转眼到了2024年尾,和小伙伴一起创立TorchV也接近一年。虽然这一年做了很多事情,但从技术层面上来说,RAG肯定是不得不提的,所以今天分享一下作为大模型应用创业者所感知的这一年,RAG技术和市场环境的变化。
首先申明,本文更多来自于本人主观感受,且内容更多是回顾性的结论,不建议作为其他文章的引用材料。
主要内容包括:
- RAG技术变化
- 主要架构变化
- 技术细节变化
- 市场需求变化
- 上半年:AI无所不能,大而全;
- 下半年:回归理性,小而难;
- 明年预测:应用才是王道;
- 从业者变化。
其中技术部分放在上篇,市场需求变化放在下篇。
一、RAG技术变化
RAG(检索增强生成)其实是由两部分组成的,分别是检索和大模型生成。当然,既然有检索就必然会先有索引,包括chunking、embedding等动作都是为了建立更好的索引。因为我们之前从零开始创建并运营了一个千万级用户的智能问答类产品,所以在2021年左右其实就已经采用Java技术栈在使用RAG里面“RA”的大部分技术了。在2023年年中,RAG这个词突然火了起来,于是我们就立马就扑进去了,而且相信RAG在企业应用领域比纯粹使用大模型会更具实用性,至少在三年之内是这样的(随着最近传闻Scaling Law遇到瓶颈,好像这个时间还有可能被推后)。短短几个月,RAG开始的火爆程度甚至有超过LLM的趋势,在2024年1月我甚至还参加了“共识粉碎机”的EP15讨论会,主要话题就是“2024年是否会成为RAG元年?”。
1.主要架构变化
虽然RAG的火热,各种架构思想就被大师们总结出来,最出名的莫过于下面这张图了:
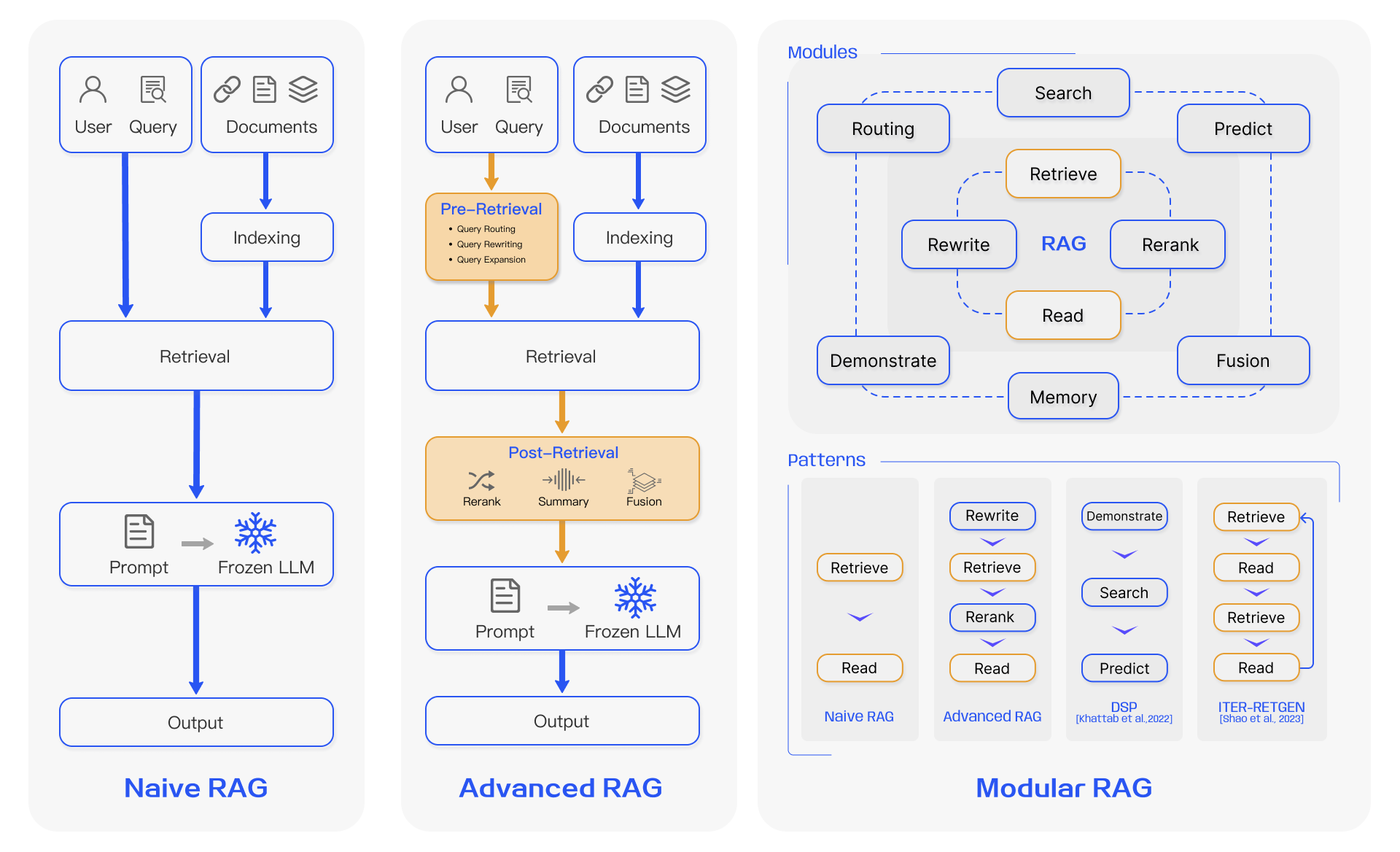
图1:RAG三种架构模式,来源于论文Retrieval-Augmented Generation for Large Language Models: A Survey。
站在现在(2024年11月)再看,其实Advanced RAG应该还是最主流的架构。因为它的效果明显比Naive RAG要好,但比Modular RAG更容易实现。在实际应用中,我们还需要为客户考虑经济成本和维护成本,很多时候基于客户需求,在Advanced RAG上做一些对症下药,远比全家桶更具适应性。
2.技术细节变化
相较于架构变化,技术细节的变化更加“风起云涌”,这一点从各自媒体的文章主题变化和从业者之间的交流内容中就能明显感知到。在RAG这个大框架之下,我们看到了每隔一段时间就会有一些技术细节被热炒,比如:
