意图识别是面向目标对话系统的一项重要任务。意图识别(有时也称为意图检测)是使用标签对每个用户话语进行分类的任务,该标签来自预定义的标签集。
分类器在标记数据上进行训练,并学习区分哪个话语属于哪个类别。如果一个看起来不像任何训练话语的话语来到分类器,有时结果会很尴尬。这就是为什么我们也会对“域外”话语进行分类,这些话语根本不属于域。
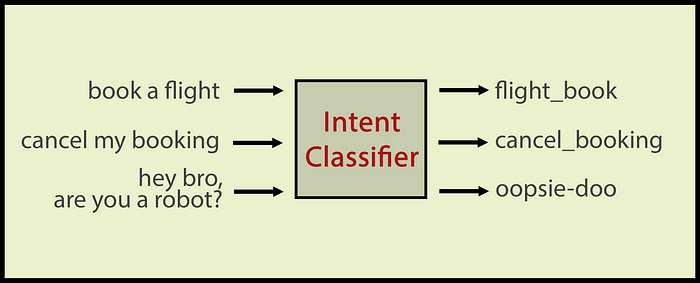
意图分类器对话语进行分类。在这里,示例领域是机票预订和“嘿,兄弟,你是机器人吗?”是一个域外的话语。作者图片
问题是用户和我们开发人员生活在不同的语言中。开发人员希望留在语义丛林中的安全农场(所谓的领域),但用户并不十分了解分类器或聊天机器人NLU是如何工作的(他们也不必知道)。你不能指望用户保持在正确的语义领域,相反,你应该赋予你的聊天机器人处理良好话语的技能。
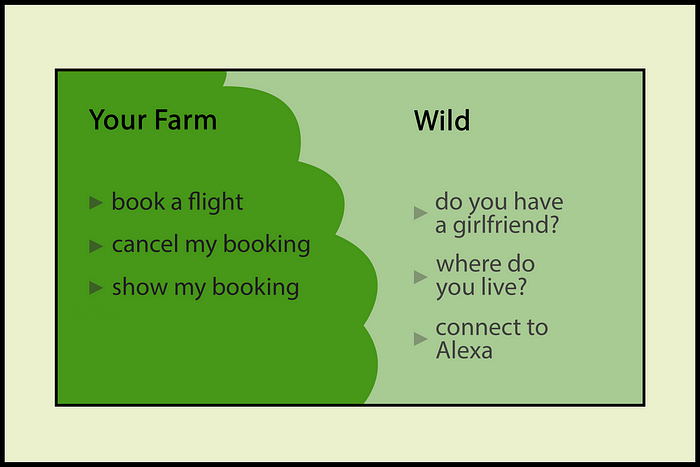
你的安全语义农场在口语的野性。你永远不知道从野外来的是什么!作者图片
在这篇文章中,我们将讨论如何通过检测哪些话语属于域,哪些话语不在域内来保持域的完整性,Chris是我们的司机语音助手。首先,我将介绍Chris域和话语,然后我们将讨论什么zero-shot学习文本分类与Siamese网络。
Chris Domain and Data
Chris是司机的语音助手。我们的Chris是一个驾驶助手,由德国自动实验室制造。Chris可以发送/阅读短信,WhatsApp消息,打电话给电话联系人,播放音乐,导航,响应天气查询和聊天。


我们的 Chris,在左边。Chris和他的能力,在右边。图片来自德国汽车实验室网站。
Chris是一个以任务为导向的会话代理,因此用户的话语通常简洁而切中要害。这些是典型的用户话语:
1 | play music |
意图名称由子域名和动作名称组成。以下是与上述话语相对应的一些意图名称:
1 | music.play |
域外话语呢?下面是一些例子:
1 | hey siri |
这是完全正常的用户要求一些功能,你的聊天机器人根本没有。例如,打开车门根本不在克里斯的技能范围内。尽管UX团队在每个包装中都包含了关于Chris技能的指导方针,但用户可能会跳过它..这就是为什么您的聊天机器人NLU应该始终准备好处理广泛的域外话语,用户要求的是他们可以想象到的聊天机器人可以实现的能力,而不是用户手册中写的那些。
简短的话语乍一看可能很“容易”,但也有一些挑战。语音识别错误可能会给人带来困难,特别是在短的话语中,因为语义上至关重要的单词可能会从话语中丢失(例如“play music”中的“play”)。此外,语音引擎必须在正确的时间开始倾听,否则它可能会错过一个单词,短的话语,如“yes”,“no”,这对解决上下文至关重要。从WER的角度来看,仅仅缺少3个字母并不是一个严重的ASR错误,但如果您的代理多次要求用户批准,则可能会给用户带来挫败感。所有的语音机器人都有声学和语义方面的挑战,永远不要低估使用语音的挑战。
什么是zero-shot文本分类?
