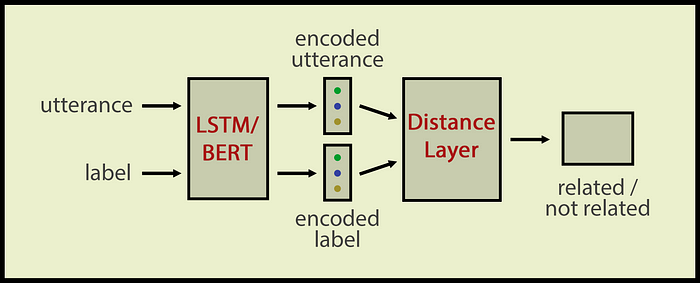
意图识别是面向目标对话系统的一项重要任务。意图识别(有时也称为意图检测)是使用标签对每个用户话语进行分类的任务,该标签来自预定义的标签集。
分类器在标记数据上进行训练,并学习区分哪个话语属于哪个类别。如果一个看起来不像任何训练话语的话语来到分类器,有时结果会很尴尬。这就是为什么我们也会对“域外”话语进行分类,这些话语根本不属于域。
土猛的员外
意图识别是面向目标对话系统的一项重要任务。意图识别(有时也称为意图检测)是使用标签对每个用户话语进行分类的任务,该标签来自预定义的标签集。
分类器在标记数据上进行训练,并学习区分哪个话语属于哪个类别。如果一个看起来不像任何训练话语的话语来到分类器,有时结果会很尴尬。这就是为什么我们也会对“域外”话语进行分类,这些话语根本不属于域。
OpenAI最近发布了他们的新一代embedding模型,称为embeddingv3,他们描述是他们性能最好的embedding模型,具有更高的多语言性能。这些模型分为两类:较小的称为text-embeddings-3-small,较大且功能更强大的称为text-embeddings-3-large。
有关这些模型的设计和训练方式的信息披露得很少。正如他们之前发布的embedding模型(2022年12月与ada-002模型类)一样,OpenAI再次选择了一种闭源方法,其中模型只能通过付费API访问。
但这些性能真的值得花钱去看吗?
这篇文章的动机是将这些新模型与开源模型的性能进行实证比较。我们将依赖于一个数据检索工作流,在这个工作流中,必须根据用户查询找到语料库中最相关的文档。
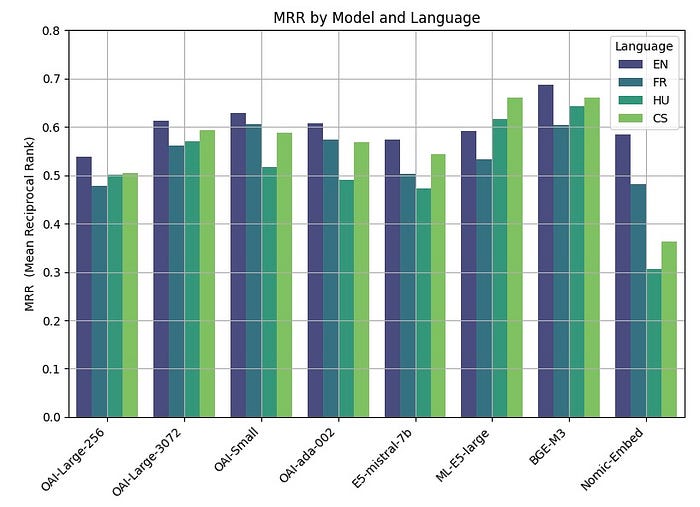
我们的语料库将是欧洲人工智能法案,该法案目前处于验证的最后阶段。这个语料库除了是世界上第一个关于人工智能的法律框架外,还有一个有趣的特点,那就是它有24种语言版本。这使得比较不同语言族的数据检索的准确性成为可能。
这篇文章将通过以下两个主要步骤:
