。
1 | from sklearn.metrics import confusion_matrix |
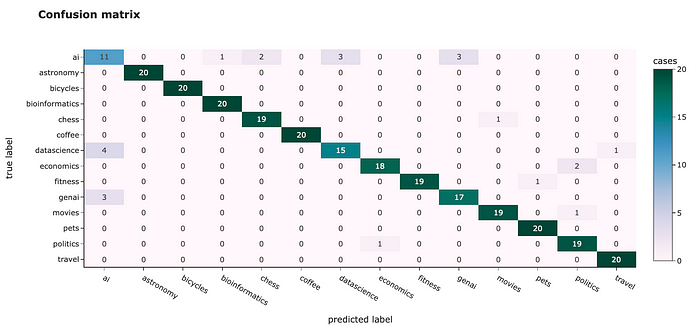
我们可以看到与聚类相似的结果:一些主题很容易分类,准确率为100%,例如“自行车”或“旅行”,而另一些主题则很难区分(特别是“ai”)。
然而,我们达到了91.8%的总体准确率,这是相当不错的。
发现异常
我们也可以使用Embedding来发现数据中的异常。例如,在t-SNE图中,我们看到一些问题离它们的聚类相当远,例如,对于“旅行”主题。让我们来看看这个主题,并试图找到异常。我们将使用隔离森林算法。
1 | from sklearn.ensemble import IsolationForest |
所以,我们在这里。我们找到了关于旅游话题的最不寻常的评论(来源)。
1 | Is it safe to drink the water from the fountains found all over |
因为是关于水的,所以这个评论的Embedding与咖啡的话题很接近,人们也在讨论水来倒咖啡。因此,Embedding表示是相当合理的。
我们可以在t-SNE可视化中找到它,看到它实际上靠近咖啡星团。

Graph by author
RAG -检索增强生成
随着最近大语言模型的日益普及,Embeddings已被广泛用于RAG用例中。
当我们有很多文档(例如,来自Stack Exchange的所有问题)时,我们需要检索增强生成,并且我们不能将它们全部传递给LLM,因为:
- 大语言模型对上下文大小有限制(目前,GPT-4 Turbo的上下文大小是128K)
- 我们为tokens付费,所以一直传递所有信息的成本更高。
- 大语言模型在更大的背景下表现更差。您可以查看大海捞针-压力测试大语言模型了解更多细节。
为了能够使用广泛的知识库,我们可以利用RAG方法:
- 计算所有文档的Embeddings并将其存储在向量存储中。
- 当我们得到一个用户请求,我们可以计算它的Embedding和检索相关文档从存储为这个请求。
- 仅将相关文件传递给LLM,以获得最终答案。
要了解更多关于RAG的信息,请毫不犹豫地阅读我的文章,了解更多细节在这里。
总结
在本文中,我们详细讨论了文本Embeddings。希望现在你对这个主题有了一个完整而深刻的理解。下面是我们旅程的快速回顾:
- 首先,我们经历了文本处理方法的演变。
- 然后,我们讨论了如何理解文本之间是否具有相似的含义。
- 在那之后,我们看到了文本Embedding可视化的不同方法。
- 最后,我们尝试在不同的实际任务中使用Embeddings作为特征,如聚类、分类、异常检测和RAG。
原文链接:https://towardsdatascience.com/text-embeddings-comprehensive-guide-afd97fce8fb5

