title: 用户手册-快速入门
slug: /getting-started
displayed_sidebar: mainSidebar
版本历史
| 版本 | 作者 | 日期 | 备注 |
|---|---|---|---|
| beta v1.0.0 | 卢向东(yuanwai@mengjia.net)、肖玉民(xiaoymin@mengjia.net) | 2024/02/28 | 初始化 |
| beta v1.6.0 | 卢向东(yuanwai@mengjia.net)、肖玉民(xiaoymin@mengjia.net) | 2024/03/31 | 正式版本v1.0 |
| beta v1.7.0 | 卢向东(yuanwai@mengjia.net)、肖玉民(xiaoymin@mengjia.net)、厉杭波(lihangbo@mengjia.net) | 2024/04/11 | 正式版本v1.1 |
| beta v1.7.3 | 卢向东(yuanwai@mengjia.net)、肖玉民(xiaoymin@mengjia.net)、厉杭波(lihangbo@mengjia.net) | 2024/05/07 | 正式版本v1.2 |
| beta v1.7.5 | 卢向东(yuanwai@mengjia.net)、肖玉民(xiaoymin@mengjia.net)、厉杭波(lihangbo@mengjia.net) | 2024/06/07 | 正式版本v1.3 |
1.引言
1.1 编写目的
本手册旨在介绍TorchV AI用户端的业务及操作流程,以便用户能更有效地进行业务处理和操作。
主要内容

1.2 读者对象
使用TorchV AI产品的运营人员及技术人员
1.3 环境要求
浏览器:Chrome 100+/火狐(FireFox)/Microsoft Edge
1.4 产品架构说明
本文不展示具体产品架构,如您需要查看TorchV产品架构,请点击TorchV产品架构查看。
2.快速开始
TorchV AI包含了诸多企业AI应用搭建的功能,但作为快速入门,我们可以通过三步掌握TorchV AI的使用:
- 创建和维护**
知识库**; - 使用**
Chatbot**开始试用,如果您只是进行试用,到此已经完成了; - 如果您想将TorchV AI 提供的能力接入到您自己的应用中,还可以创建和管理**
应用**。
好,接下来我们一起用5分钟了解如何快速使用。
2.1 创建和维护知识库
Path:知识管理 —> 知识库
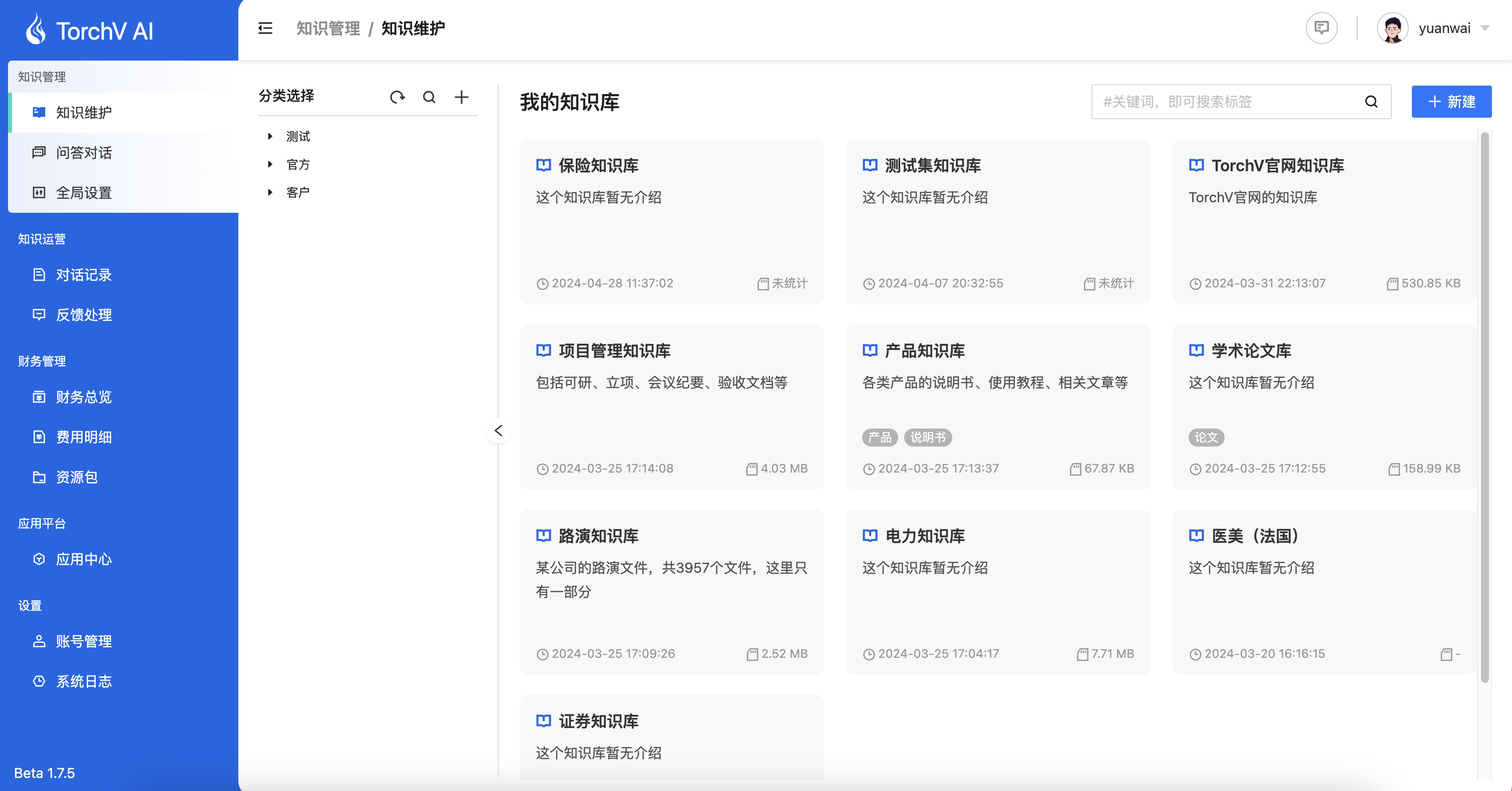
图1-1:知识库主界面
在知识库板块,您可以创建多个知识库,如“财务知识库”、“销售知识库”、“人力资源知识库”等等。区分知识库的目的是为了在后面提到的应用中能为每个应用绑定不同(一个或多个,最大10个)的知识库,让不同的应用可以服务不同类型的用户群体。
为了用户能有效管理越来越多的知识库,我们在v1.7.3增加了知识库分类和标签功能。
分类:是按树形结构分布的,从上下关联的角度去区分知识库的类型。用户可以在左侧的树形结构中选择分类,目前支持“大分类-小分类-知识库”的分类组织方式;
标签:是按知识库的特点进行标记,与分类树形结构无关,相较于分类的纵向树形结构,标签可认为是从横向进行打标,形式上更加灵活,是分类之外的一种补充。

