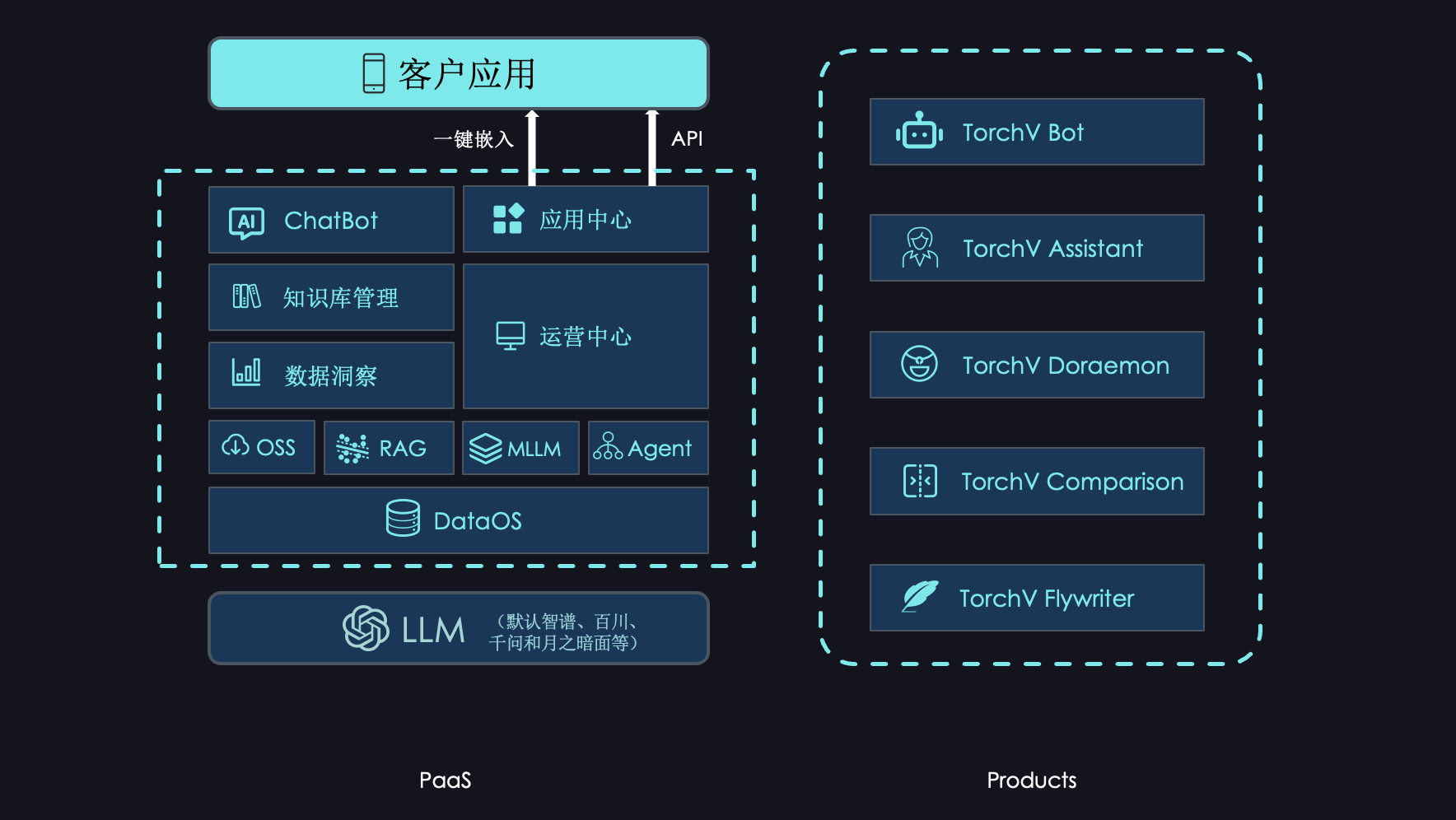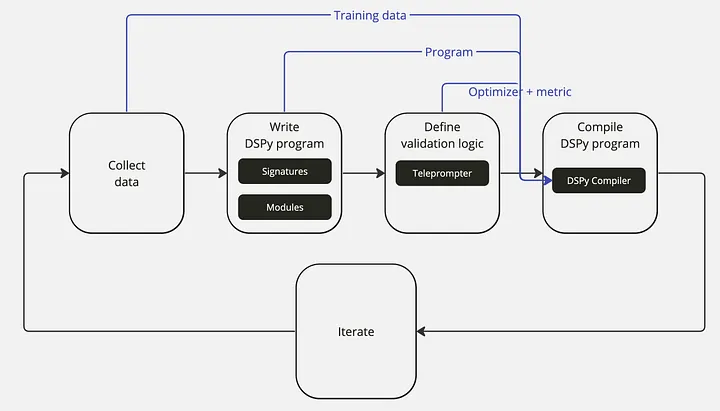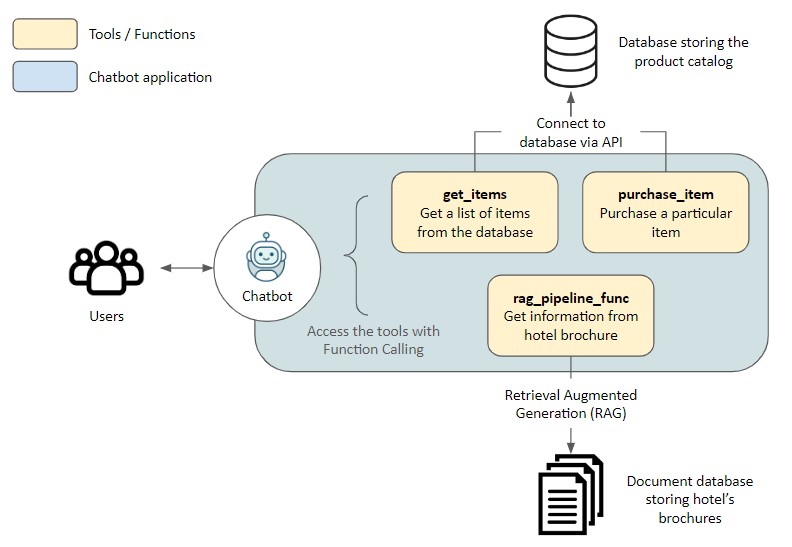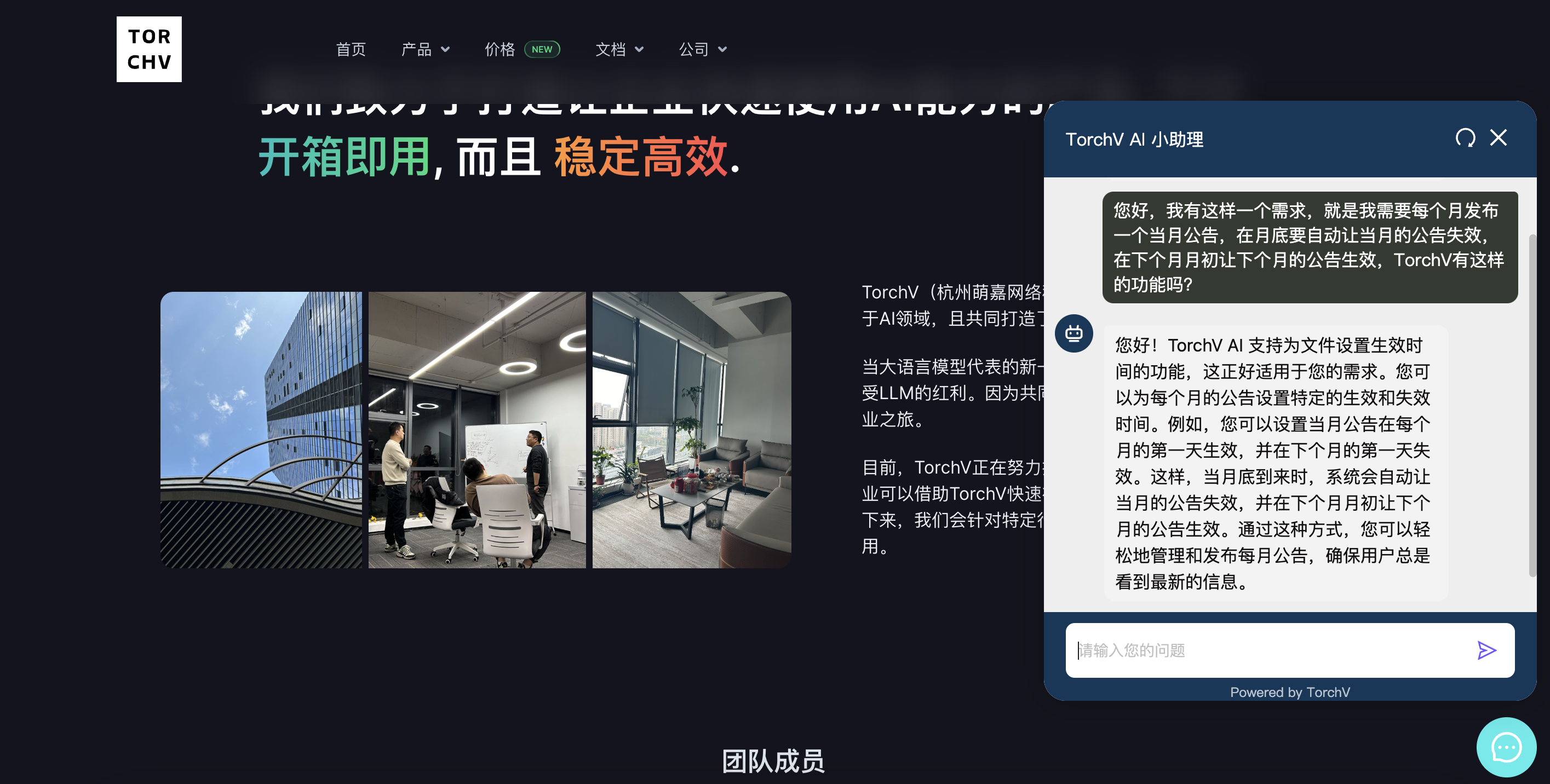