原文:Integrating Neo4j into the LangChain ecosystem
了解如何开发具有多种与Neo4j数据库交互方式的LangChain代理
ChatGPT启发了世界,开启了一场新的人工智能革命。然而,最新的趋势似乎是在为ChatGPT提供一个新技术:提供外部信息,提高其准确性,并使ChatGPT能够回答公共数据集中没有答案的问题。围绕大型语言模型(llm)的另一个趋势是将它们转换为代理,使它们能够通过各种API调用或其他集成与环境进行交互。
由于增强llm相对较新,目前还没有很多开源库。然而,围绕LLMs (如ChatGPT)构建应用程序的首选框架是LangChain。该库通过允许LLM访问各种工具和外部数据源来增强LLM。它不仅可以通过访问外部数据来改进其响应,而且还可以充当代理,并通过外部界面调整其配置。
我偶然发现了一个LangChain项目(作者:Ibis Prevedello),它使用图数据库的搜索,通过提供额外的外部上下文来增强LLMs。
Ibis的项目使用NetworkX图数据库来存储图形信息,将图关系搜索集成到LangChain生态系统中是多么容易。因此,我决定开发一个项目,将Neo4j(一个图数据库)集成到LangChain生态系统中。
Github地址:tomasonjo/langchain2neo4j
该项目现在允许LangChain代理以三种不同的模式与Neo4j交互:
生成Cypher语句查询数据库
相关实体的全文关键字搜索
向量相似性搜索
本文将介绍开发的每种方法的推理和实现。
在这篇博文中,我将向您介绍我开发的每种方法的推理和实现。
环境设置
首先,我们将配置Neo4j环境。我们将使用可用的数据集作为Neo4j沙盒中的推荐项目。最简单的解决方案是通过下面的链接创建一个Neo4j Sandbox实例。但是,如果您更喜欢Neo4j的本地实例,您也可以恢复GitHub上可用的数据库转储。该数据集是MovieLens数据集[1]的一部分,特别是小版本。
在Neo4j数据库实例化之后,我们应该有一个包含以下模式的图。
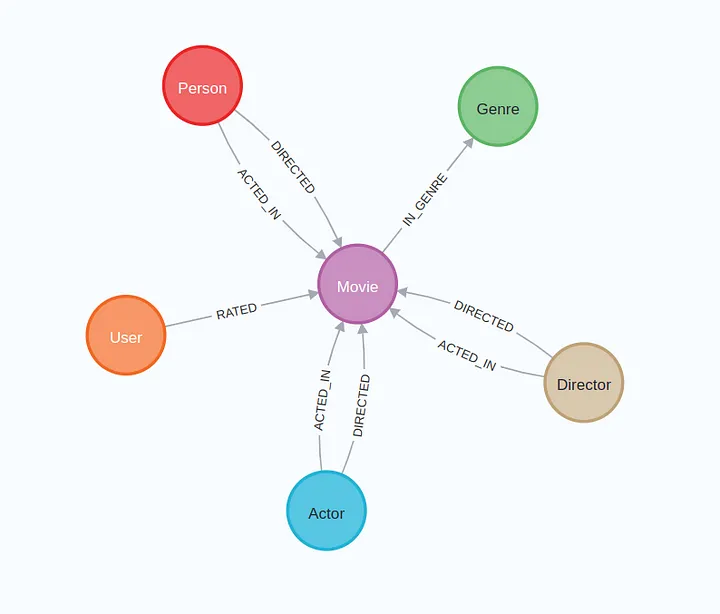
接下来,您需要通过执行以下命令克隆langchain2neo4j存储库:
1 | git clone https://github.com/tomasonjo/langchain2neo4j |
在下一步中,您需要创建一个.env文件并填充neo4j和OpenAI凭证,如.env.example文件中所示。
最后,你需要在Neo4j中创建一个全文索引,并通过运行以下命令导入电影标题嵌入:
1 | sh seed_db.sh |
如果您是Windows用户,那么seed_db脚本可能无法工作。在这种情况下,我准备了一个Jupyter笔记本,它可以帮助您将数据库作为shell脚本的替代方案。
现在,让我们跳到LangChain集成。
LangChain代理
据我所知,使用LangChain代理回答用户问题最常见的数据流如下:
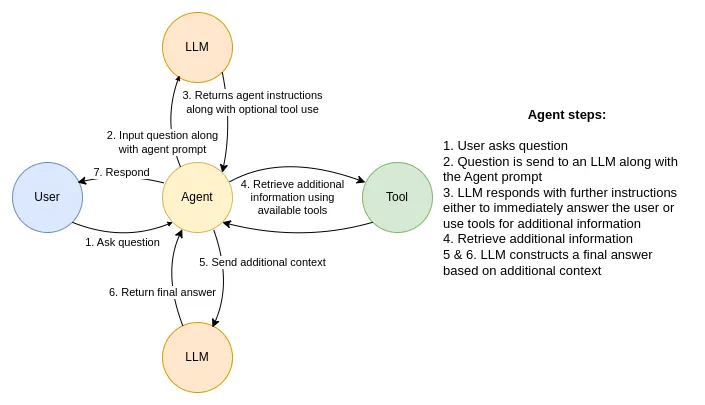