- 知识提取
- 索引组织
- 检索方法
01 知识提取
在2024年之前,我们看到的RAG面对的原始知识更多是非常标准的论文,一般是文字版PDF或者HTML,所以那时候内容提取还不是一个大问题。但是在2024年,随着各行各业都开始使用RAG之后,五花八门的文件类型解析变成了从业者们头痛的事情,于是,我们发现有好一波人开始专注于知识提取。
于是我们看到在2024年,出现了很多专门做知识提取的公司,比如已经在科创板上市合合信息(其实已经是老牌企业),在文件解析方面就非常出色,还有新创的SoMark等,当然大厂在这一块肯定也都涉足,特别是OCR解析,比如百度开源的PaddleOCR,其实还挺良心的。
我们也是如此,看到现成的python组件在面对多样的知识文件类型时渐感无力,于是就开始在知识提取方面花时间。从多类型文件的解析,包括一些老文件格式(.doc、.xls、.ppt等)的解析,再到比较难的PDF表格解析,需要去处理非常复杂的合并/拆分单元格,并且也有了具备原创知识产权的提取工具组件。
但是我一直在想,是否可以把整个工作流再前置,如果我们提供知识生产工具,用户可以在我们的知识管理和生产工具上进行知识生产和协作,那么知识提取是不是会更流畅?这个问题可以单独写一篇文章,就放在这个篇文章的上下篇结束之后吧。
02 索引组织
在RAG里面,索引组织可能是相对比较有技巧性的部分了。
了解RAG的人都听过chunking,不严谨地说,就是把文件切成若干片段,为的是可以在LLM的窗口大小之内进行作业。常见的chunking方式有按固定token数量的,有按Page的,也有通过NLTK等来进行切分的。但我始终觉得使用哪种chunking方法并不是重点,如果您使用的LLM的上下文窗口较大,对于一些4、5页的文件,还切它干嘛呢,直接扔进去就完事了。但在chunking过程中,其实有两个隐含的技巧是可以快速提升准确率的:指代消解和附加元数据。
指代消解
我们在实操中常见的是两种,一种是切割的时候,上一页有详细信息,而下一页中只有“这种方法”来指代。这时候最简单的方法就是做chunk叠加;还有一种就是类似合同,甲方乙方的具体名字只在最开头的地方出现,剩下全文都用“甲方”、“乙方”指代,这种情况因为被指代的名称是比较好获取的,可以直接加在chunk中,如下所示(伪代码),chunk_meta里面可以设置甲方乙方的全称:
1 | <chunk> |
附加元数据
其实元数据的索引存储结构和上面的指代消解示例中差不多,不同的是,我们需要关心的是:
- 元数据从哪里来?