图1-2:知识库的分类与标签,(v1.7.3) 增加知识库分类与标签,方便对知识库进行分类、查询等管理。
2.1.1 创建知识库
您可以点击右上角的+新建新建知识库,同时也可以
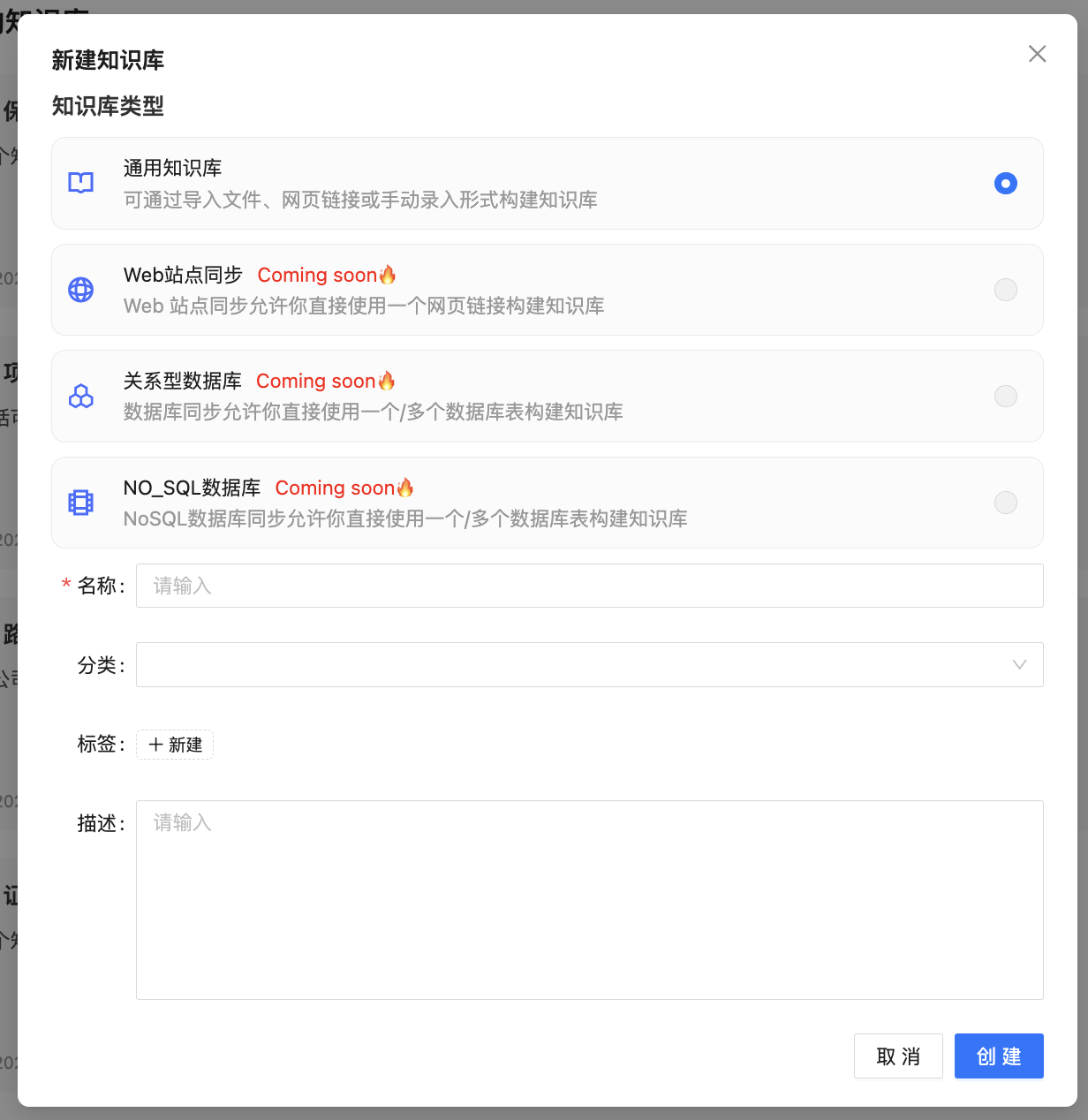
图2-1:创建知识库
目前我们只开放通用知识库,后续会增加另外三种知识库的创建:
- Web站点同步:目前暂时支持单个网页URL方式导入,关于URL导入详见关于web页面导入;
- 关系型/NoSQL数据库:会首先进行ETL过程,如数据库链接测试、表格选取、schema复制等,然后建立loading计划,进行关系型数据库/NoSQL数据库的数据抽取;
- API GET操作:可以根据用户提供的API进行数据抽取和同步,维护知识库的数据更新。
OK,这些是后续的功能,这里我们可以先不关注,下面先来看看创建了知识库之后的内容,这里我们先关注通用知识库的创建。创建的过程非常简单,只需要填写知识库名称即可,当然为了后续管理和使用上更加方便,您可以在创建时将分类和标签也一起完成创建。
2.1.2 维护知识库
创建好知识库之后,我们点击进入,接下来开始维护知识了。
这里您应该看到我们刚刚创建的知识库开启第一个知识库的界面,空空如也。如果您想上传一个PDF先试试手,这时候您可以从桌面直接拖拽一个文件到当前页面,我们一起来看看会发生什么?
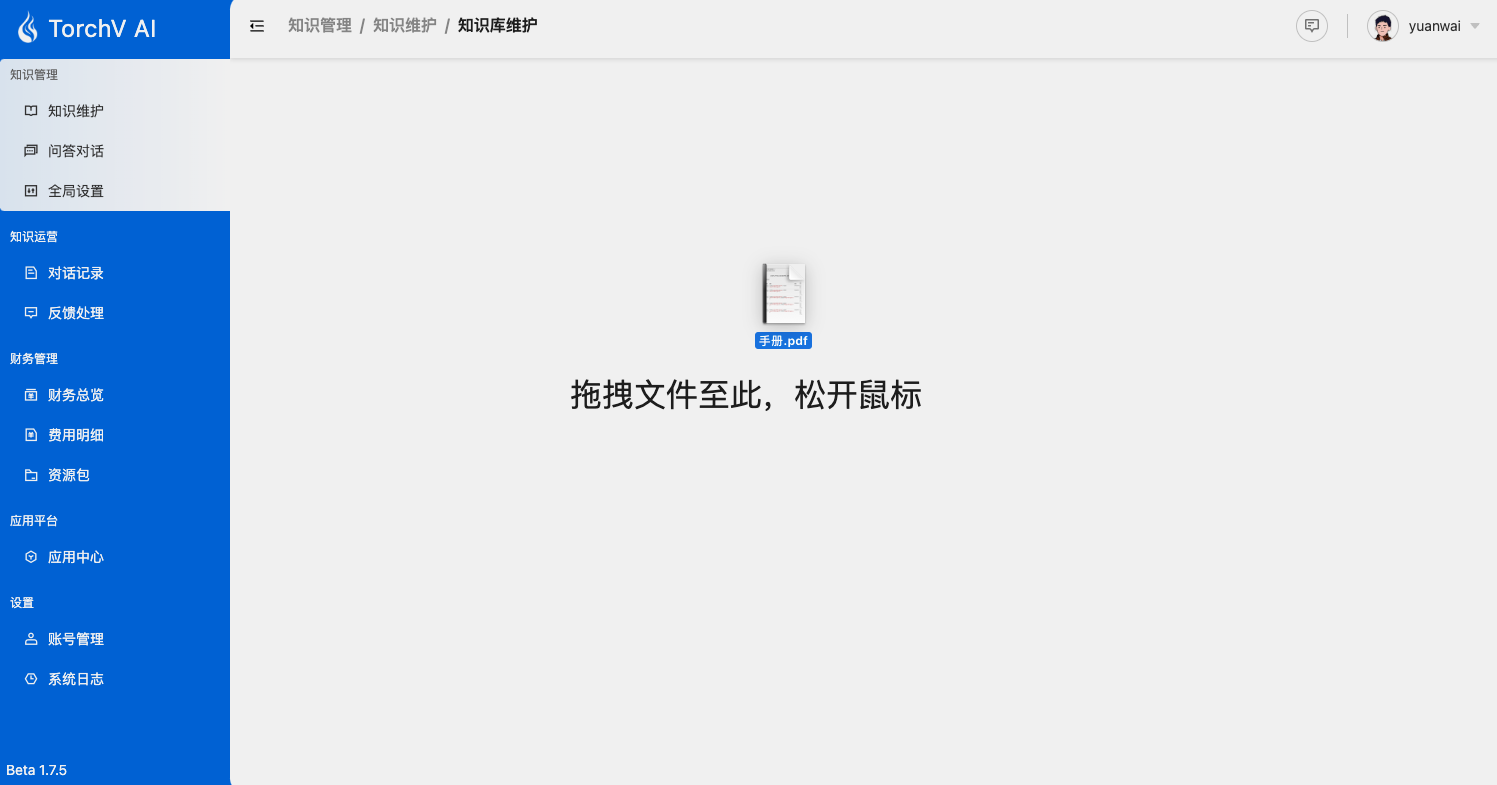
图2-2:将文件拖拽到知识库页面即可上传文件。
下一步您将看到的就是刚才被拖拽的文件被分解(预览),在该界面我们首先可以查看文件是否被系统正常分块处理预览,一般提供TOP10页的预览。另外您也可以为文件设置生效时间,如让特定文件在次月1日生效,次月30日失效(不再提供该内容的对话、检索),默认是永久生效,既从文件处理完成开始一直有效。
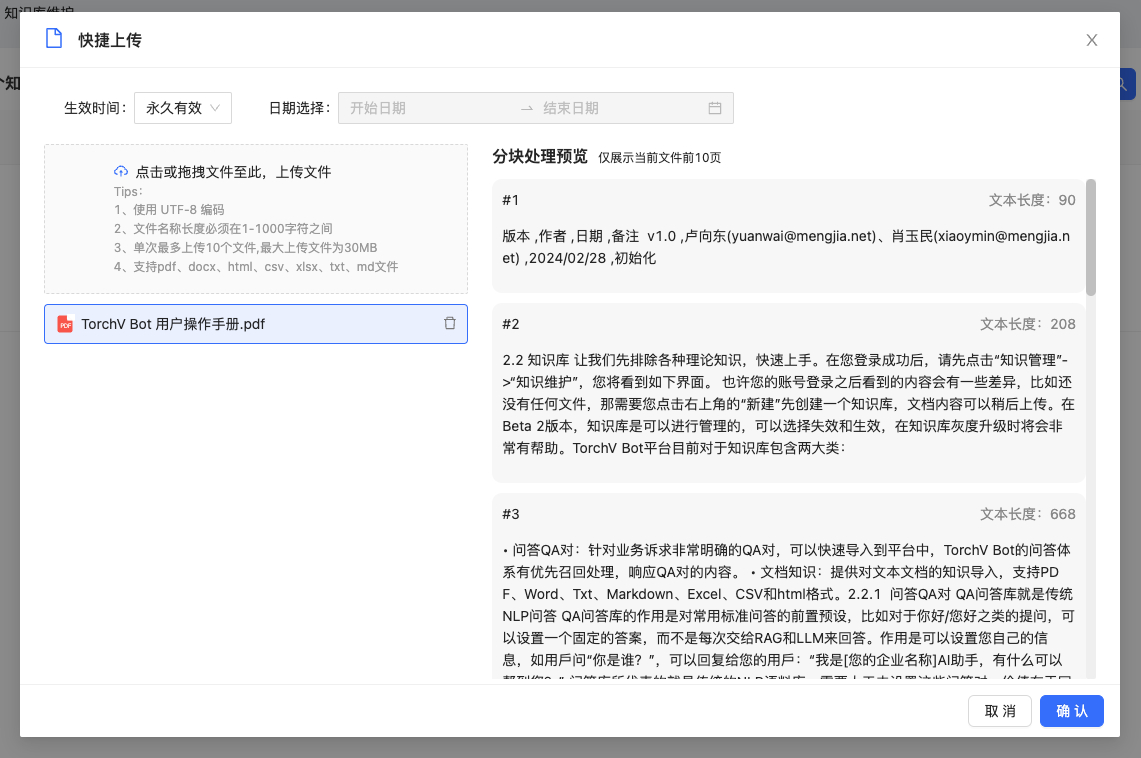
图2-3:文件分块处理预览
一旦点击“确认”按钮,文件将进入处理队列,接下来的一些处理流程如下:
- 等待调度程序(scheduler)从waitlist中将文件处理的任务激活;
- 文件元数据处理和记录;
- 根据文件类型、内容疏密程度等多种因素对文件进行分块(chunking);
- 将分块之后的内容进行embedding处理;
- 建立索引,包括向量索引和BM25类型的倒排索引;
- 处理完成。
从下图2-4中也可以看到一般文件处理的状态更新过程,您可以点击🔍按钮进行刷新。

图2-4:处理过程的三个状态。其中处理中可能需要一些时间,特别针对较大的文件。
好了,我们的“快速开始”环节,知识库创建就算完成了。当然TorchV AI提供了多样化的知识库维护支持,包括:
多类型文件:包括pdf、ppt、pptx、doc、docx、xls、xlsx、csv、txt、md、html、png、jpg等;
Web导入:直接复制目标网页的url,注意,这里只支持单页面内容的获取,不支持页面上出现的链接的自动爬虫;
纯文本:可以认为是用户自行创建一篇文章,而我们也将继续升级该板块,升级为类似Confluence、Notion和语雀等类似的文章编辑功能,带附件📎上传(附件类似于上面的多类型文件);
