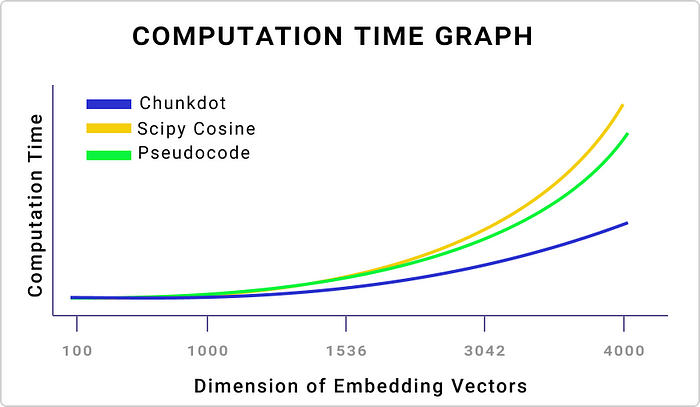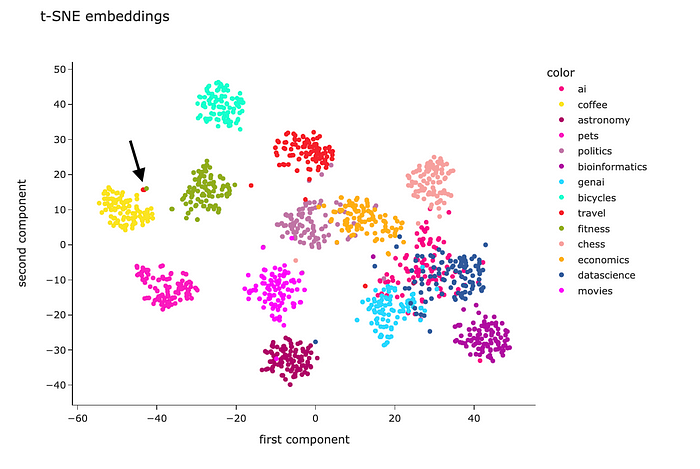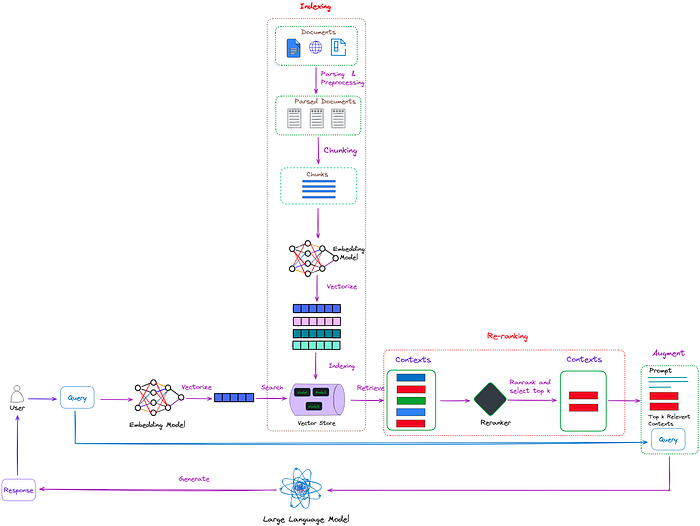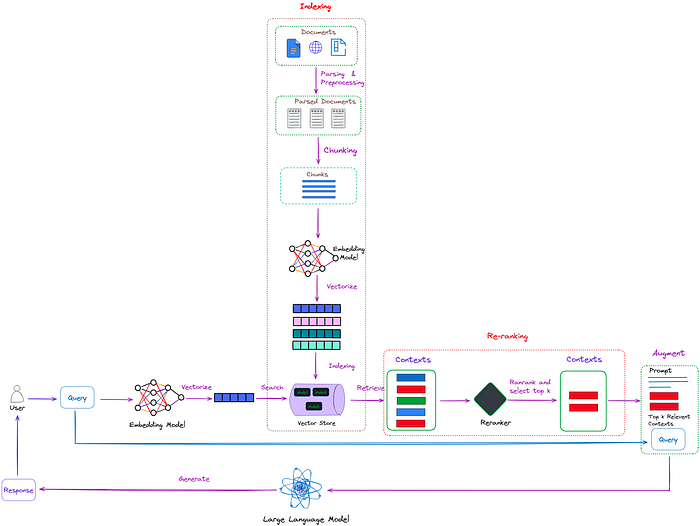
本文非AI技术文章,而是讲述我们在AI应用创业过程中的一些心得。网上常说技术创业者往往缺的不是技术,而是对市场需求的感知,以及如何做到PMF。我们离PMF还有距离,但是已经在路上,所以分享一些自己的AI创业心得,希望得到您共鸣和反馈。
为客户感到开心
昨天最开心的一件事情是我们的一个客户(后面简称“ZY”)的AI应用上线了,ZY使用的是TorchV的AI PaaS服务,而且他们切入的市场需求真的非常棒!鉴于他们做的是专属社群的生意,不太愿意在互联网过多曝光,所以我只说一些大概内容,会略去一些敏感信息。
首先他们的服务对象是在读的重点大学本科生与各类研究生,为学生提供收费的知识服务,对于他们商业模式我就不再过多透露了,但我们内部也评价了一下,确实很有卖点,而且他们具备一些独特优势。
下面我把重点放在讲述ZY与我们TorchV相关的内容上。