- 在检索的过程中什么情况下激活元数据过滤?
元数据的来源只可能是人工标注或者应用侧(包括文件处理时)生成的,这里我们肯定先不去考虑人工标注了。从应用侧的设计来看,其实是可以拿到很多元数据的。比如我们上传文件、撰写知识的时候,自然可以拿到时间、文件名称(正常命名都会含有实体),也可以在交互设计中要求作者进行分类选择,简介编写等,无一不是增加元数据的手段。
但我们在索引中增加了元数据内容之后,也不是强行要激活元数据过滤的。我们在实操中是会设置自定义的系统槽位(system_slot),如果用户提问的文本中,包含也比较多的意图和实体信息,且与系统槽位存在匹配,才会激活。会先使用BM25进行元数据过滤,再进行dense检索。更具语义信息的dense索引有时候因为维度限制会丢失一些信息,或者说dense检索对于元数据过滤并不那么精准。这种设计一方面可以减少检索的时间,另一方面就是可以提高带有时间和实体(如城市、公司、部门等)意图的提问的准确率。说起来这好像是一种“退步”,因为当LLM(或GPT)所向披靡的时候,我们也是一度有点看不上之前的技术的,但是在企业应用实践中,客户问题的解决率才是一切的根本。所以,在TorchV AI中,我们让NLU和Slot(槽位填充)回归了。
是否使用Graph
对了,还有一个大家争论比较多的索引组织方式就是Graph或者叫图数据,将node(实体)和relation(关系)通过图论组织起来。我们团队从2015年开始一直有在使用neo4j开发一些有趣的应用,在寻找人类直观上不太容易识别的点与点关联的方面确实非常出色。但是这个技术非常大的问题就是索引建立,从关系数据库把结构化数据迁移到Graph数据库中还算容易,但是面对成千山万的非结构化数据的时候,说实话目前也就是只能让GPT4以上的LLM来帮忙了。和重度使用过图知识库的朋友聊的过程中,他们的一致感受是:花费太高昂,但是场景太薄弱,依然还存在手工校对的工作。换句话说,如果花了10万的费用,但在实际使用中却没这么多使用场景,得不偿失。
当然,如果您手头的工作非Graph不能解决,那就大胆去All-in吧。我们目前的系统并没有使用图数据库。
03 检索方法
有句话(我说的)不一定说的对,在某种意义上,知识提取决定了专有知识的完整性,索引组织决定了回答准确率,而检索方法则在减少幻觉上有重要意义。
如果我们可以准确检索召回,把非常明确的内容加上指令prompt,给到LLM处理,那么LLM给出的结果几乎不太会一本正经胡说八道。只有检索召回的内容和用户原问题不相关,或者召回内容存在多个不置可否的知识内容时,LLM才会按心情(概率和 temperature)选择错误知识或者使用预训练时学习的知识进行回答。所以,检索做得好,可以将整个RAG幻觉尽可能多的变为白盒。