代理数据流在接收到来自用户的输入时启动。然后,代理向大语言模型模型发送请求,该模型包括用户问题和代理提示,这是代理应该遵循的一组自然语言指令。然后,大语言模型以进一步的指令响应代理。大多数情况下,第一反应是使用任何可用的工具从外部来源获得额外的信息。但是,工具并不局限于只读操作。例如,您可以使用它们来更新数据库。在工具返回额外的上下文之后,将对包含新获得的信息的大语言模型进行另一次调用。大语言模型现在可以选择生成返回给用户的最终答案,或者它可以决定需要通过可用的工具执行更多操作。
LangChain代理使用大语言模型进行推理。因此,第一步是定义要使用的模型。目前,langchain2neo4j项目只支持OpenAI的聊天完成模型,特别是GPT-3.5-turbo和GPT-4模型。
1 | if model_name in ['gpt-3.5-turbo', 'gpt-4']: |
除了OpenAI之外,我还没有探索过其他LLMs。然而,LangChain默认集成了十多个其他LLM。
接下来,我们需要用下面一行添加会话记忆:
1 | memory = ConversationBufferMemory( |
LangChain支持多种类型的代理。例如,一些代理可以使用内存组件,而其他代理则不能。由于对象是构建聊天机器人,所以我选择了Conversation Agent(用于聊天模型)代理类型。LangChain库的有趣之处在于一半的代码是用Python编写的,而另一半是prompt工程。我们可以探索会话代理使用的prompt。例如,代理有一些必须遵循的基本指令:
Assistant是OpenAI训练的一个大型语言模型。Assistant被设计成能够协助完成广泛的任务,从回答简单的问题到就广泛的主题提供深入的解释和讨论。作为一种语言模型,Assistant能够根据它收到的输入生成类似人类交流的文本,允许它参与听起来自然的对话,并提供与手头主题相关的连贯响应。助手在不断地学习和改进,它的功能也在不断地发展。它能够处理和理解大量的文本,并能够利用这些知识对广泛的问题提供准确和信息丰富的回答。此外,Assistant能够根据收到的输入生成自己的文本,允许它参与讨论,并就广泛的主题提供解释和描述。总的来说,Assistant是一个功能强大的系统,可以帮助完成广泛的任务,并就广泛的主题提供有价值的见解和信息。无论您是需要特定问题的帮助还是只想就特定主题进行对话,Assistant都可以提供帮助。
此外,代理还具有在需要时使用任何指定工具的prompt。
1 | Assistant can ask the user to use tools to look up information |
有趣的是,提示表明助手可以要求用户使用工具查找其他信息。然而,用户不是人,而是构建在LangChain库之上的应用程序。因此,查找进一步信息的整个过程是自动完成的,没有任何人工参与。当然,如果需要,我们可以更改提示符。提示符还包括llm用于与代理通信的格式。
请注意,代理prompt里面不包括代理不应该回答的问题,如果答案没有在工具返回的上下文中提供。
现在,我们要做的就是定义可用的工具。如前所述,我准备了三种与Neo4j数据库交互的方法。
1 | tools = [ |
工具的描述用于指定工具的功能,并通知代理何时使用它。另外,我们需要指定工具期望的输入格式。例如,Cypher和vector搜索都需要一个完整的问题作为输入,而关键字搜索则需要一个相关电影列表作为输入。