世界正在向数字时代发展,在这个时代,每个人都可以通过点击距离获得几乎所有他们想要的东西。可访问性、舒适性和大量的产品为消费者带来了新的挑战。我们如何帮助他们获得个性化的选择,而不是在浩瀚的选择海洋中搜索?这就是推荐系统的用武之地。
推荐系统可以帮助组织增加交叉销售和长尾产品的销售,并通过分析客户最喜欢什么来改进决策。不仅如此,他们还可以学习过去的客户行为,给定一组产品,根据特定的客户偏好对它们进行排名。使用推荐系统的组织在竞争中领先一步,因为它们提供了增强的客户体验。
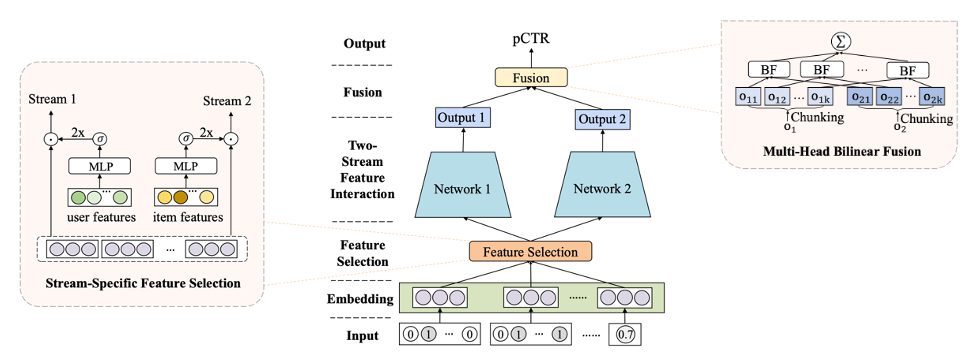
在本文中,我们将重点介绍FinalMLP,这是一个旨在提高在线广告和推荐系统中点击率(CTR)预测的新模型。通过将两个多层感知器(MLP)网络与门控和交互聚合层等高级功能集成在一起,FinalMLP优于传统的单流MLP模型和复杂的双流CTR模型。作者通过基准数据集和现实世界的在线A/B测试测试了它的有效性。
除了提供FinalMLP及其工作原理的详细视图外,我们还提供了实现和将其应用于公共数据集的演练。我们在一个图书推荐设置中测试了它的准确性,并评估了它解释预测的能力,利用作者提出的两流架构。
FinalMLP[1]是建立在DualMLP[2]之上的两流多层感知器(MLP)模型,通过引入两个新概念对其进行增强:
作为人类,我们可以阅读和理解文本(至少其中一些文本)。相反,计算机“用数字思考”,所以它们不能自动掌握单词和句子的意思。如果我们想让计算机理解自然语言,我们需要将这些信息转换成计算机可以处理的格式——数字向量。
许多年前,人们就学会了如何将文本转换为机器可理解的格式(最早的版本之一是ASCII)。这种方法有助于呈现和传输文本,但不编码单词的含义。当时,标准的搜索技术是搜索包含特定单词或N-gram的所有文档时使用的关键字搜索。
然后,几十年后,Embeddings出现了。我们可以计算单词、句子甚至图像的Embeddings。Embeddings也是数字向量,但它们可以捕捉到含义。因此,您可以使用它们进行语义搜索,甚至处理不同语言的文档。