Hybird
但是说到检索,我相信现在大部分的RAG系统都已经用上了Hybird检索了吧,一般来说也就是BM25+语义相似检索的混合检索。
BM25有自己的固有用武之地,就像前面说的元数据过滤,还有就是一些在类似产品型号和专业术语的检索上,其精确度和稳定性是远高于语义相似检索的。
语义相似检索有很多方法,因为我们主要用的还是Elasticsearch(也有Milvus),所以其实真正的语义相似检索就是ANN,说的更具体就是以HNSW为主的相似度算法。这个HNSW(最小可导航世界)的逻辑解释起来有点麻烦,但是我可以打一个比方:
比如你需要从一个城市的南部坐公交去北部,我们要选择最短的坐车路线(含换乘),那么有两种方式选择:
- knn:将所有可能的公交路线(含换乘)做一个整理,假设有28900条路线,然后按花费时间进行排序,选择Top1或者Top n。抛开语义理解错误的问题,这种方法是非常精确的,但是耗时巨大,也可以认为是一种暴力检索;
- ann:还有一种就是相似最近邻,我们这里说的更多的是hnsw。为了让非技术专业的朋友可以听懂,不严谨地说,看着地图,从28900条路线中,选择出发地和目的地两点连线附近的50或100条公交路线。这种方法的效率极高,可能耗时只需要knn的万分之一,但它的问题在于无法确定这50或100条里面哪几条才是最好的。于是,如果你采用ann却不用rerank的话,就会比较拉垮了。
RRF Fusion
RAG-Fusion主要是使用多个不同类型的检索方式进行检索,并按RRF(倒数排序融合)公式进行综合排名的一种检索方式。
多种检索方式包括:
- Sparse(稀疏)检索,比如BM25;
- Dense(稠密)检索,比如语义相似度检索;
- 还有就是使用不同配比的混合检索(在TorchV AI中,我们采用alpha值来做BM25和ANN的结果权重配比)。
然后使用RRF公式
RRF(d) = Σ(r ∈ R) 1 / (k + r(d))
具体公式就不解释了,有兴趣的朋友自己查资料吧。
来进行再排序,得出一个综合结果。其好处是使用不同的检索器,可以在各类不同问题场景下得到一个“思考”更周密的答案。我们在的系统里面有一个turbo开关,打开就会进行增强检索,其中也包括了该方法,且在召回率方面是有一定效果的。
Rerank
其实我应该不用再讲reank了,如果您看过上面hnsw算法的话,就能知道rerank的作用了。TorchV AI在使用rerank的时候也加入了自己的一些优化算法,比如归一化处理和密度函数(舍弃相关性较低的返回结果)。在使用rerank前后,准确率相差确实很大,但你要平心而论,元数据过滤对准确率的提升可能会更明显。因为rerank相对比较被动(根据前序召回的结果,有时候是矮子里拔将军),而元数据过滤则是直接在检索召回环节产生影响,相对更加主动(自己对召回哪些结果起到重要作用)。嗯,这是我自己的理解,不一定对。