零短文本分类是在一组类标签上训练分类器,并用分类器在训练集中没有看到的类标签来测试分类器的任务。NLP最近的工作集中在更广泛的背景下的zero-shot学习,zero-shot学习NLP现在意味着训练一个模型来完成它没有明确训练的任务。GPT-3是一个zero-shot学习者,吸引了相当多的关注。
在zero-shot分类中,我们用一些视觉线索或类名向分类器描述一个看不见的类。对于zero-shot文本分类,通常使用意图名称来描述意图的语义。当我第一次开始做Chris NLU时,数据是用于“常规”意图分类的。然后我开始尝试,并找到了我们的类命名方案**域。动作(音乐)。玩,导航。开始等等)确实非常适合zero-shot学习。
将标签和话语嵌入到同一空间
zero-shot文本分类的常用方法是将意图名称和话语嵌入到同一空间中。这种zero-shot算法可以像我们人类一样,通过语义组来学习意图名称和话语之间的语义关系。这根本不是一个新想法,研究人员使用单词向量来表示固定维度的文本和意图名称(例如在Veeranna at all.2016)。通过Transformers的发明,密集表示经历了一场革命,现在我们有了更多高质量的句子和单词Embeddings。
在我们的研究中,我们首先使用平均池词向量来表示话语,然后使用BERT对我们的话语进行编码来生成话语向量。首先让我们看看当我们使用词向量时意图名称是如何与话语结合在一起的。我们使用了100维手套向量。我们通过平均一个话语的词向量来生成句子Embedding。为了得到标签的Embedding(例如music.play),我们平均了域(music)和动作(play)的Embeddings。在为所有话语生成Embedding之后,我们使用t-SNE将数据集转换为二维(出于可视化目的)。下面的散点图显示了所有数据集的话语和意图名称,具有相同意图的话语用相同的颜色表示:
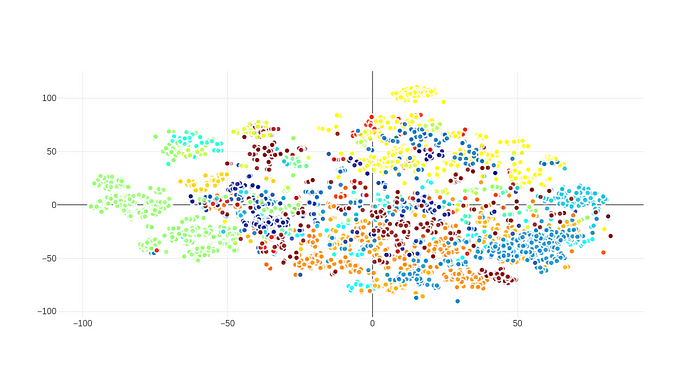
Chris的话语,每种颜色都代表一种意图。
这就是话语和意图名称的排列方式:
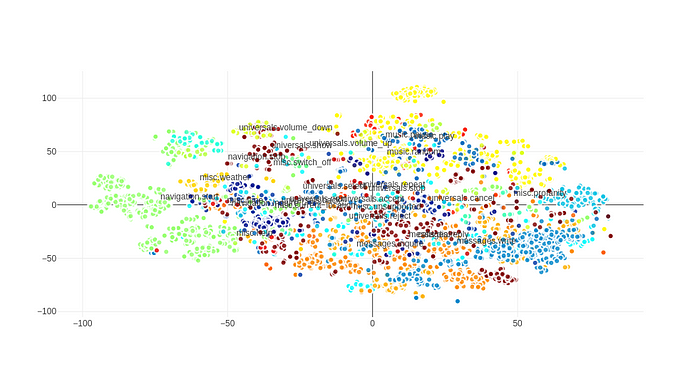
Embedding意图名称和话语到同一空间
如果我们放大一点,我们会看到意图名称和相应的话语确实非常一致:
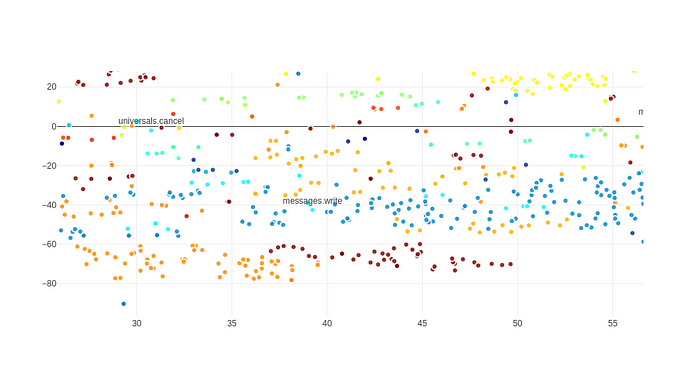
放大到上面的视觉效果
数据集的话语创建了一个相当漂亮的散点图,没有太多的异常值,相同的意图的话语与意图名称组合在一起。
如果我们想用BERT嵌入话语和意图名称呢?这对话语很有效,但意图名称不是真实的句子和简短的表达。BERT是针对完整句子进行训练的,对于像我们的意图名称这样的简短表达可能不太有效。在这种情况下,我们可以通过BERT为话语创建768维Embeddings,并通过词向量为意图名称创建100维Embeddings。为了将它们嵌入到相同的空间中,我们需要计算一个投影矩阵φ,将768个模糊的话语向量投影到100维意图向量上。由于我们有标注的数据,我们可以通过回归来学习投影矩阵。(尽管包含正则化以防止过拟合很重要)。然后我们有一个类似于上面的视觉对齐。
用于zero-shot文本分类的Siamese网络
上面的探索性数据分析告诉我们,意图名称和话语之间的语义相似性是非常明显和可学习的。然后我们可以要求Siamese神经网络学习意图名称和话语之间的相似性。
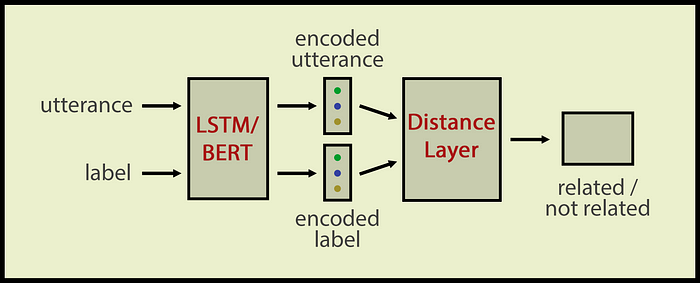