LangChain与我习惯的编码方式有很大的不同。它使用prompt来指示LLM为您完成工作,而不是自己编写代码。例如,关键字搜索指示ChatGPT提取相关电影并将其用作输入。我花了2个小时调试工具输入格式,然后意识到我可以使用自然语言指定它,LLM将处理其余的事情。
还记得我说过的agent没有得到指示不能回答没有上下文提供的信息的问题吗?让我们看看下面的对话。

LLM根据工具描述决定,它不能使用它们中的任何一个来检索相关上下文。但是,LLM默认知道很多信息,并且由于代理没有只能依赖外部资源的约束,因此LLM可以独立地形成答案。如果希望执行不同的行为,则需要更改代理prompt。
生成Cypher语句
我已经开发了一个聊天机器人,通过使用OpenAI的会话模型(如GPT-3.5-turbo和GPT-4)生成Cypher语句,与Neo4j数据库进行交互。因此,我可以借用大部分思想来实现一个工具,该工具允许LangChain代理通过构造Cypher语句从Neo4j数据库检索信息。
像text- davincii -003和GPT-3.5-turbo这样的旧模型作为少量Cypher生成器工作得更好,我们在其中提供了几个Cypher示例,模型可以使用这些示例来生成新的Cypher语句。然而,当我们只呈现图形模式时,GPT-4似乎工作得很好。因此,由于可以使用Cypher查询提取图模式,理论上可以在任何图形模式上使用GPT-4,而无需人工进行任何手工操作。
我们这里不谈LangChain是怎么做的,我们只看一下当LangChain代理决定使用Cypher语句与Neo4j数据库交互时执行的函数。
1 | def _call(self, inputs: Dict[str, str]) -> Dict[str, str]: |
Cypher生成工具将问题与聊天记录一起作为输入。然后通过使用系统消息、聊天历史记录和当前问题将LLM的输入组合起来。我为Cypher生成工具准备了以下系统消息prompt。
1 | SYSTEM_TEMPLATE = """ |
Prompt工程感觉更像是艺术而不是科学。在本例中,我们为大语言模型提供了几个Cypher语句示例,并让它根据这些信息生成Cypher语句。此外,我们设置了一些约束,比如允许它只构造可以从训练示例中推断出来的Cypher语句。此外,我们不会让模型道歉或解释它的想法(然而,gpt -3.5 turbo不会听这些指示)。最后,如果问题缺乏上下文,我们允许模型使用该信息进行响应,而不是强迫它生成Cypher语句。
在大语言模型构造Cypher语句之后,我们简单地使用它来查询Neo4j数据库,并将结果返回给代理。下面是一个示例流程。
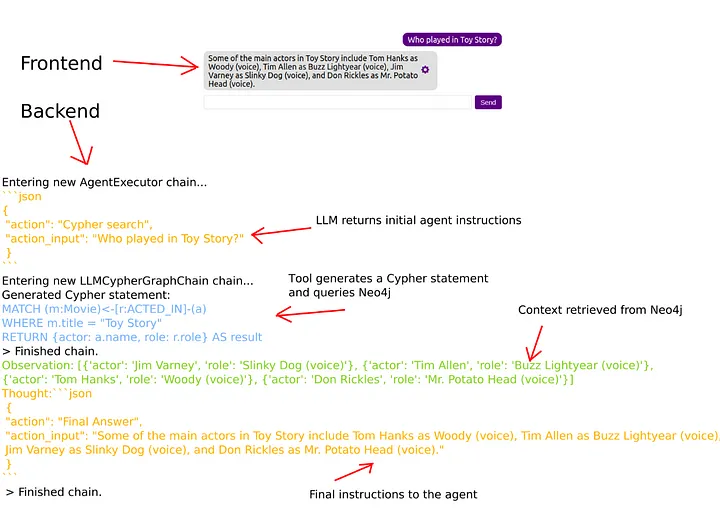
当用户输入他们的问题时,它与代理prompt一起被发送到大语言模型。在本例中,大语言模型响应它需要使用Cypher搜索工具。Cypher搜索工具构造一个Cypher语句并使用它来查询Neo4j。然后将查询结果传回代理。接下来,代理将另一个请求连同新上下文一起发送给大语言模型。由于上下文包含构建答案所需的信息,大语言模型形成最终答案并指示代理将其返回给用户。