QA对:问答对,用于维护那些常见问题的解答,如“你是谁?”、“你好”等,QA的优势是回复幂等(连续问1万次,回复都是一样的)。另外还需要说明的是,QA的问答处理顺位是最高的,一旦用户的问题被QA处理,那么排在后面的处理顺位(RAG、LLM等)都将不再启用。
QA对批量:提供了批量上传的模板,内容包括知识标题、相似问法、开始日期、截止日期和答案,用户可以根据模板进行内容维护,然后一次性批量上传。
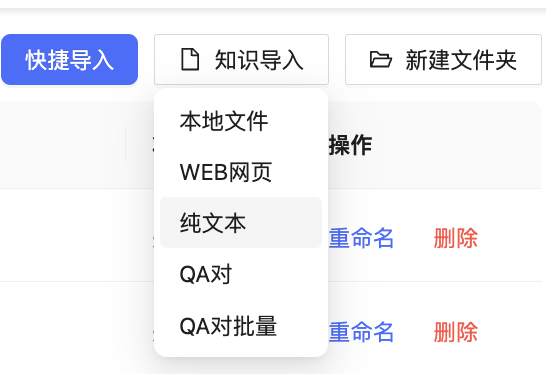
图2-5:除了文件之外,我们还支持更多其他方式的知识维护。
2.1.3 小结
知识维护其实就这么简单,总结一下:
- 创建知识库
- 维护知识
2.2 测试问答效果
Path:知识管理 —> 问答对话
在2.1 “创建和维护知识库”章节中我们已经完成了第一个知识库的创建,接下来让我们来对它进行测试,请点击“知识管理”->“问答对话”进入问答功能。
目前“问答对话”的界面做了较大优化,且使用了全屏模式。
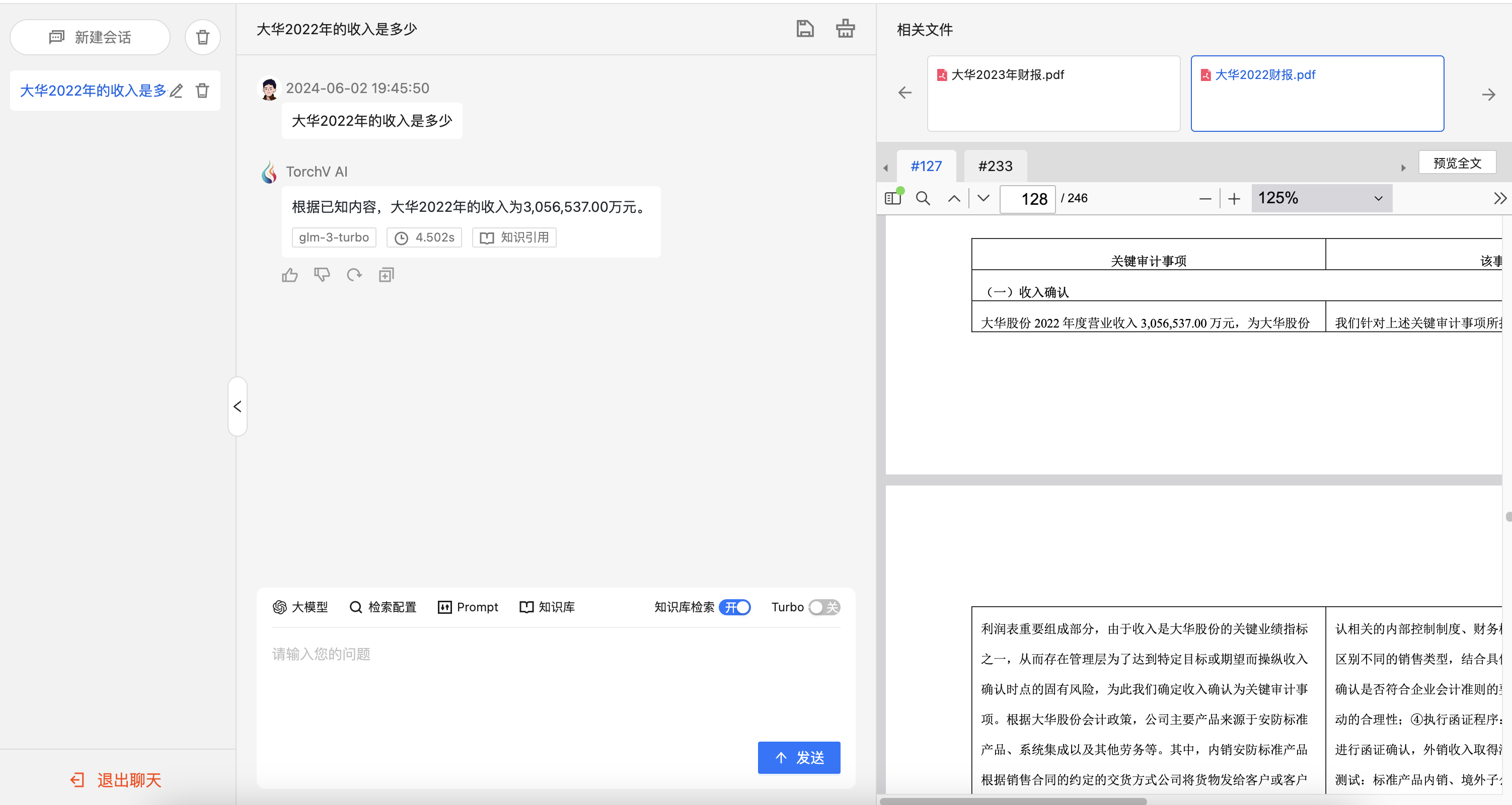
图2-6:TorchV AI内置的Chatbot界面,主要提供用户测试使用。
完整的界面功能分为三大块:
- 会话导航区:在左侧顶部可以看到“新建会话”和删除会话等功能。这里需要讲一个会话的作用,单个会话是存在上下文关联的,多轮对话的作用范围仅限于同一会话中。同理,如果您已经调整了参数或上传了新的知识内容之后,尽量开启新的会话进行操作,避免被上文干扰;
- 问答区:中间部分的主要区域均为问答区,最下面是输入框,用户可以在这里输入想要对话的内容,点击“发送”与系统对话。中间包含各种集成的参数配置工具栏(toolbar),详情可查看参数设置工具栏。上面的部分是对话区,包括用户的提问,系统的回答。当您点击引用文件时,右侧的默认收起的原文引用区会展开,现实被应用的内容原文;
- 原文引用区:默认会展示被引用文件的具体页面内容,如存在多个来源,会通过选项卡的方式展示在最顶部,如上图所示。
当您对前面上传的资料进行了充分问答之后,我们2/3的流程其实已经完成了,是不是非常简单易用。
当然,真实的企业应用中并不会那么一方风顺,我们会遇到各种问题。因为我们提供的试用系统是一个通用产品,并没有对不同使用场景进行特别优化,所以不适配的情况肯定会存在。
下面的2.2.1和2.2.2就是一些调试和反馈的具体方法。
2.2.1 参数设置和调试
图2-6中我们可以看到在提问区的上方有各类参数调整的工具栏(Toolbar),下面我们来讲述如何在不同场景对参数做调整。
图2-7:参数调整工具栏
2.2.1.1 大模型

图2-8:大模型工具栏的截图
大模型选项卡主要用于选择使用什么底层大模型,当然您也可以使用智能调度。
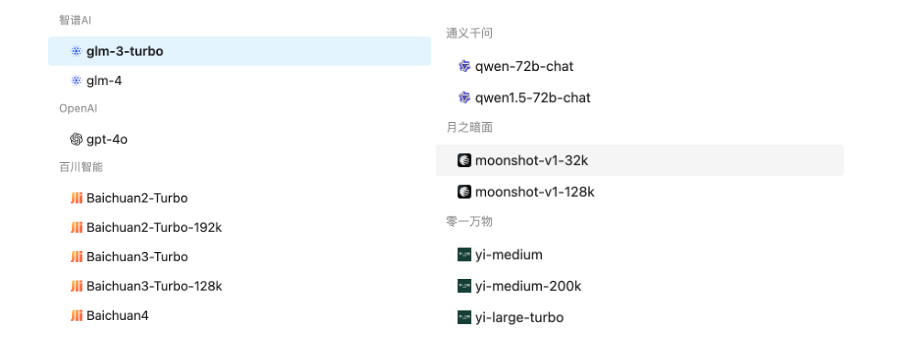
图2-9:目前接入的大模型种类
创造性和多样性可以帮助用户在不同场景选择更加合适的大模型属性,比如在严肃场景,我们可以将创造性和多样性降到最低,以减少大模型在归纳生成的时候“添油加醋”(有时候是画蛇添足,并不一定是幻觉)。
2.2.1.2 检索配置
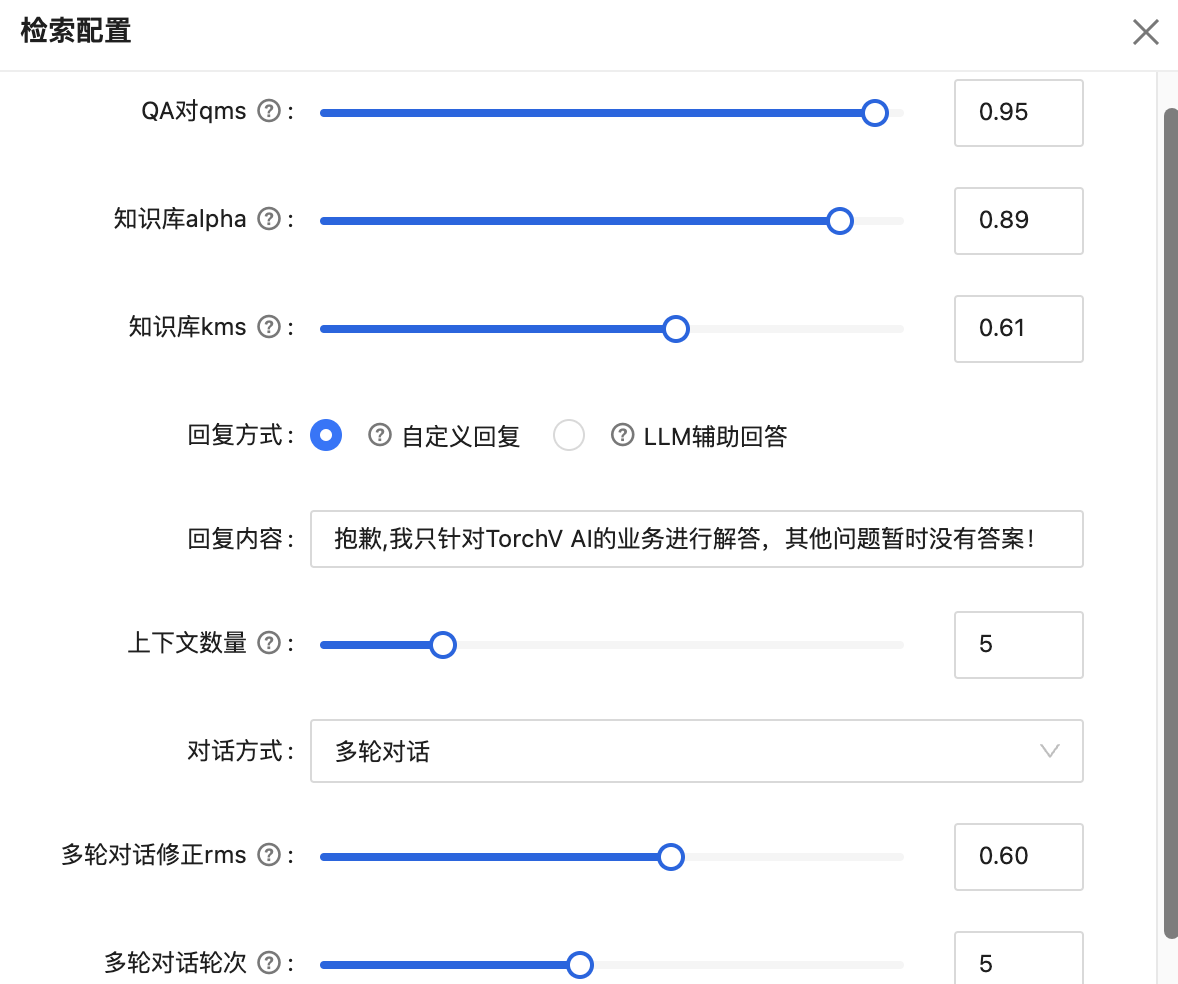
图2-10: 检索配置的参数截图,这是全局检索配置,也是本系统中最难的一个环节。