3.技术部分小结
OK,RAG技术变化我想先做个小结。关于RAG的大流程已经有太多文章了,我自己也写了不少,所以本文我更希望是从几个点来讲衣鞋 技术实践上发现的变化。其实从RAG本身的各环节技术来说,没有出现新的现象级组件,2024这一年,感知和看到更多的,其实是大家根据实际需求不断探索最佳实践,并内化到系统能力中的一个过程。
二、市场需求变化
1.RAG vs Fine-tune
2024这一年,RAG技术对应的市场需求变化也是挺大的。在讲变化之前,我觉得有必要分享一下为什么RAG是目前市场上不可或缺的一种大模型应用的技术实现方式,它的优点是什么?以及它和主要竞争技术之间的现状是怎么样的?
RAG最开始被大家热推,更多是因为以下三个原因:
- 可以避开大模型的上下文窗口长度的限制;
- 可以更好地管理和利用客户专有的本地资料文件;
- 可以更好地控制幻觉。
这三点到现在来看依然还是成立的,但上下文窗口这个优势已经慢慢淡化了,因为各大模型的上下文窗口都在暴涨,如Baichuan2的192K,doubao、GLM-4的128K,过10万tokens的上下文窗口长度已经屡见不鲜,更别说一些特长的模型版本,以及月之暗面这样用长文本占据用户心智的模型。虽然这些模型是否内置了RAG技术不好说,但是RAG解决上下文窗口长度限制的特点已经不太能站得住脚。
但是第二点管理和利用专属知识文件,以及第三点控制幻觉,现在反而是我认为RAG最大的杀手锏。
01 专属知识文件管理
因为RAG这种外挂文件的形式,我们便可以构建一个知识文件管理的系统来维护系统内的知识,包括生效和失效时间,知识的协作,以及便捷地为知识更新内容等。RAG在知识维护上,既不需要像传统NLP那样由人工先理解再抽取问答对,也不需要像微调(fine-tune)那样需要非常专业的技术能力,以及微调之后的繁琐对齐(alignment)优化。所以如果客户的知识内容更新比较频繁(假设每天需要追加、替换大量实时资讯内容),特别是金融证券、企业情报等场景,RAG知识更新便捷的特性真的非常合适。
02 RAG的幻觉控制
RAG的幻觉控制是一个有争议的话题,我之前写过类似观点,也有同学斩钉截铁地认为RAG和幻觉控制八竿子打不着,但我现在依然坚持RAG可以有效控制幻觉这个观点。
首先我们可以来看看LLM幻觉产生的主要原因:
