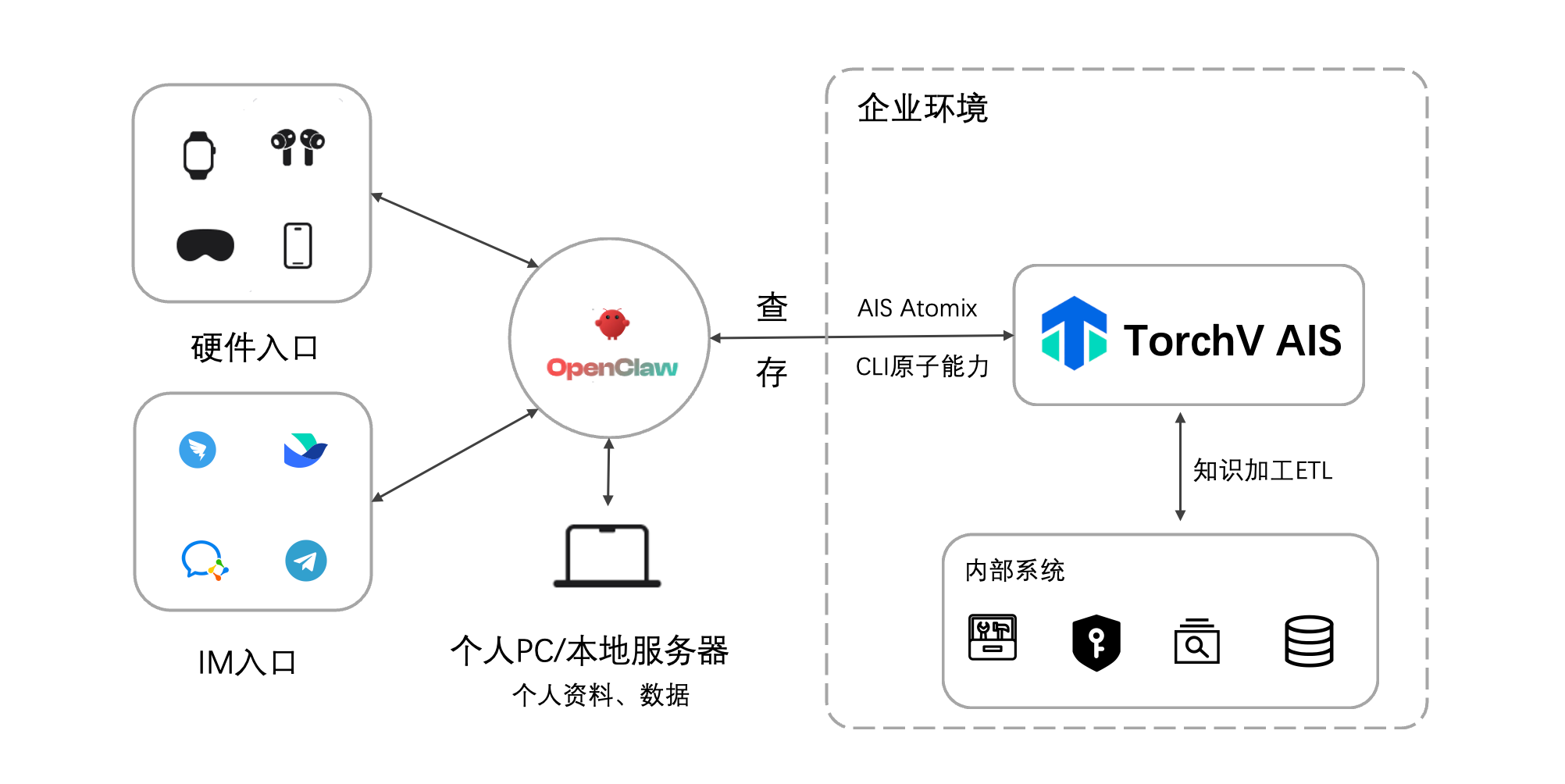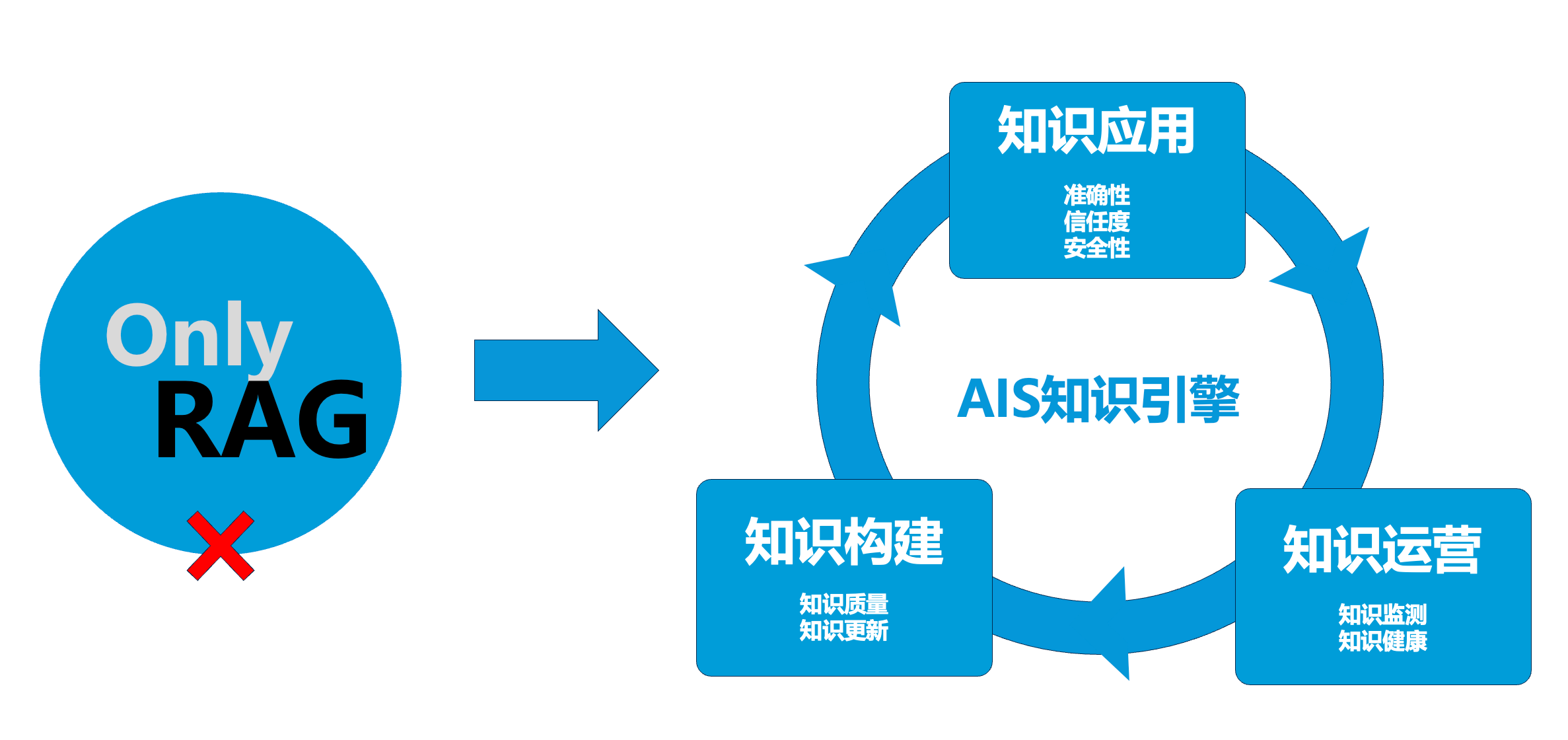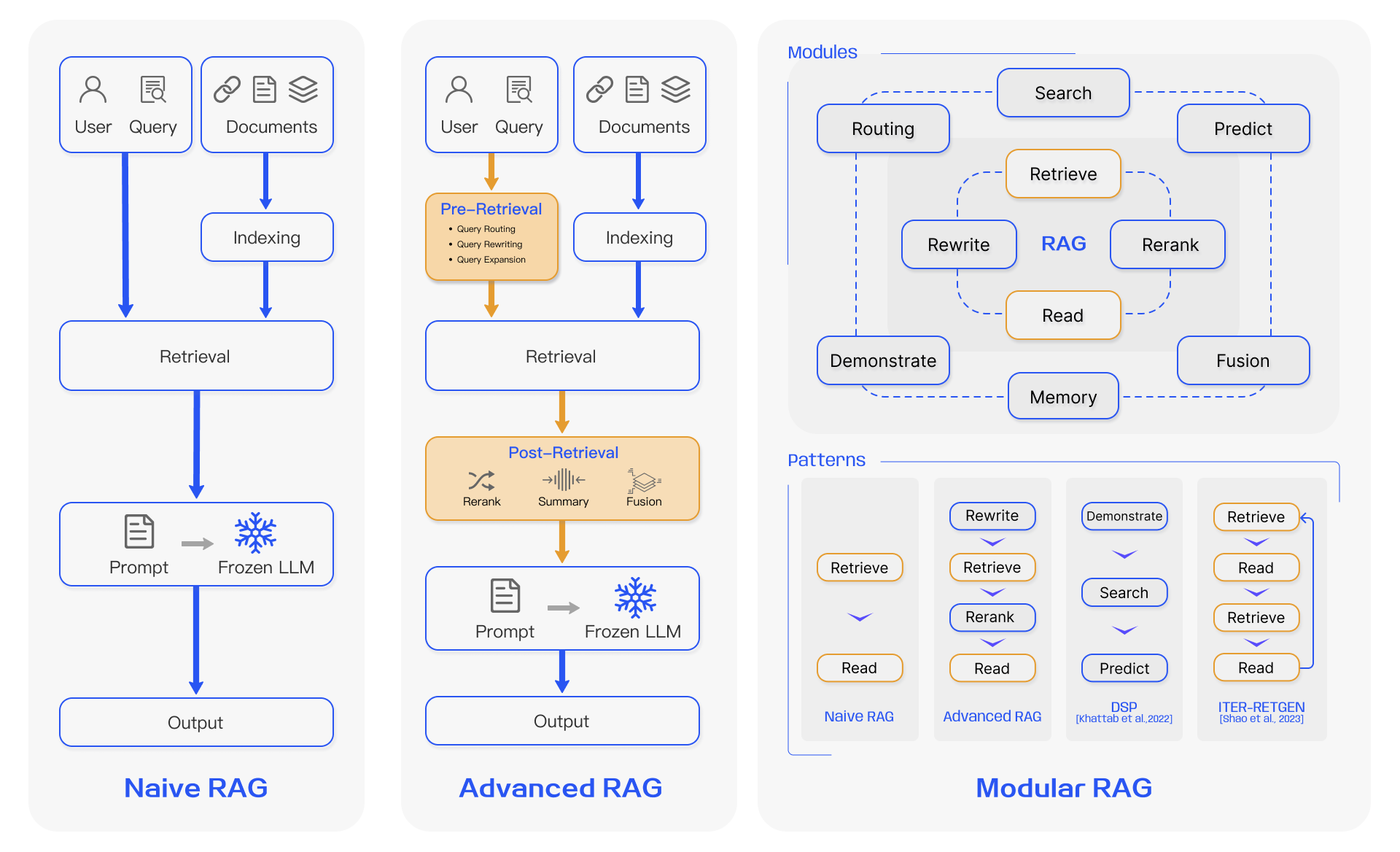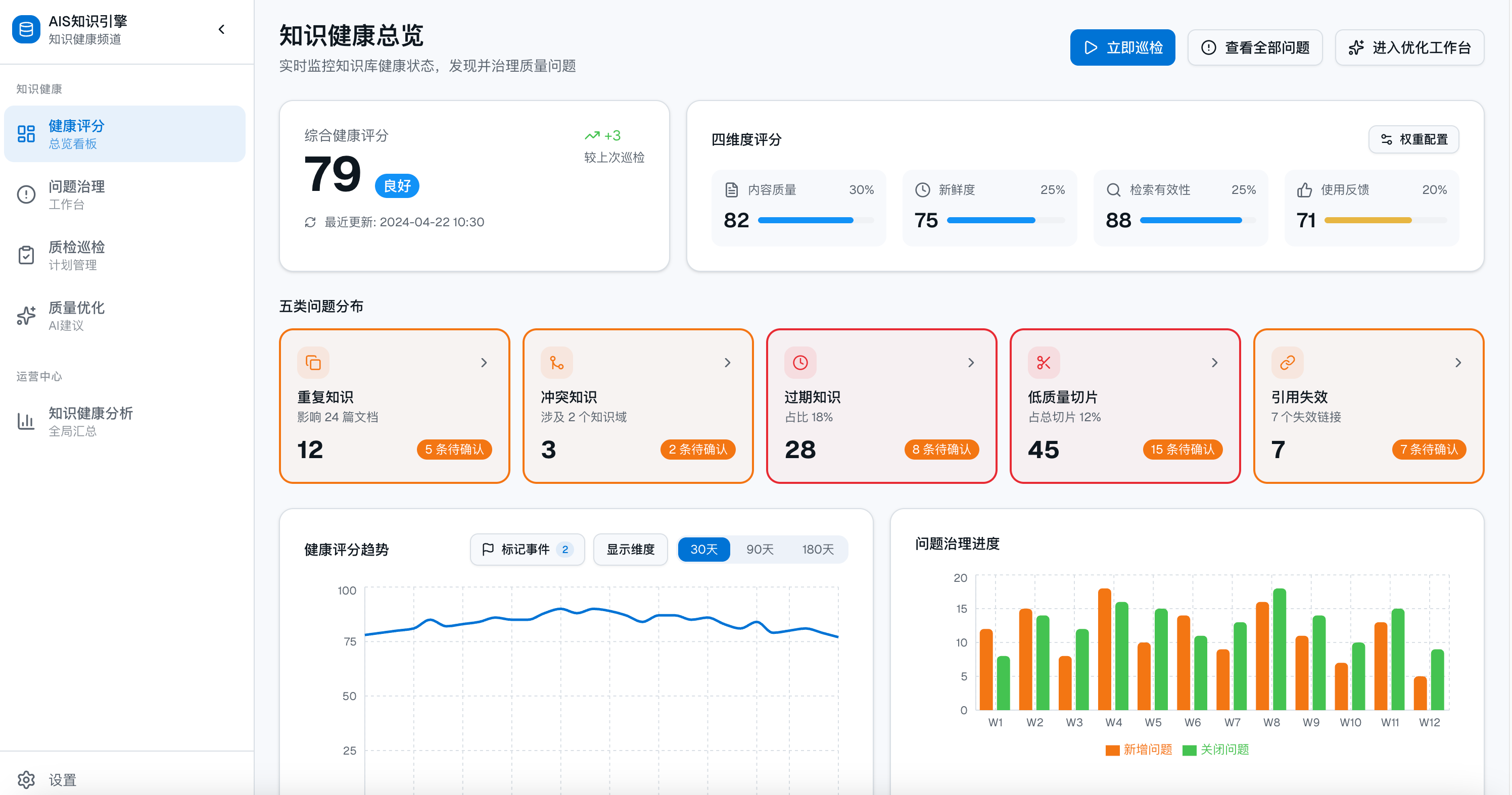
作者:卢向东,杭州萌嘉网络科技有限公司创始人。团队长期专注于企业 AI 落地与 AI 知识引擎实践,是国内较早探索 RAG 企业应用落地的团队之一。产品 TorchV 已成功服务浪潮信息、微众银行、物产中大、台州银行、适途汽车、中汇税务师事务所等客户。
本文导读:
企业应该如何为AI做好准备?
- 大企业在AI落地准备环节的优势;
- 企业是否已经为AI准备好了?7类问题自测;
- 还没想好?那你依然可以先做的两件事。
一、AI落地实践者的回应
五一节假日里读了宝玉最新翻译Daniel Miessler的文章《大多数公司根本没有为AI做好准备》,快速的整理就是以下几点:
- AI 不是问题,说不清目标才是问题;
- 内部的知识和工作流就像混乱黑盒无法规模化;
- 真正被 AI 帮到的公司是怎么样的。
对于文章的大部分观点我都是非常认同的,而且情况确实也和我们近一年半接触的企业(包括成功实施的客户、PoC客户、观望中的企业、咨询之后终止的企业)的画像相似。