QA对qms:TorchV AI支持用户设置QA对,比如“你是谁?”这些常用语的回答,直接用QA对来回复的好处是准确、幂等,它的优先级也是最高的,如果QA对已经被触发,系统不会继续经过RAG管道和大模型处理。所以我们对qms的分值要求也会比较高,比如0.95(满分1);
知识库alpha:我们使用了混合检索,也就是BM25+相似度匹配,用户输入的问题非常书面化的情况下,BM25是非常有优势的,分值可以降低一些;如果用户输入的问题比较口语化或者比较模糊的时候,相似度匹配会更优秀,分值可以提高一些。所以,我们可以在不同的场景调整相应的比例;
知识库kms:kms就是knowledge-min-score(知识库chunks召回分值的阈值)的意思,当用户提了一个问题:
- 系统检索之后召回的所有chunks分值有高于当前kms(如当前的0.61),那么系统会将这些召回的chunks和问题送入大模型进行生成处理;
- 如果所有召回的chunks分值都小于当前kms,那么就需要结合下面的“回复方式”来进行具体操作了。
- 如果在“回复方式”里面选择“自定义回复”:那么用户将得到的回答是“抱歉,知识库里面暂时没有改问题的答案!”,这种方式回答会比较严肃,也是一种对抗大模型幻觉的有效方法。
- 如果在“回复方式”里面选择“LLM辅助回答”:那么系统就会将用户问题直接送入大模型进行生成回复,这种方式的幻觉产生几率相对较高。具体如何选择,可以看实际的使用场景做决定。
多轮对话:首先我们可以选择“对话方式”,默认是多轮对话,当然,如果你不想上下文可能的干扰,也可以选择单轮对话。在多轮对话模式下,多轮对话修正rms的分值表示的是对于用户的当前提问,如果和上文高度相关(如相关度得分高于0.60),那么可以引用上文的问答内容对当前问题进行补齐,如上文问了“杭州有什么好玩的”,现在的问“有什么好吃的?”,会被补齐为“杭州有什么好吃的?”。多轮对话轮次则表示最多可以往上引用几轮的对话内容。
这应该算是TorchV AI中最复杂的配置功能了。
2.2.1.3 prompt管理
这是全局的prompt管理,默认情况下可以不做改动,但如果您对prompt知识较为熟悉,可以进行修改。
2.2.1.4 知识库
知识库选项卡在默认情况下是“全部知识库”,也就是全选状态。当您需要选择特定知识库时,可以点击“部分知识库”,可根据需要选择多个知识库,可选择的知识库最多是10个。
2.2.1.5 知识库检索开关
选择开,则表示本次问答经过知识库;选择关,则直接与当前选择的大模型进行对话。
2.2.1.6 Turbo开关
默认选择关;如果选择开,则用户的问题将会先被进行详细拆分,分析出里面的意图和多种实体关系等,然后再进行多路检索和召回。Turbo打开的情况下,会比平时更加消耗Tokens,也会更加消耗时间。
2.2.1.7 小结
根据您的实际使用场景进行参数调整,将会有助于您提升使用效果,主要的调整项包括:
- 大模型选择:如果业务逻辑和计算较多,请选择大参数模型;
- 检索配置:讲述了QA的使用场景,用户输入内容的不同对混合检索的影响,如何对抗幻觉,如何使用多轮对话,prompt编写,知识库选择,Turbo开关的用途等。
2.2.2 评价和反馈
如果有些问题用户无法自行解决,也可以向系统提交反馈,如我们可以在回答的下方进行满意度评价:
图2-11:在回答下面的反馈按钮。
如果是不满意的反馈,请帮忙输入更多详情,这样我们可以更快定位到问题,先感谢您的善良!