在本文中,我想更深入地探讨Embedding主题并讨论所有细节:
让我们继续了解Embeddings的演变。
Re-ranking在检索增广生成(RAG)过程中起着至关重要的作用。在朴素的RAG方法中,可以检索大量上下文,但并非所有上下文都与问题相关。重新排序允许对文档进行重新排序和过滤,将相关的文档放在最前面,从而提高RAG的有效性。
本文介绍了RAG的重新排序技术,并演示了如何使用两种方法合并重新排序功能
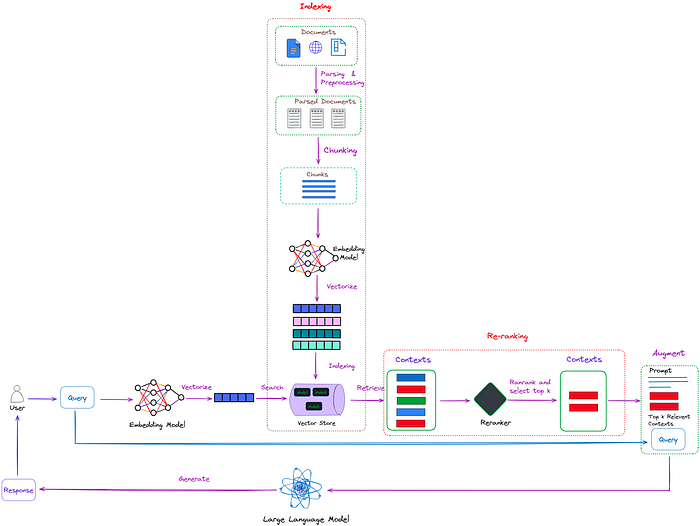
图1:在RAG中重排,重排的任务是评估这些上下文的相关性,并优先考虑最有可能提供准确和相关答案的上下文(红框)。图片来自作者。
如图1所示,重排的任务就像一个智能过滤器。当检索器从索引集合中检索多个上下文时,这些上下文可能与用户的查询具有不同的相关性。有些上下文可能非常相关(在图1中的红色框中突出显示),而其他上下文可能只是稍微相关,甚至不相关(在图1中的绿色和蓝色框中突出显示)。
重排的任务是评估这些上下文的相关性,并优先考虑最有可能提供准确和相关答案的上下文。这允许LLM在生成答案时优先考虑这些排名靠前的上下文,从而提高响应的准确性和质量。
简单来说,重新排名就像在开卷考试中帮助你从一堆学习材料中选择最相关的参考资料,这样你就可以更有效、更准确地回答问题。
本文介绍的重新排序方法主要分为以下两种:
如果您已经为实际的业务系统开发了检索增强生成(Retrieval Augmented Generation, RAG)应用程序,那么您可能会关心它的有效性。换句话说,您想要评估RAG的性能。
此外,如果您发现您现有的RAG不够有效,您可能需要验证先进的RAG改进方法的有效性。换句话说,您需要进行评估,看看这些改进方法是否有效。
在本文中,我们首先介绍了由RAGAs(检索增强生成评估)提出的RAG的评估指标,这是一个用于评估RAG管道的框架。然后,我们解释了如何使用RAGAs + LlamaIndex实现整个评估过程。
简单地说,RAG的过程包括三个主要部分:输入查询、检索上下文和LLM生成的响应。这三个要素构成了RAG过程中最重要的三位一体,并且是相互依存的。