- 对于用户的提问输入,LLM内部完全没有相应的知识来做应对。比如你问大模型,上周三我在思考一件事,但是现在想不起来,你帮我想想是什么。例子虽然夸张,但显而易见,LLM也不知道,但是它会一本正经给你一些建议,当然肯定不是你想要的;
- 当我们给LLM原始问题,以及多个模凌两可或互相影响的参考材料,那么LLM给出的最终答案也会出错。
好,那么针对以上问题,是否我们解决好对原始问题的“理解-检索-召回”,送到LLM的context足够清晰(指的是没有歧义内容、检索相关度高),结果就会非常准确?根据我们的实践结果,答案是明确的:
今年9月份我们对一些项目进行了槽位填充(消除模糊问答)和元数据辅助之后,问答准确率可达到98%以上。比直接把大文本扔进同一个LLM测试的问答准确率几乎高出14个百分点。
有同学会说,LLM幻觉的深层原因是temperature或者说概率引起的。就我纯个人观点来看,现当下的LLM参数足够大、知识量足够多,temperature引起的偏差对于最终结果的正确性影响已经微乎其微了。
03 市场表现
你应该看出来了,在RAG和微调之间,我明显站队了,而且从一年前就开始站队了,我们创业的技术方向也是如此。从今天来看,我觉得RAG在2024年的表现确实要强于微调。
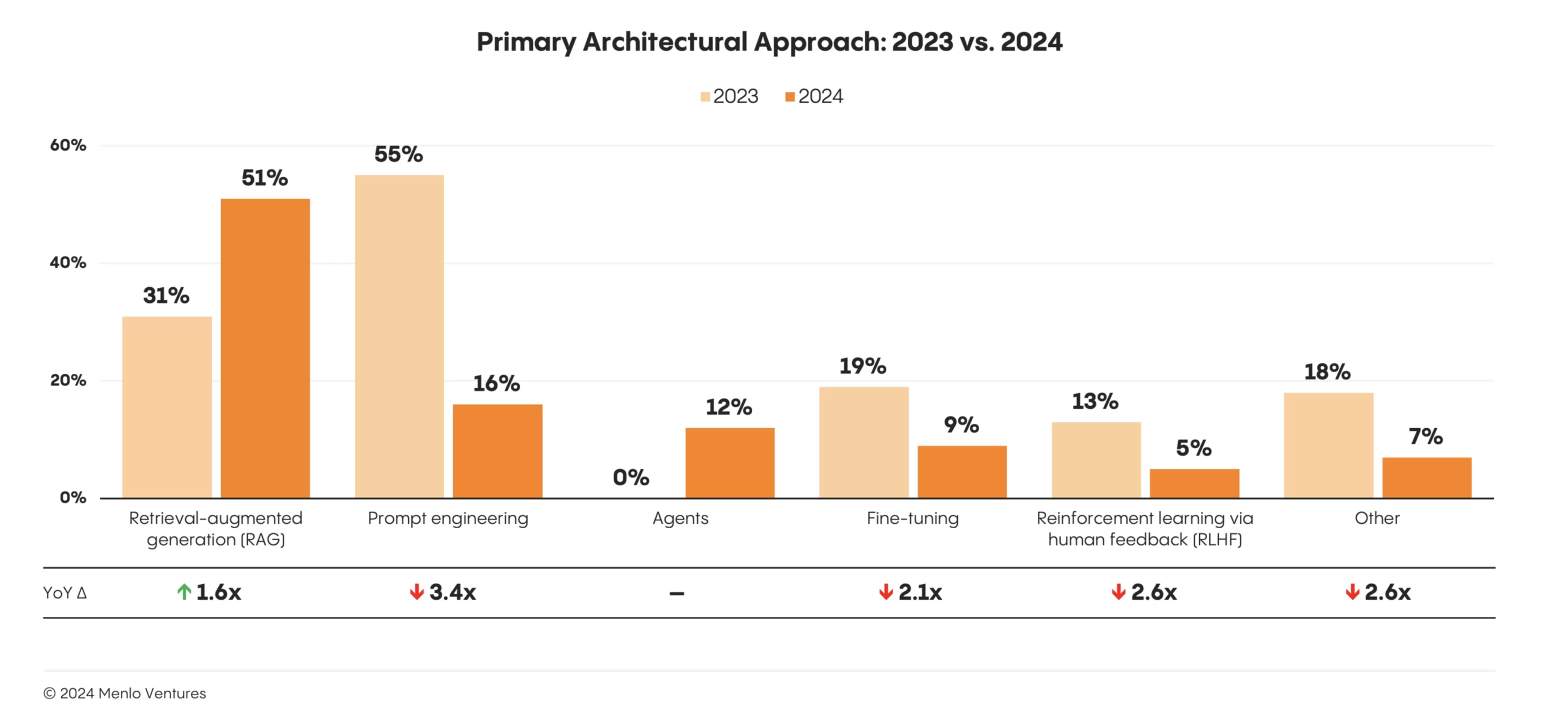
图:Menlo Ventures在2024年11月20日发布的市场调研报告。RAG以51%的市场份额在企业市场份额中占据绝对优势,Fine-tune和Prompting工程均下降两倍多。Agent今年属于纯增长,目前情况还不错,但在企业应用领域,多Agents的编排依然存在理解能力不足和生成幻觉等问题有待提高。来源:https://menlovc.com/2024-the-state-of-generative-ai-in-the-enterprise/
如果去预测明年的企业级市场趋势,我觉得应用(Application)可能会是最大的关键词,甚至会超过Agent的热度。其实今年下半年已经能明显的看出来,越来越多传统大企业开始将大模型技术引入到业务中,而且他们的特点是“要求高”、“需求刚”、“付费爽”。而一旦大家开始在大模型的应用侧竞赛,RAG在整个业务流程中“白盒流程多”、“易控”等特点愈发会受到企业客户和开发者的热捧,优势进一步拉大。
2.市场变化之2024
关于企业AI应用市场在2024年的变化,我之前已经有写过文章《聊个五分钟的企业AI应用需求发展趋势》,这里就简单再总结一下。
上半年:AI无所不能,大而全