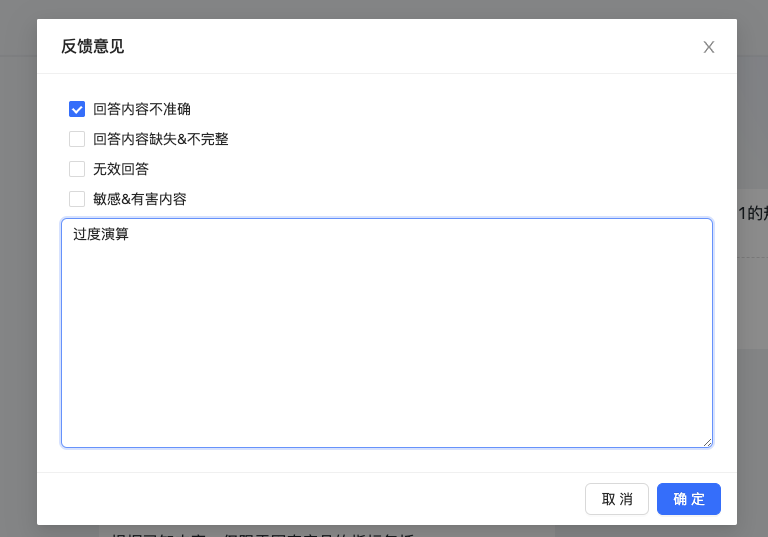
图2-12:对于不满意反馈,可以说明不满意的主要原因。
在“知识运营-反馈处理”里面可以看到刚刚反馈的这条信息:
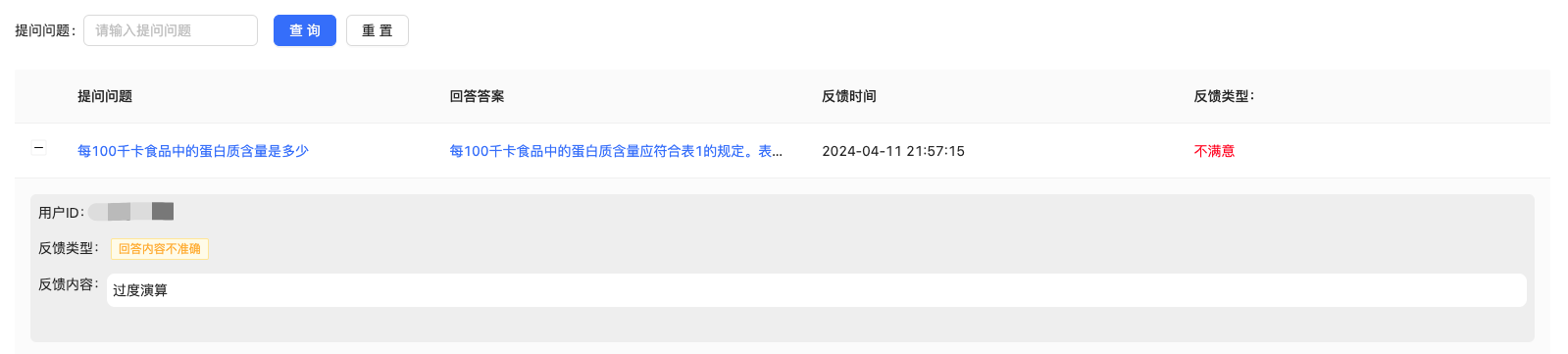
图2-13:在后台可以看到反馈结果。
就像开头讲的,如果您只是测试TorchV AI的问答能力,基本上到此为止就差不多了。但是如果您想让TorchV AI的能力对外发布,帮助您的业务AI化,那么2.3 应用创建将会非常重要,我们也简单预览一下。
2.3 应用创建
Path:应用平台 —> 应用中心

图2-14: 应用中心首页
2.3.1 创建应用
在应用中心界面的右上角点击+新建,创建你的第一个应用。
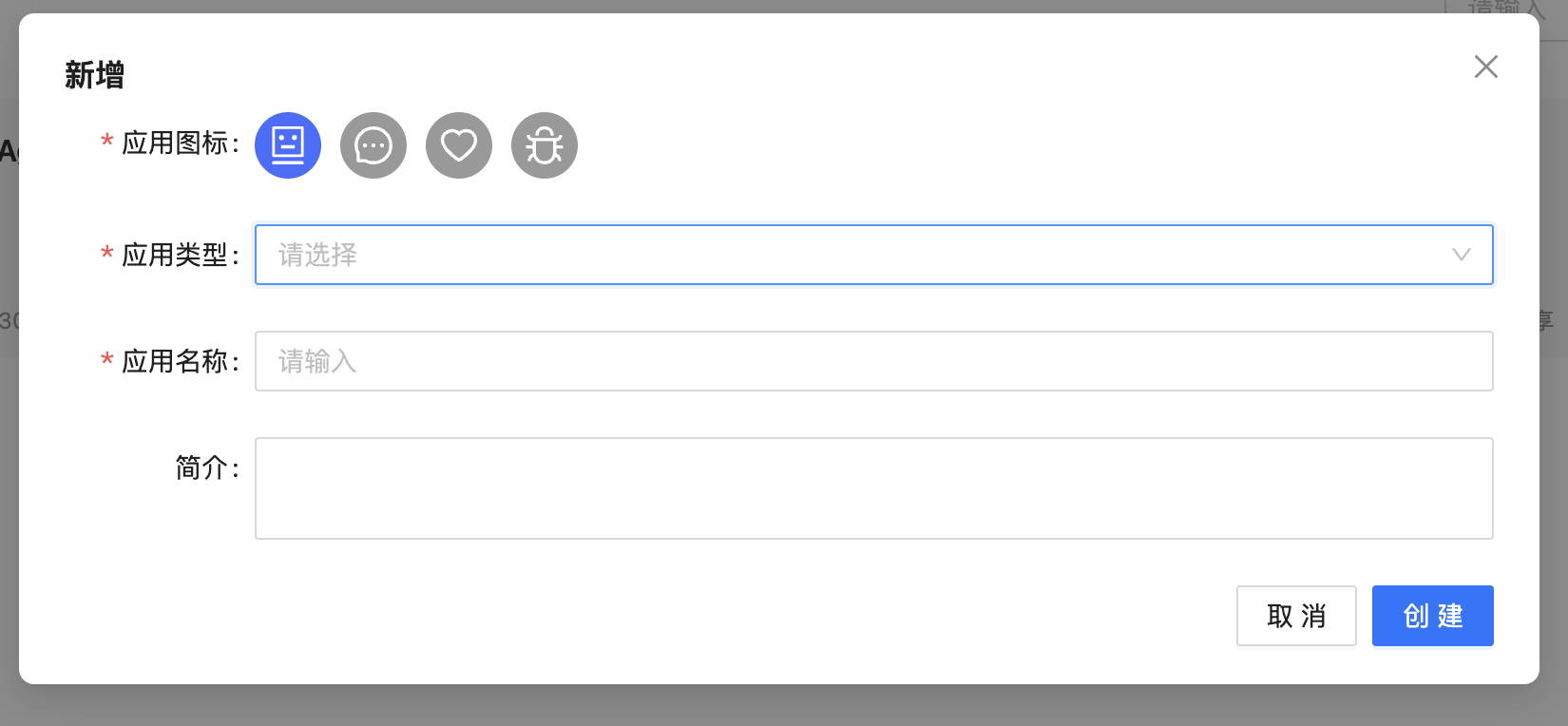
图2-15:创新应用
在应用类型里面有两个分类,ChatBot和轻量级Agent,现阶段我们建议您采用ChatBot类型。
轻量级Agent应用还在更新中,后续会完成可自助创建多个prompt控制的Agents的功能,类似于多个面具。
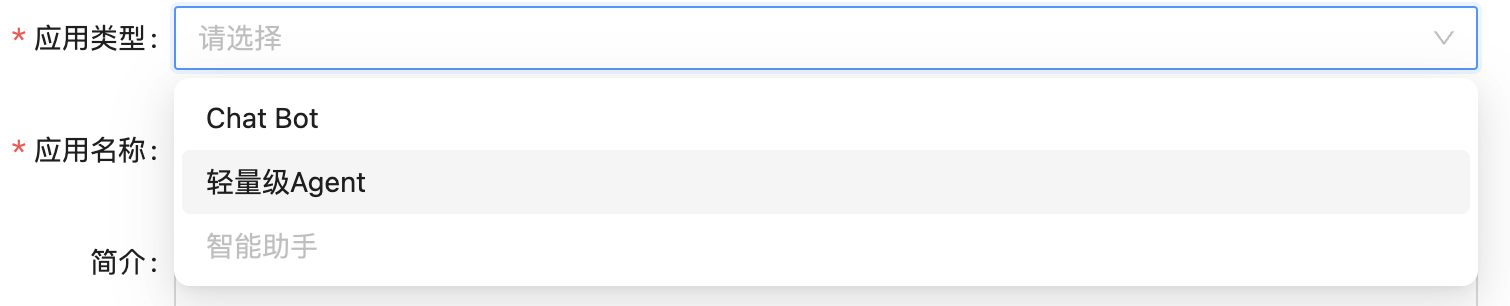
