目前,使用大型语言模型(LLMs)构建应用程序不仅复杂而且脆弱。典型的pipelines通常使用prompts来实现,这些prompts是通过反复试验手工制作的,因为LLMs对prompts的方式很敏感。因此,当您更改pipelines中的某个部分(例如LLM或数据)时,可能会削弱其性能—除非您调整prompts(或微调步骤)。
当您更改pipeline中的一部分时,例如LLM或数据,您可能会削弱其性能……
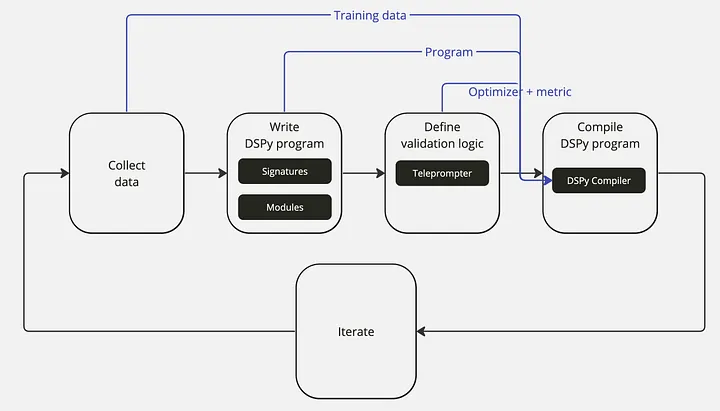
DSPy[1]是一个框架,旨在通过优先编程而不是prompt来解决基于语言模型(LM)的应用程序中的脆弱性问题。它允许您在更改组件时重新编译整个管道,以根据您的特定任务对其进行优化,而不是重复手动轮次的prompt工程。
虽然关于该框架的论文[1]早在2023年10月就已经发表了,但我是最近才知道的。在看了Connor Shorten的一个视频“DSPy解释!” 之后,我已经可以理解为什么开发者社区对DSPy如此兴奋了!
本文简要介绍了DSPy框架,涵盖了以下主题: