本文看点:
数字员工是一种可以提供生产力的软件,其的价值可以用人效衡量,
软件不仅仅只是服务(SaaS),也可以是“软件即人效(SaaP)”。
在上一篇《企业AI落地三部曲1:为什么95%的企业AI项目失败》中,我们提出了一个判断:企业要真正释放 AI 的生产力,最终一定会走向“数字员工军团”。在我看来,数字员工并不是某一种具体形态的产品,而是企业 AI 落地的终极组织形态。原因并不复杂,至少体现在四个方面:
- ROI 可量化:数字员工可以直接用人力资源成本体系来衡量投入与产出;
- 使用门槛极低:它的交互方式天然贴近“同事协作”,就像在钉钉/企业微信或其他IM中和异地团队成员一起工作;
- 具备指数级扩展能力:一旦形成标准化能力,数字员工可以迅速演化为规模化的“数字员工军团”;
- 与具身智能天然兼容:它是未来 AI 从“软件”走向“实体”的关键大脑。
事实上,在ChatGPT 3横空出世不久,B端市场就已经出现了“数字员工”的概念,只是前面一直处于畅想阶段,未见落地。
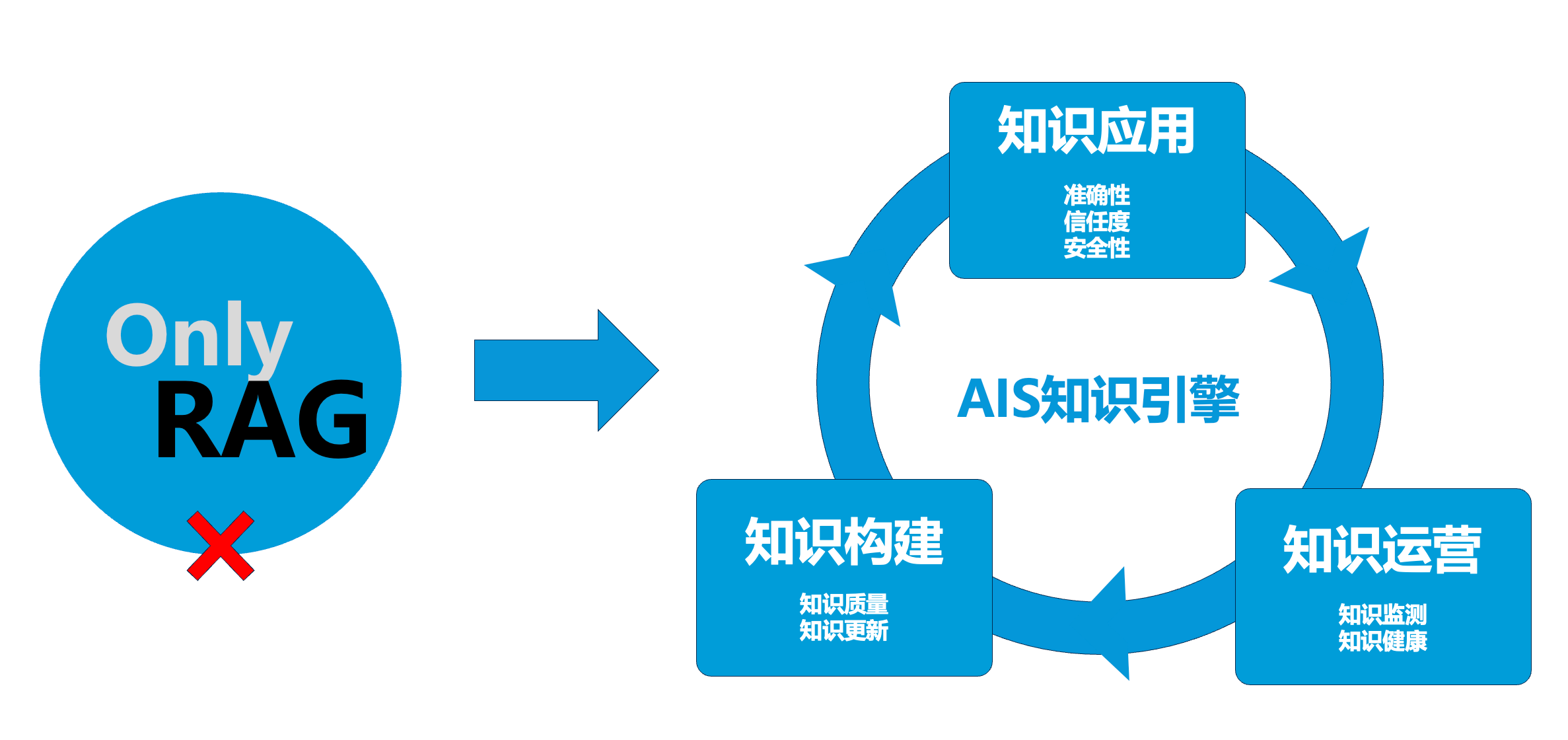
直到2025年3月,因参与某银行项目,我们算是第一次近距离接触到了一家大型金融机构正在系统性开展数字员工工程。当时,TorchV 正在全力聚焦于“成为国内领先的企业级 AI 知识库厂商”,我们自己并没有明确的数字员工视角——原因也很简单:我们没有管理过成千上万人的组织,对“人效”提升的感知并不直观。而极致人效问题,恰恰是大型企业 CXO 们最迫切、也最无法回避的挑战。而对于某银行来说,他们在实施数字员工的过程中发现需要有一个可以支撑知识治理、权限控制和高精度RAG能力的知识库作为数字员工的支撑底座,因为数字员工所需的主动性、长期记忆与组织化协作等特质,恰恰是TorchV KBS(可以认为是某银行专有版的TorchV AIS)这样的知识引擎最本质的能力。