图2-16:应用类型
2.3.2 应用工作台
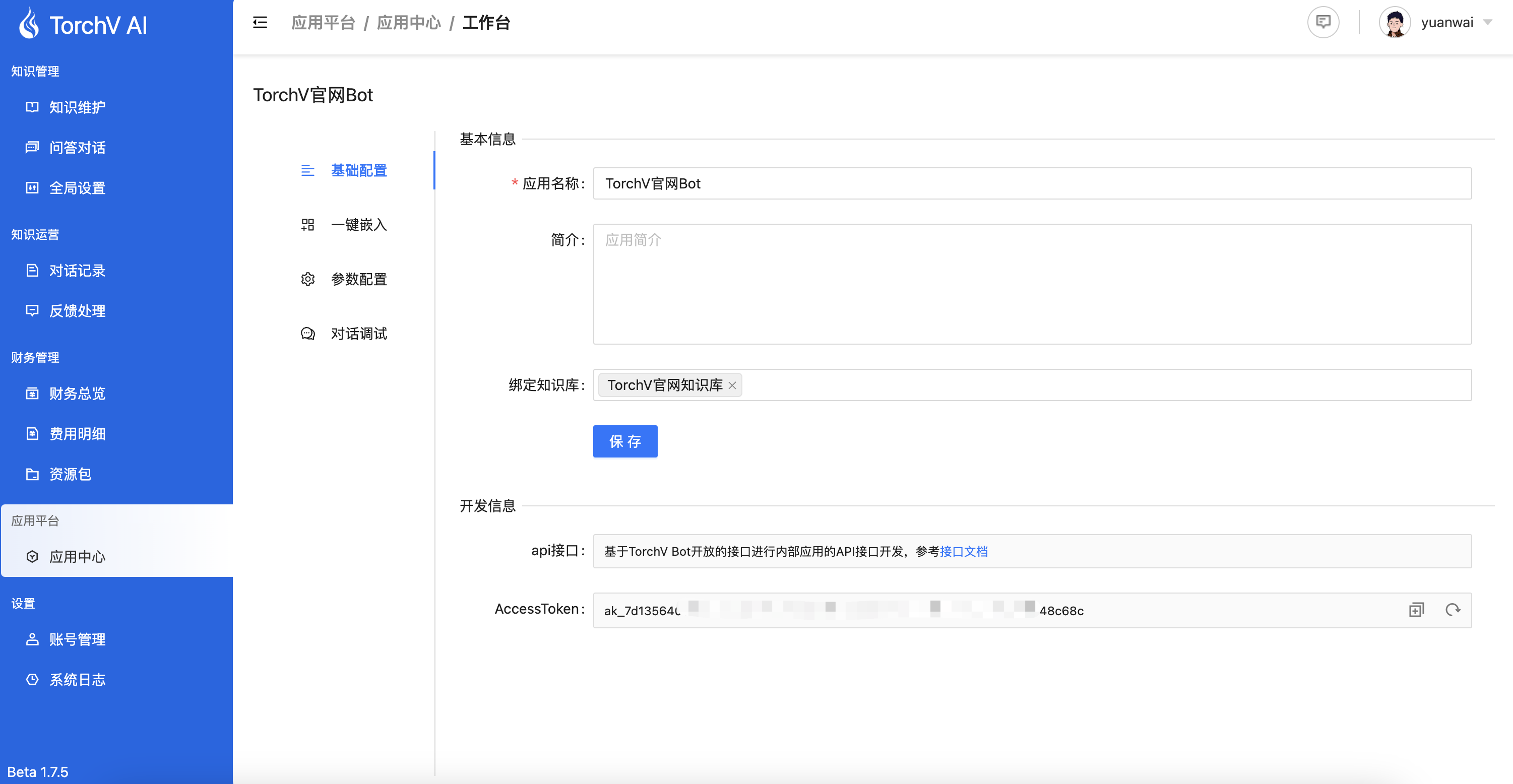
图2-17:应用的工作台(playground),提供应用的基础信息编辑、配置修改、一键嵌入功能和调试等功能。
2.3.2.1 基础配置
与图2-17中所示一样,这里不展开描述。
2.3.2.2 一键嵌入
一键嵌入的主要作用:快速将TorchV AI的chat能力嵌入到用户自己的官网、电商网站和Web版的业务系统中,整个过程只需复制几行js代码到目标系统/网站的Header中。
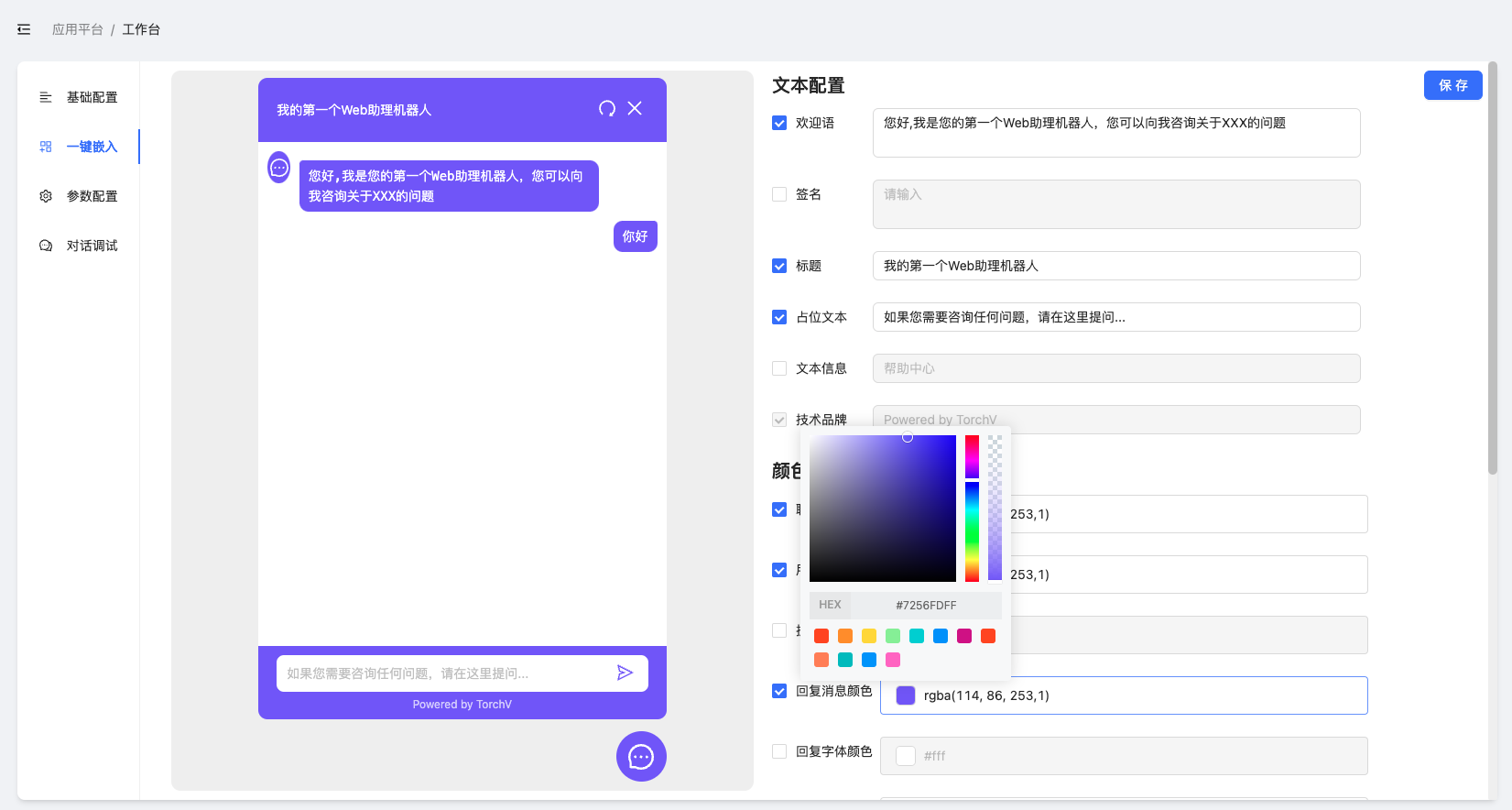
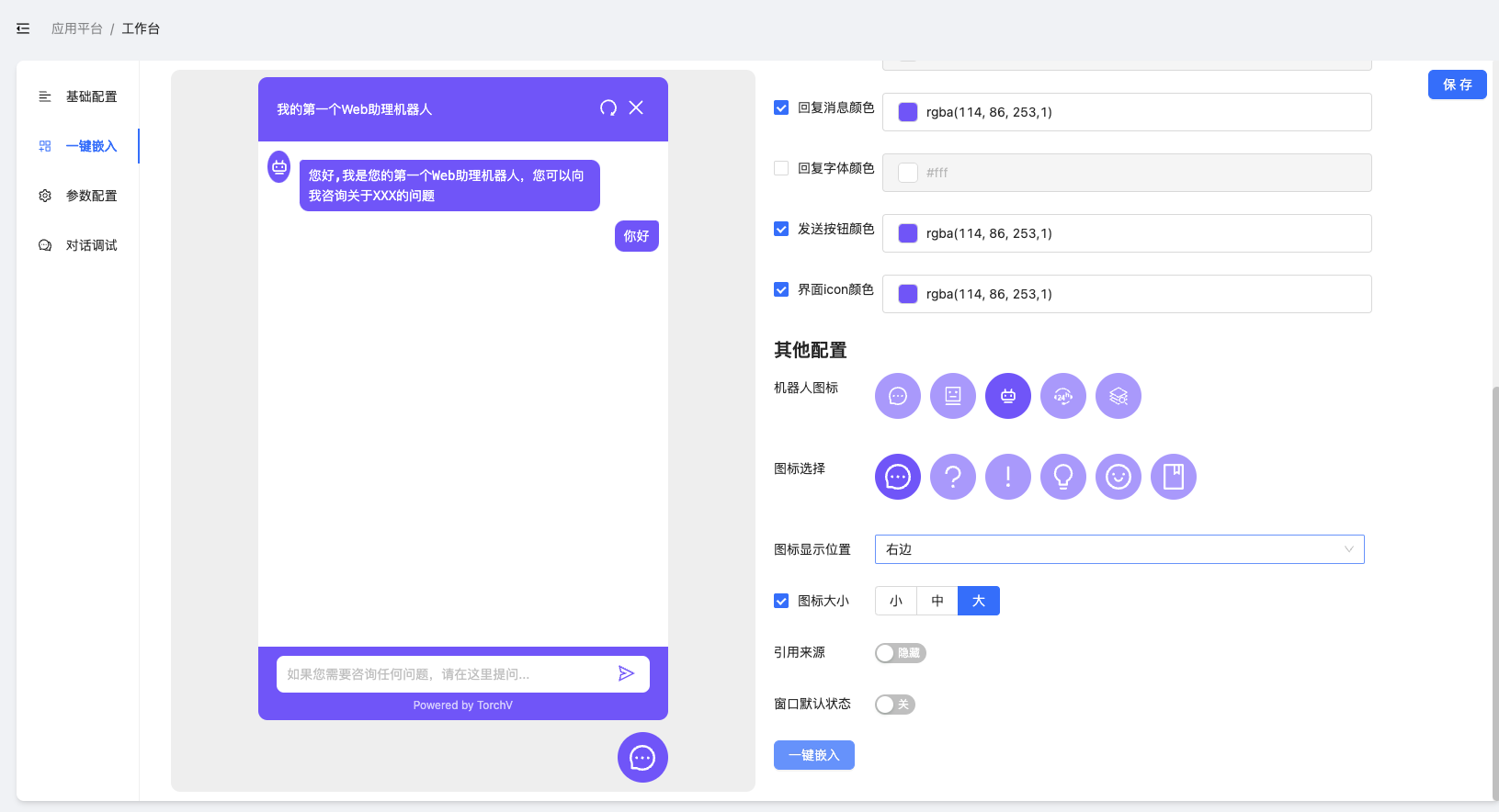
图2-18、图2-19:一键嵌入界面
我们在自己的官网做了一键嵌入,为访客提供咨询服务,知识库来源于TorchV概览(Getting-Started)和操作手册(Manual),下图是截图效果:

图2-20:TorchV官网的一键嵌入截图
2.3.2.3 参数配置
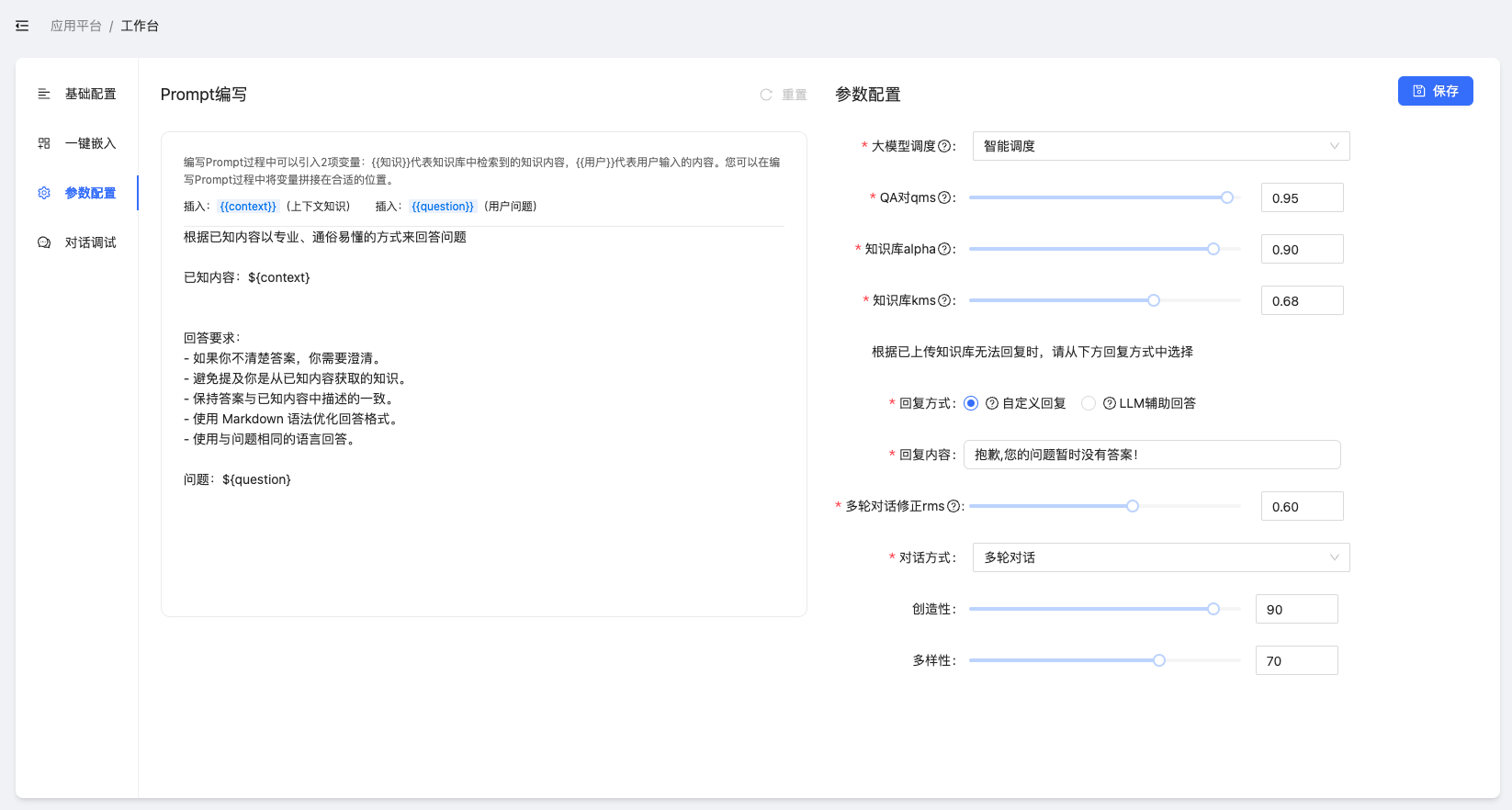
图2-21:应用的参数配置