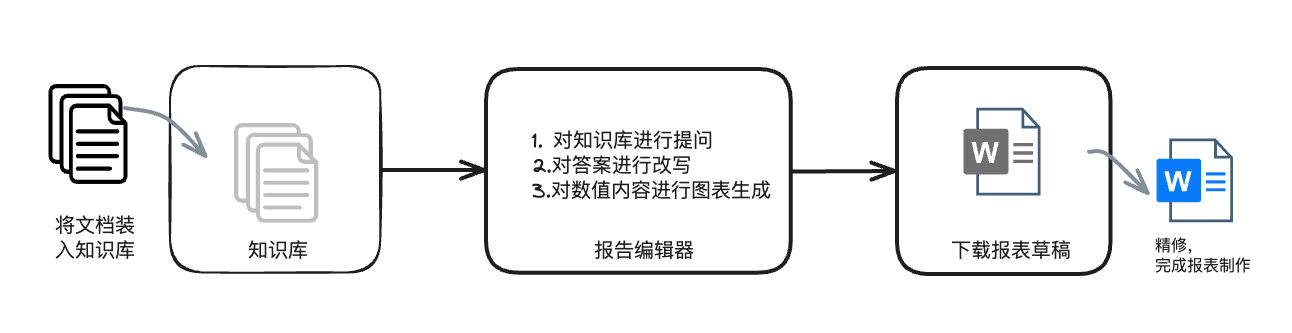
写在前面
在我的产品研发生涯中,出品的产品已经超过十个了,有 toG、toB也有toC,有复杂的,也有非常简单的。回顾这十多个产品,也发现一个有意思的想象,但凡现在依然还被很多客户在使用的,往往都是目的很纯粹的产品,至少从产品初衷来说,都是仅为了解决一个核心问题的。而那些单个产品就带有很多功能的toG系统,现在基本上都已经被扔进垃圾桶了……
所以在我和八一菜刀自己出来创业之后,就“立志”要做简单但强大的产品。
- 简单:也就是上面说的产品的初衷非常单纯,就是去解决一个问题;
- 强大:这可能有多个解释,如对客户非常有效,有很高的使用价值;产品使用体验非常好,上手很快,能被广泛使用;产品性能好,性能稳定,可解释性(可控)强。