原作者:Deval Shah
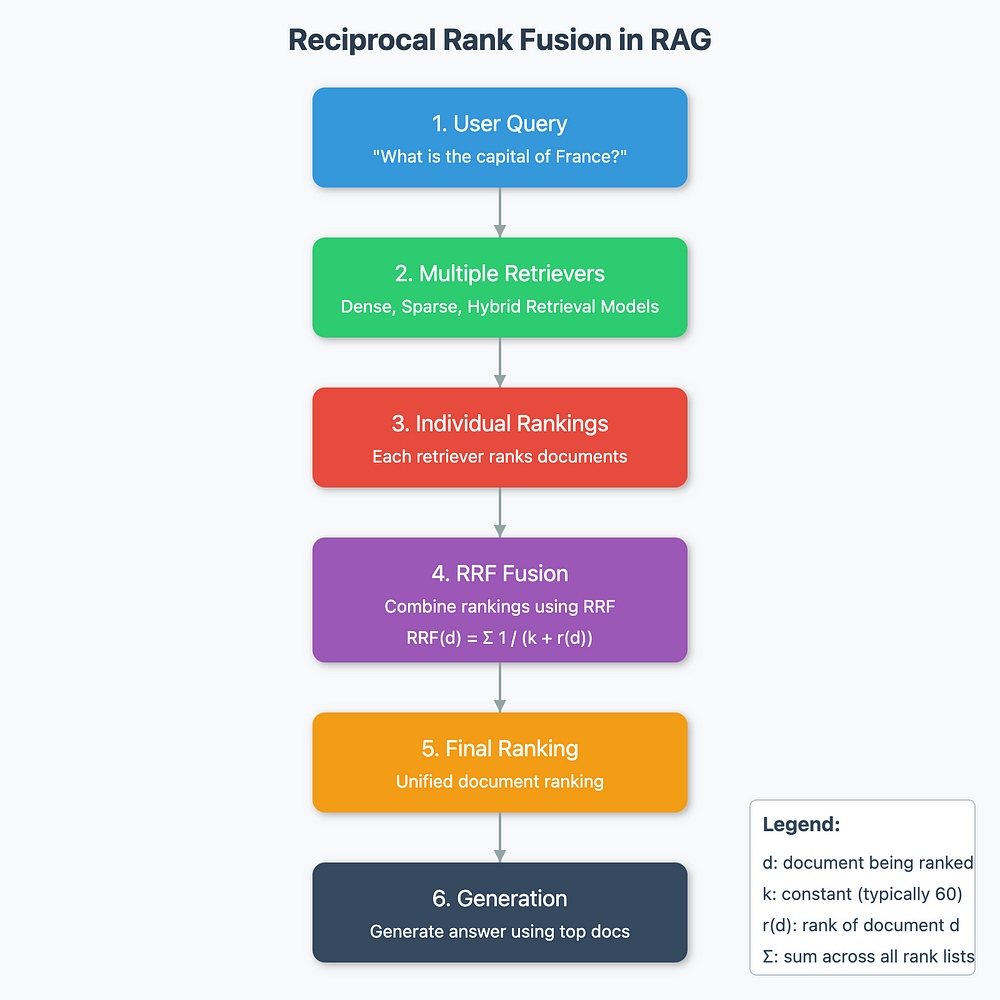
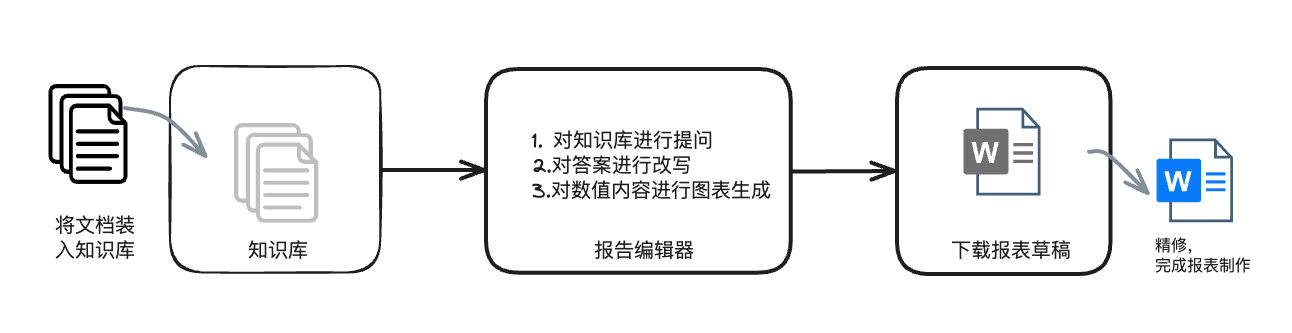
图:RAG 中的倒数秩融合(图片由作者提供)
检索增强生成 (RAG) 是自然语言处理中的一种强大技术,结合了基于检索的模型和生成模型的优势。
检索阶段可以成就或破坏您的 RAG 管道。
如果检索器未能从检索器中获取相关文档,则精度较低,幻觉的可能性会增加。
有些查询适合基于关键字的检索技术,如 BM25,而有些查询在密集检索方法中可能表现得更好,其中我们从语言模型嵌入了 embedding。有混合技术可以解决这两种检索方法的缺点。
在这篇博文中,我们将深入探讨 RRF、它的机制、数学直觉和在 RAG 系统中的应用。