2024年的上半年,AI市场充斥着激情,那种热情似乎走在街上都会扑面而来,个人感觉最主要的推动者是自媒体和模型厂商。模型厂商的出发点很容易理解,快速打开市场嘛,但考虑到他们是要最终交付的,所以相对还是比较理性。但自媒体就一样了,整个上半年看过太多的文章,大家也都是把最好的一面呈现给了大众,所以很多人会觉得我才几个月没关注,AI已经发展到我不认识的地步了,AI已经无所不能了。所以,在2024年上半年,我们接触到的企业需求中,占主流的是那种大而全的需求,要用AI替代他们业务的全流程或基本流程,气味中充满了使用者的野望。
但实际情况并不理想,AI或者大模型还真没到这个程度,而且最关键的是范式转换也还需时间。什么是范式转换?最简单的例子就是以前人们用笨重的蒸汽机推动主轴承转动,带动整车间的机器工作。但是换了电动机之后呢,工作方式变了,动力可是变得非常分散,比如你拿在手上吹头发的吹风机。带着微型电动机的吹风机和传统的蒸汽机在工作范式上就完全不同,采用AI大模型之后,企业的业务流程也存在范式改造的过程,并非一朝一夕可以完成的。
所以,上半年我遇到的、参与的或者听说的那些大而全的AI项目,一半是在可行性推演中没有被验证,一半是交付之后效果很不理想,成功者寥寥。
下半年:回归理性,小而难
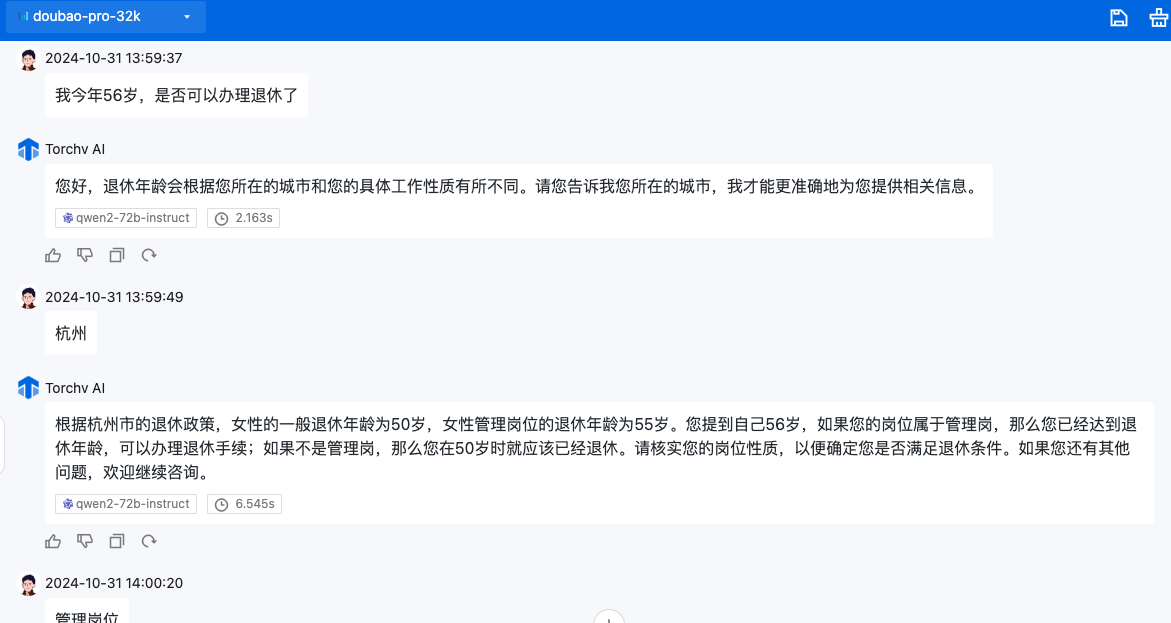
在今年7月份开始,陆续有一些传统大企业找上门来,包括非常知名的企业,以及世界500强和多家中国500强。如果从时间上来说,他们属于AI投入相对较晚的了,但他们的优势是需求非常明确,要求也极高。比如有些企业仅仅就是解决一个咨询服务的需求,在产品范围上就是一个AI问答,但要求准确率接近100%,就像《上篇》说到社保咨询一样。
小而难的好处很明显,我能看到的是下面几点:
- 对企业现有业务流程改造相对较小,内部推动的阻力相对较小,企业客户配合度高;
- 切口小,需求明确,建设成果的考核清晰可量化;
- 使用功能较小但可用性较高的AI产品,可以让企业内部员工快速接受AI,做进一步业务流程改造的前期预热;
- 乐于承接大而全需求的合作厂商多半是外包性质的(这个观点有点伤人,但确实是我看到的现状),而专业的、交付成功率更高的厂商往往更喜欢需求清晰且有难度的任务。
关于2025年的预测
我在上文中已经有提到,2025年会有更多企业需求方采用AI技术,但企业永远不会为你的技术买单,他们只会为他们自己的使用价值买单。比如可以帮助他们提升销售额、业务流转效率更高,或者和竞争对手的竞争中获得优势,还有就是降低成本等等。所以,大模型应用端多端不够,还需要生长出藤蔓围绕着企业流程开花结果,这个任务最终会落在应用(Application)——内化了企业流程、借助了大模型能力的、带有可交互界面的程序。**我自己预测2025年会成为大模型应用或AI应用之争。**