这里的参数配置与知识管理-全局设置、问答的工具栏中的功能几乎相同,但是权限范围不一样,应用中的参数配置仅作用于当前应用,而知识管理-全局设置则是全局默认配置。
关于参数配置,可以参看 2.2.1 参数设置和调试 ,本节不再赘述。
应用中的参数配置仅对该应用起到作用,所以用户可以在”对话调试“中根据不同场景调整参数配置,以获得最佳效果,别忘记”保存“。
2.3.2.4 对话调试
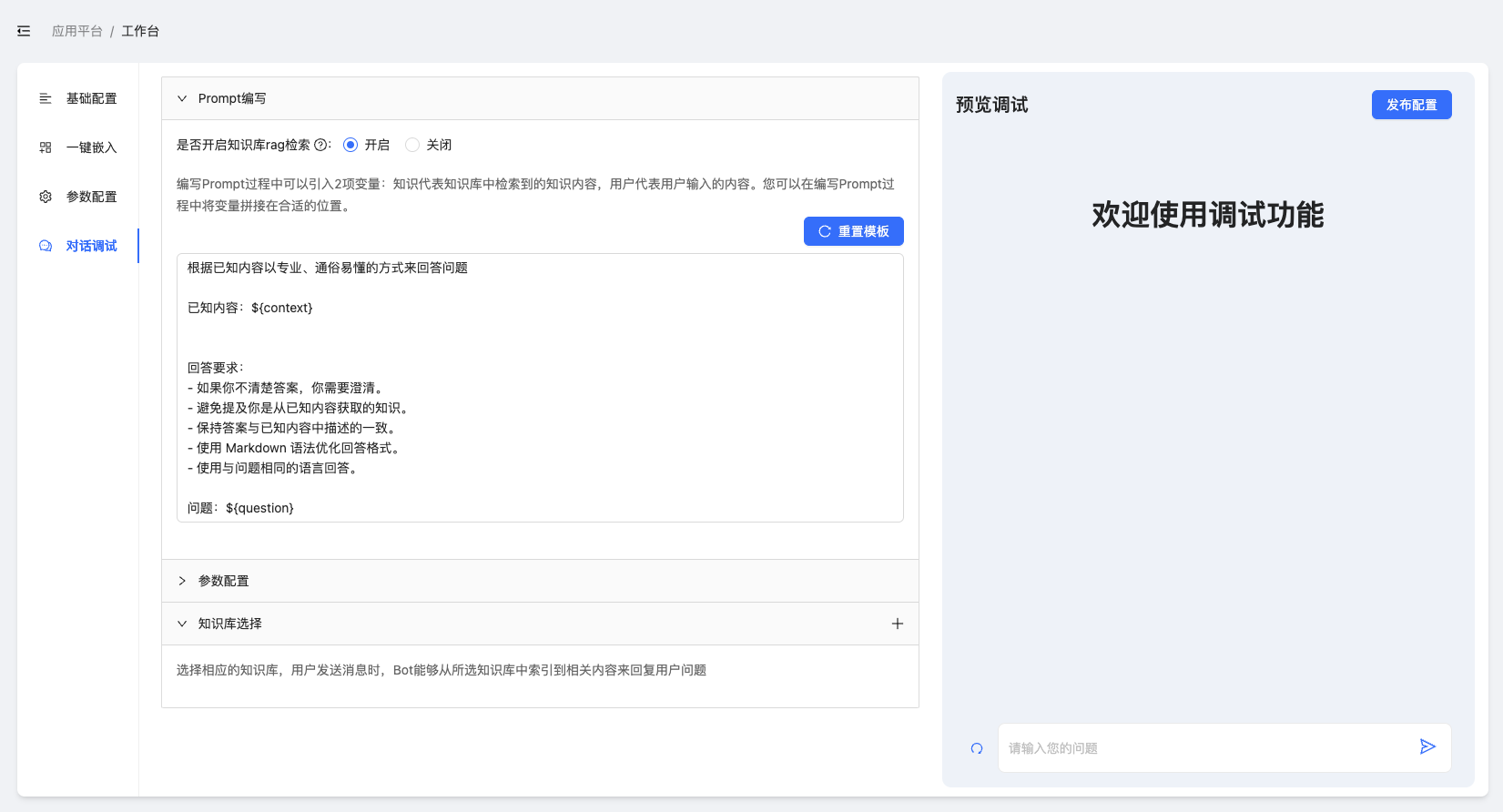
图2-22:对话调试功能
prompt编写
在图上可见,左侧最顶部是prompt编写,用户可以自行编写prompt模板,既RAG系统最终送给LLM的内容模板。其中的${context}是RAG在知识库中检索召回的最终内容,${question}是用户输入的最初问题。
在界面层面,只能维护一个prompt模板,也是默认生效的模板。但是如果您使用API进行应用开发,则可以在自己的应用中维护多个prompt模板,然后在不同的功能中将个性化prompt模板送入API的
promptTemplate属性中。一旦promptTemplate不为空,默认的prompt失效。
参数配置
与2.2.1 参数设置和调试的内容一致,细节不再赘述。