因此,可以通过测量这些三元组之间的相关性来评估RAG的有效性,如图1所示。
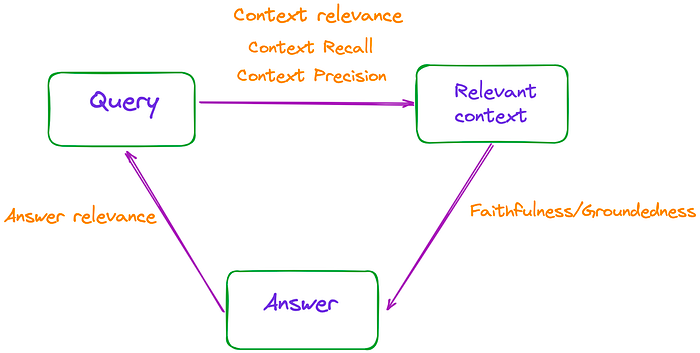
图1:RAG的有效性可以通过测量这些三元组之间的相关性来评估。图片来自作者。
论文总共提到了3个指标:忠实度、答案相关性和上下文相关性,这些指标不需要访问人工注释的数据集或参考答案。
对于RAG,从文档中提取信息是一个不可避免的场景。确保从源头提取内容的有效性对于提高最终输出的质量至关重要
重要的是不要低估这个过程。在实现RAG时,解析过程中的信息提取不佳可能导致对PDF文件中包含的信息的理解和利用受到限制。
pass过程在RAG中的位置如图1所示:
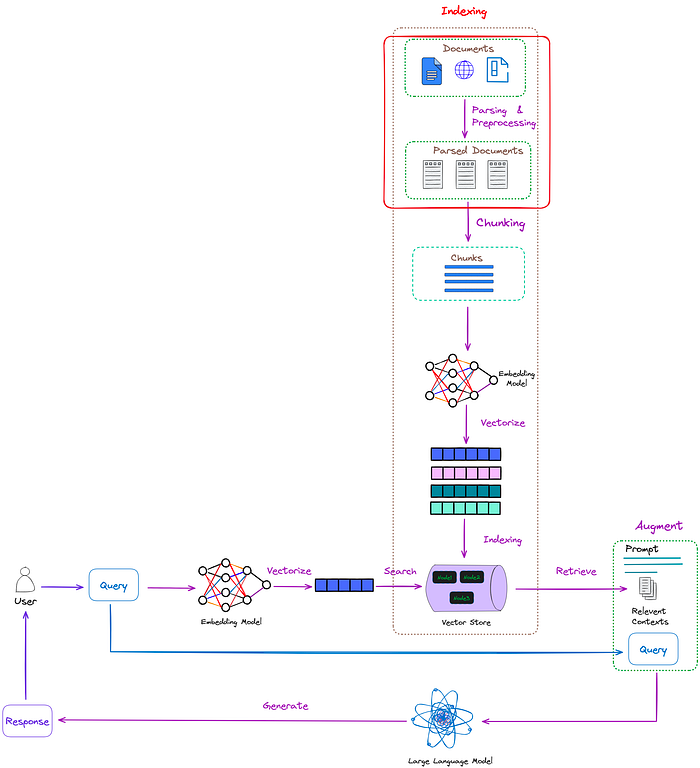
图1:通过过程在RAG中的位置(红框)。图片来自作者。
在实际工作中,非结构化数据要比结构化数据丰富得多。如果这些海量的数据不能被解析,它们的巨大价值就无法实现。
在非结构化数据中,PDF文档占多数。有效地处理PDF文档还可以**极大地帮助管理其他类型的非结构化文档
本文主要介绍解析PDF文件的方法。它提供了有效解析PDF文档和提取尽可能多的有用信息的算法和建议
检索增强生成(RAG)是通过集成来自外部知识来源的附加信息来改进大型语言模型(大语言模型)的过程。这允许大语言模型产生更精确和上下文感知的反应,同时也减轻幻觉。
自2023年以来,RAG已成为基于LLM的系统中最流行的架构。许多产品的功能都严重依赖于RAG。因此,优化RAG的性能,使检索过程更快,结果更准确成为一个至关重要的问题。
本系列文章将重点介绍先进的RAG技术,以提高RAG生成的质量。
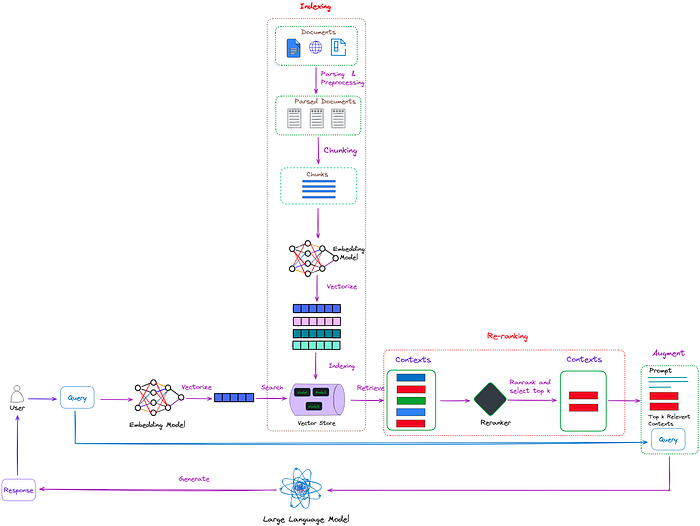
朴素RAG的典型工作流程如图1所示。
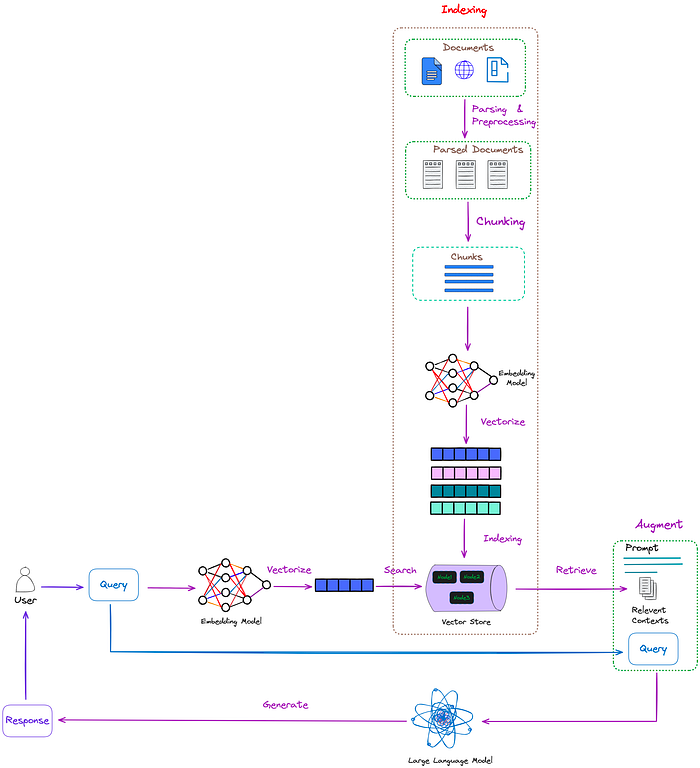
图1:朴素RAG的典型工作流程。图片来自作者。
如图1所示,RAG主要包括以下几个步骤: