很多企业已经开始尝试大模型,但真正进入业务现场时,往往会遇到同样的问题:
制度文件很多,但 AI 不知道该引用哪一版;
业务知识分散在部门、系统和个人电脑里,员工找不到、AI 也用不好;
客服、审计、合规、售后、销售、研发等场景都有大量重复劳动,但又不能完全交给模型自动判断;
客户希望 AI 提效,但更担心答案不准、依据不清、权限越界、过程不可追溯。
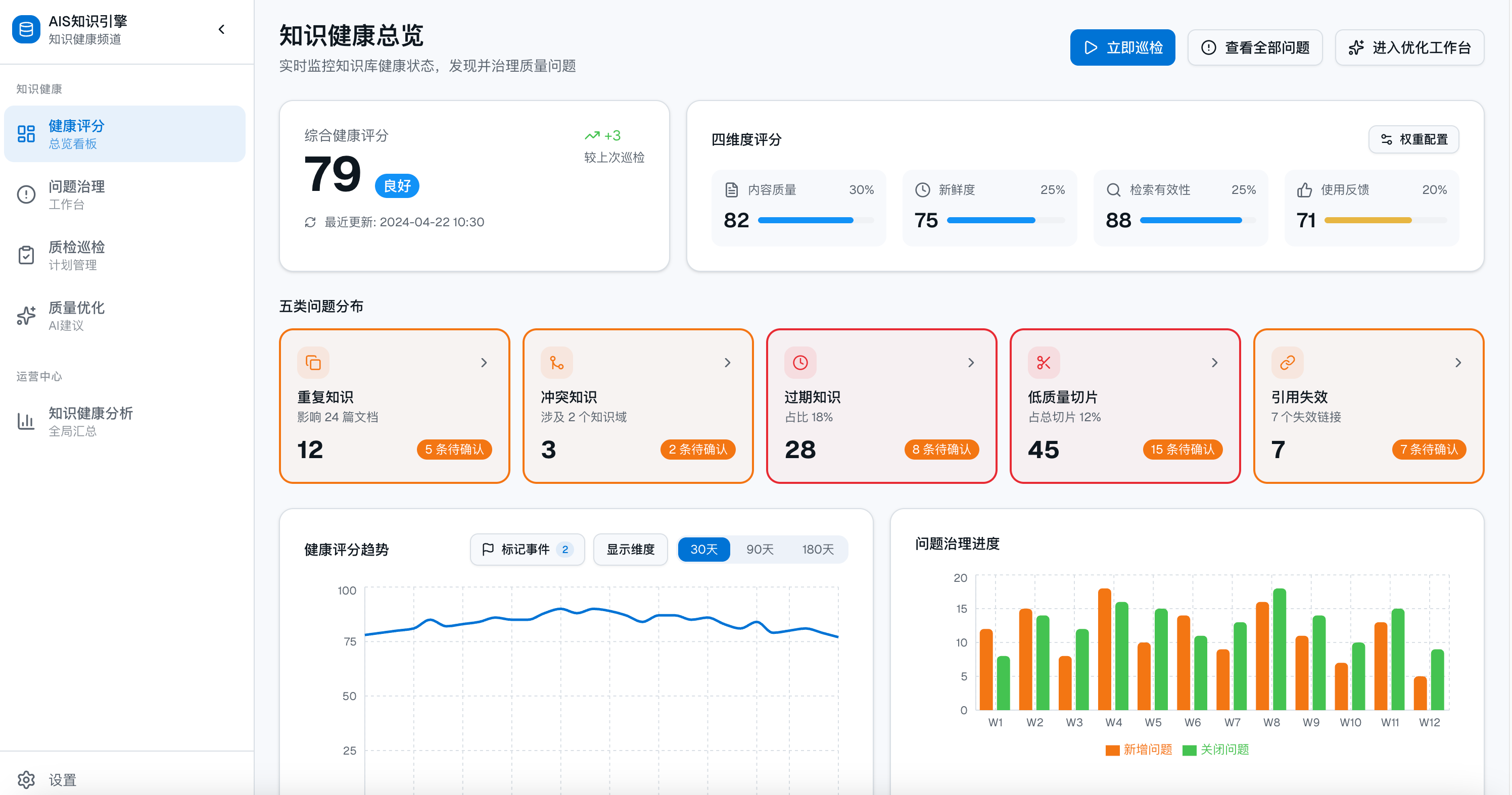
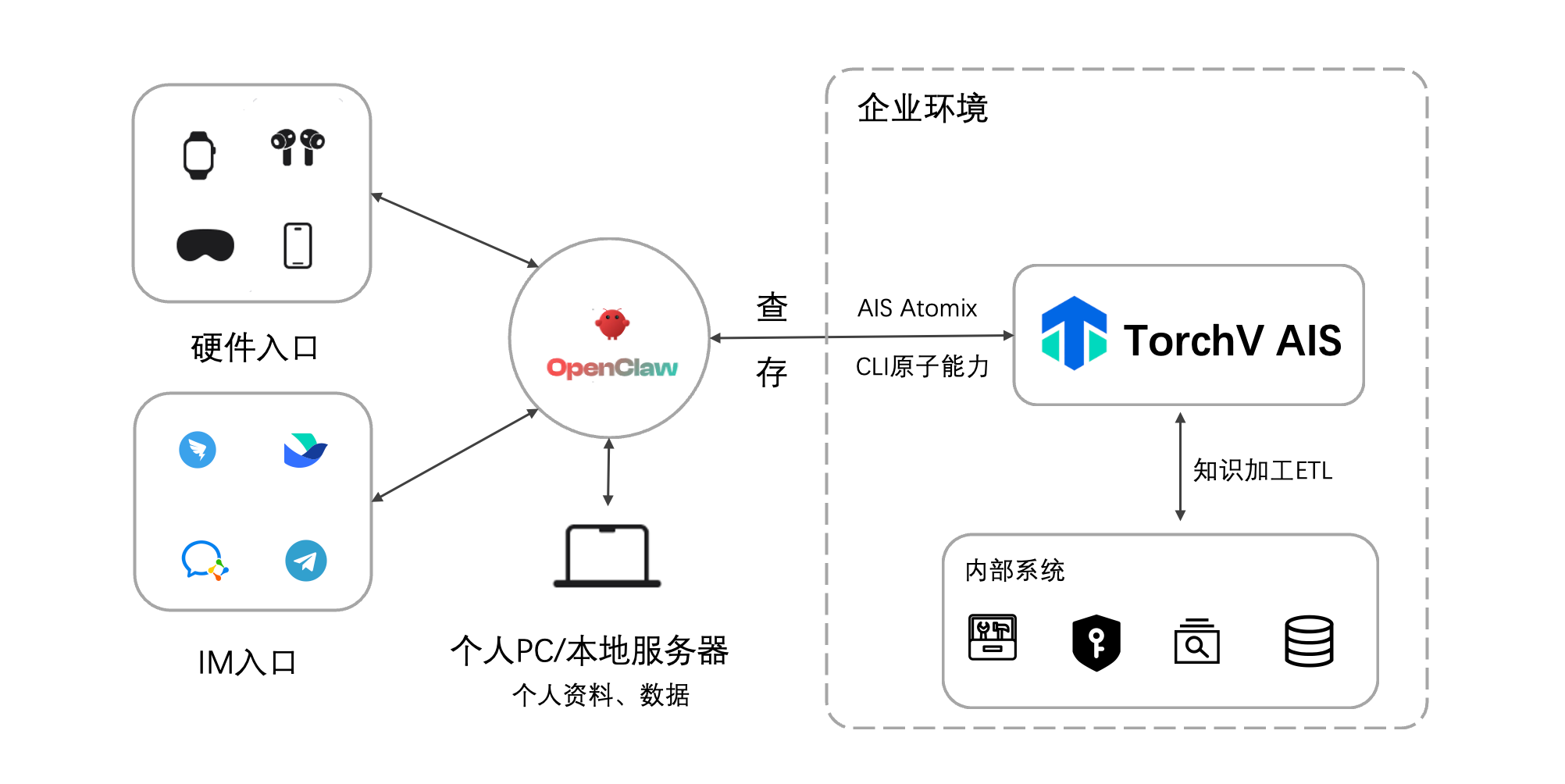
TorchV AIS 面向这些真实问题而设计。它不是一个简单的文档问答工具,而是一套面向企业 AI 落地的知识引擎系统。它帮助企业把分散在制度、手册、合同、报告、工单、案例、模板、FAQ、业务系统和外部资料中的知识,变成可检索、可治理、可追溯、可被智能体调用的知识资产。
本白皮书基于金融、审计、烟草政企、工业制造、大宗商品贸易等真实客户需求抽象而来,重点回答三个问题:
客户可以在哪些业务场景中使用 TorchV AIS?
这些场景能为客户带来什么价值?
TorchV AIS 如何支撑这些业务场景落地?
一、客户价值地图:先从业务场景看 TorchV AIS 能做什么
企业客户最关心的不是“系统有哪些功能”,而是“我的业务里哪里能用,能解决什么问题,能带来什么价值”。因此,我们先用一张价值地图展示 TorchV AIS 在典型业务中的落地方式。