但需要注意的是,在对话调整功能中的”参数配置“属于临时配置,调整之后即在右侧的预览调试中生效。但如果最终用户未点击”发布设置“,调整后的参数将会在关闭或跳转页面之后失效。如果用户点击了”发布设置“,则该配置参数会同步到2.3.2.3 参数配置中,覆盖原有配置。
知识库选择
在知识库选择的最右侧,点击+按钮进行知识库选择,可以进行多选。
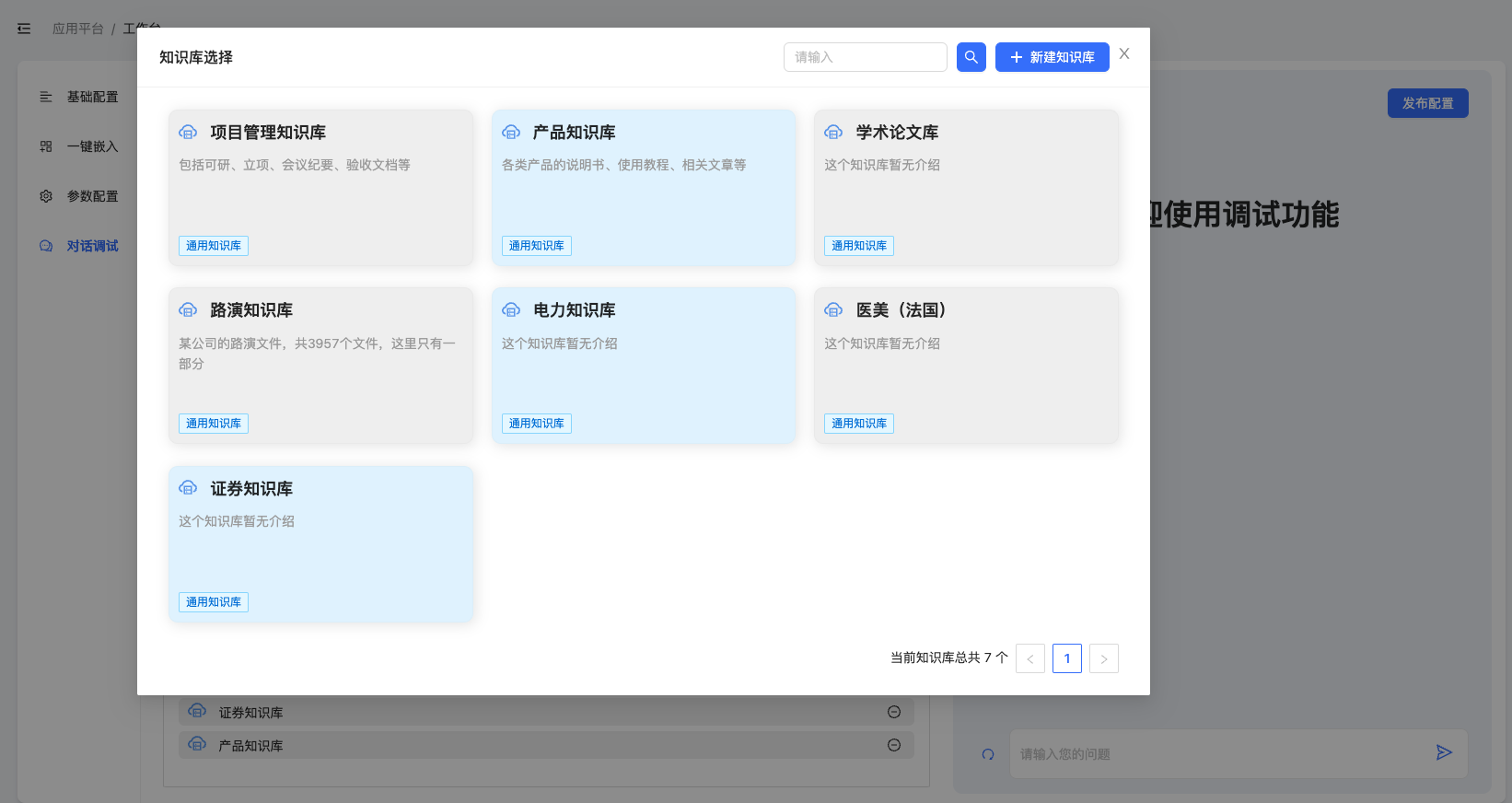
图2-23:知识库选择,蓝色为已选择知识库。
只需点击弹出框外,就可以看到已经选择的知识库绑定:
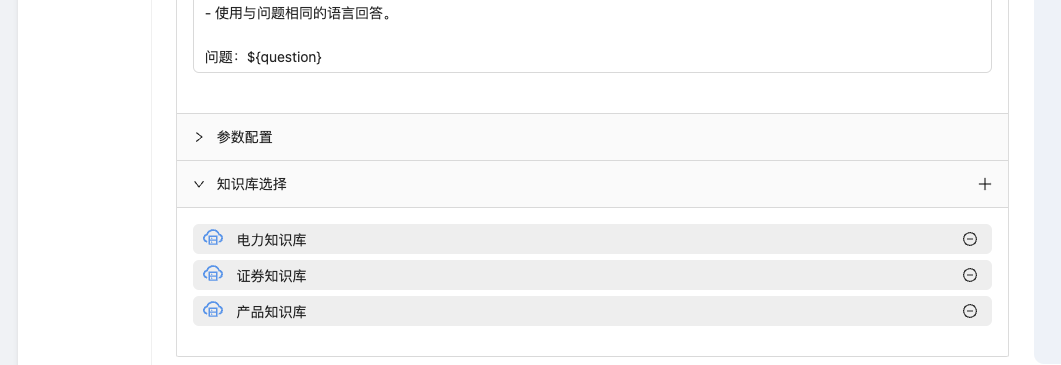
图2-24:知识库绑定显示
2.4 快速开始总结
经过以上的知识库创建、问答测试和应用创建,您已经可以完成TorchV AI的全流程使用了,就是如此简单。
现在,您可以有以下方式使用TorchV AI:
- 在
知识运营—>问答对话中进行试用,但该方法适合于测试; - 创建自己的应用,使用一键嵌入功能,将TorchV AI的对话能力嵌入到您的官网或其他Web版系统中,这是对外释放能力最快的一种方式;
- 使用API对接您自己的应用,或者使用API创建新的应用,让您的更多客户享受到TorchV AI为您带来的AI能力。
Enjoy!

