对于RAG,从文档中提取信息是一个不可避免的场景。确保从源头提取内容的有效性对于提高最终输出的质量至关重要
重要的是不要低估这个过程。在实现RAG时,解析过程中的信息提取不佳可能导致对PDF文件中包含的信息的理解和利用受到限制。
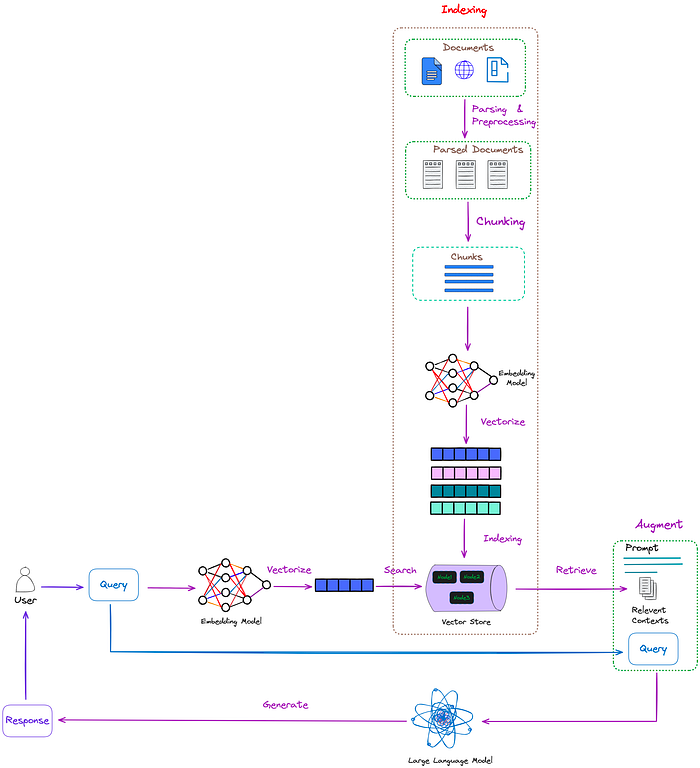
pass过程在RAG中的位置如图1所示:
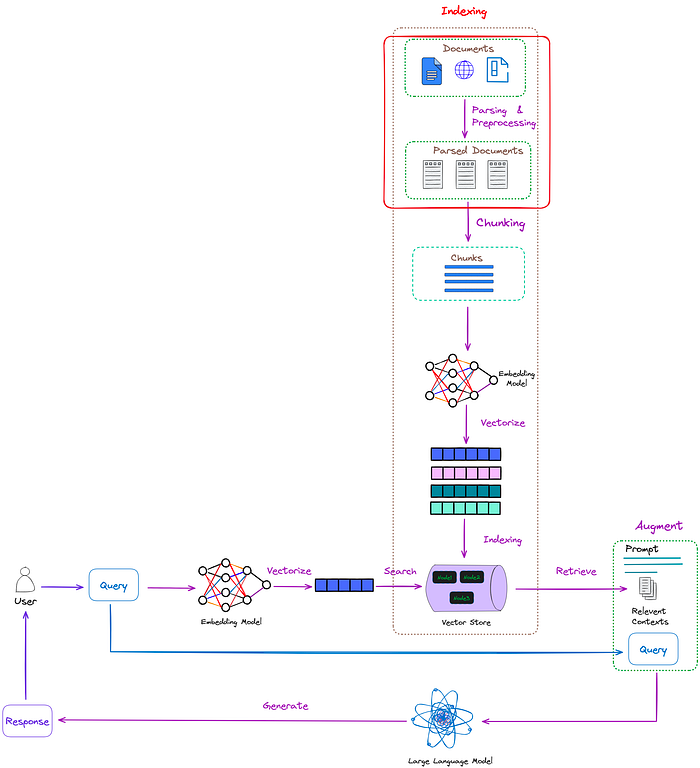
图1:通过过程在RAG中的位置(红框)。图片来自作者。
在实际工作中,非结构化数据要比结构化数据丰富得多。如果这些海量的数据不能被解析,它们的巨大价值就无法实现。
在非结构化数据中,PDF文档占多数。有效地处理PDF文档还可以**极大地帮助管理其他类型的非结构化文档
本文主要介绍解析PDF文件的方法。它提供了有效解析PDF文档和提取尽可能多的有用信息的算法和建议