另外还有一个趋势也很明显,就是知识管理和协作。我们都说这波AI浪潮把原来“没用”的非结构化数据给激活了,嗯,所以我们马上会看到那些原来堆在角落里面的“冷”文件和知识(类似wiki)会被大量启用,“热”文件和知识会爆炸性增长,知识的协作和管理会成为新的问题——就像你有再多的先进坦克和战车,却因为无序的交通都堵在阿登森林了。基于大模型的知识管理和协作,会在12月专门写一篇文章好好分享一下我自己的见解,希望能找到共鸣的客户以及开发者。
3.AI从业者观察
因为我看到的不代表真相,所以这一章节会很短,仅仅分享两个发现。
01 AI技术的下坡
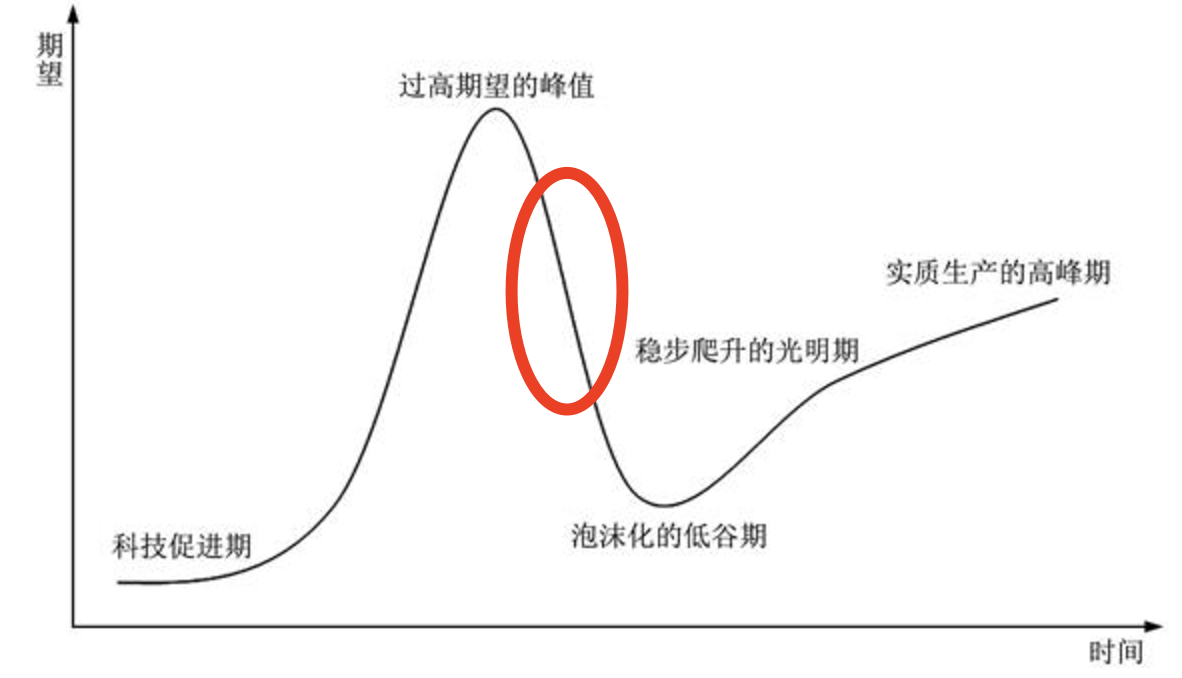
图:技术采用生命周期。现阶段的AI大模型市场似乎正处于过高期望之后的下坡过程中。
有两个感受(非证据)可以说明这一点:
- 关于AI大模型的自媒体数量在减少,从搜索引擎趋势,加上我和几个业内朋友的blog、公众号以及X的阅读量下降趋势也可以佐证这一点,下半年虽然市场理性回归,但整体热度是在下降的。OpenAI不再持续放大招可能也是重要原因之一;
- 我前期接触了很多因为AI热潮而在企业内部抽调精干力量组成的AI小组、AI研究组和AI创新组等团队的成员,但下半年有不少类似团队已经解散,人员回归到原有岗位。
还有一点就是上半年加我微信好友的很多独立开发者或在职的个人,多半也已经在寻觅了半年机会之后放弃了继续探索,这一点在和他们交流,以及他们朋友圈的内容变化中可以明显感知。
但是这并不是坏事,上图已经告诉我们,这是必然规律。
02 价值开始显现
第二个观察就是目前还奔跑在AI大模型应用赛道的公司,很多已经开始创造出客户价值,有了自己的优势。
包括在海外风生水起的Dify,在内容提取端的合合,以及肯定会成为国内AI巨无霸的火山引擎。当然我们还看到了一些深耕垂直行业的优秀团队,特别是在法律、医药、教育等行业。我们也在今年6月份开始做了产品转身,现在已经不再烦恼人家问我们“你们和dify/fastgpt/ragflow有什么区别?”,因为赛道已经开始慢慢不一样了,而且这个不一样依然是产品层面的,和服务什么行业无关。关于这一点,一样还是在12月的那片文章再来分享吧。
三、总结
好了,这篇文章就写到这里了,上篇从个人观点分享了RAG技术这一年的变化,下篇分析了RAG的市场发展情况。最后介绍一下我们自己的产品品牌TorchV,我们通过RAG进行扩展延伸,已经服务了不少大型客户。如果您想在企业中引入AI大模型能力来提升业务,欢迎找我们沟通,以下是我的微信二维码。
(ps:我们最近在招聘实习生,如果您对AI发展非常感兴趣,是在杭州的在校大学生,且有一定的vue/Java/Python编程能力,请联系我。)