传统的意图分类器输入一个话语并生成一个类标签。通常我们用LSTM或BERT对话语进行编码,然后将编码后的话语输入到Dense层并得到一个类标签:
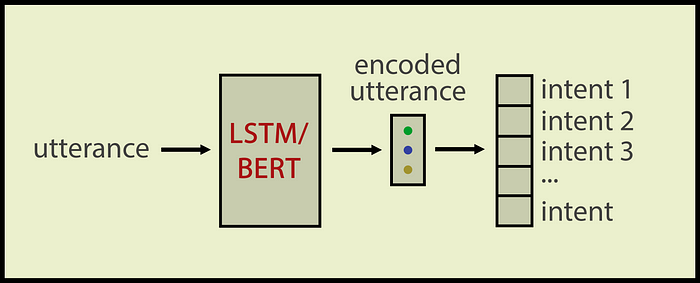
传统的意图分类器。by作者
我们的zero-shot意图分类器会学习标签和话语在语义上是否相似。我们使用了Siamese网络架构,这对于计算语义相似度非常有用。我们的Siamese网络输入一个意图名称和一个话语;输入相关或不相关的输出。
架构与我在我之前的SiameseNN文章中描述的相同。该体系结构包括
- LSTM/BERT层对话语和标签进行编码
- 然后是距离层,计算话语和标签之间的语义距离
- 最后是一个Dense层,将距离向量压缩为二进制值
该体系结构仍然是一个文本分类器,但此时输入数为2,输出向量维数仅为1。输出为二进制,0表示标签与话语不相关;1表示该话语属于该标签的类。
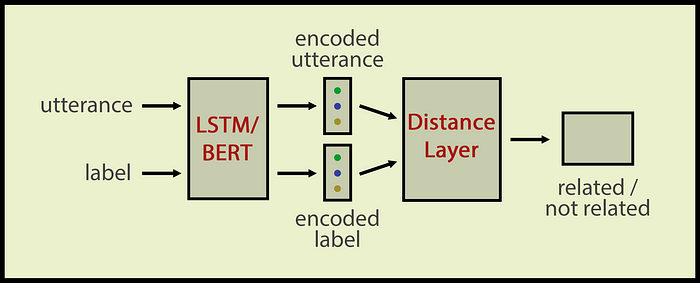
Siamesezero-shot意图分类器。作者图片
我们可以向Siamese分类器询问任何我们想要的标签(即使分类器以前从未见过这个标签),只要我们能为标签提供一个良好的Embedding。这对于域外的话语来说是很好的,因为即使你没有任何标记好的类数据或只有几个例子,Siamese zero-shot分类器仍然可以决定一个话语是否与Chris域相关或与域不相关。
Siamese网络用于语义相似已经有很长一段时间了,但是玩一些技巧可以让我们毫不费力地获得zero-shot意图预测模型。有时候,这个想法一直就在你面前,但你必须从不同的角度去看待它。
在本文中,我们继承了一种全新的方法来解决“传统”的意图分类问题。首先,我们对Chris的话语进行了语义分组。然后,我们刷新了关于Siamese网络的知识。最后,我们看到了如何使用Siamese网络进行zero-shot分类。
我希望所有的读者都喜欢我们的Chris的能力和数据,并希望在更多的Chris文章中见到你。在那之前,请保持关注和健康❤️
参考文献
- Language Models are Few-Shot Learners, https://arxiv.org/abs/2005.14165
- Are Pretrained Transformers Robust in Intent Classification?
A Missing Ingredient in Evaluation of Out-of-Scope Intent Detection https://arxiv.org/pdf/2106.04564.pdf - Detecting Out-Of-Domain Utterances Addressed to a Virtual Personal Assistant https://www.microsoft.com/en-us/research/wp-content/uploads/2014/09/IS14-Orphan2.pdf
- Using Semantic Similarity for Multi-Label Zero-Shot
Classification of Text Documents , https://www.esann.org/sites/default/files/proceedings/legacy/es2016-174.pdf
原文:https://towardsdatascience.com/zero-shot-intent-classification-with-siamese-networks-35900471c7fd