当然,我们现在可以问一些后续问题。

由于代理具有内存,它知道谁是第二个参与者,因此可以将信息传递给Cypher搜索工具,以构造适当的Cypher语句。
相关三元组的关键字搜索
我从LangChain和GPT-index库中现有的知识图谱索引实现中获得了关键字搜索的想法。这两种实现非常相似。他们要求大语言模型从问题中提取相关实体,并在图中搜索包含这些实体的任何三元组。所以我想我们可以用Neo4j做类似的事情。然而,虽然我们可以使用简单的MATCH语句搜索实体,但我认为使用Neo4j的全文索引会更好。在使用全文索引找到相关实体后,我们返回三元组,并希望回答问题的相关信息在那里。
1 | def _call(self, inputs: Dict[str, str]) -> Dict[str, Any]: |
记住,代理已经有了解析相关电影标题的指令,并将其作为关键字搜索工具的输入。因此,我们不需要处理这个。然而,由于问题中可能存在多个实体,我们必须构造合适的Lucene查询参数,因为全文索引是基于Lucene的。然后,我们简单地查询全文索引并返回希望相关的三元组。我们使用的Cypher语句如下:
1 | CALL db.index.fulltext.queryNodes("movie", $query) |
因此,我们取全文索引返回的前五个相关实体。接下来,我们通过遍历它们的邻居来生成三元组。我特别排除了被遍历的RATED关系,因为它们包含了不相关的信息。我还没有研究过,但我有一种很好的感觉,我们也可以指示大语言模型提供一个相关关系的列表,并与适当的实体一起进行调查,这将使我们的关键字搜索更集中。关键字搜索可以通过显式指示代理来启动。

大语言模型被指示使用关键字搜索工具。此外,代理被告知提供关键字搜索和相关实体列表作为输入,在这个例子中只有Pokemon。然后使用Lucene参数来查询Neo4j。这种方法撒下了更广泛的网,并希望提取的三元组包含相关信息。例如,检索到的上下文包含关于Pokemon类型的信息,这是不相关的。不过,它也有关于谁在电影中扮演角色的信息,这使得代理可以回答用户的问题。
如前所述,我们可以指示LLM生成相关关系类型列表以及适当的实体,这可以帮助代理检索更多相关信息。
向量相似度搜索
向量相似性搜索是与Neo4j数据库进行交互的最后一种模式,我们将对其进行研究。矢量搜索目前很流行。例如,LangChain提供了与十多个矢量数据库的集成。向量相似度搜索的思想是将问题嵌入到嵌入空间中,并根据问题与文档嵌入的相似度来查找相关文档。我们只需要小心地使用相同的嵌入模型来生成文档和问题的向量表示。我在矢量搜索实现中使用了OpenAI的嵌入。
1 | def _call(self, inputs: Dict[str, str]) -> Dict[str, Any]: |
所以,我们要做的第一件事就是嵌入问题。接下来,我们使用嵌入在数据库中查找相关电影。通常,向量数据库返回相关文档的文本。然而,我们处理的是图形数据库。因此,我决定使用三重结构来产生相关信息。所使用的Cypher语句是:
1 | WITH $embedding AS e |
Cypher语句类似于关键字搜索示例。唯一的区别是我们使用余弦相似度而不是全文索引来识别相关电影。在处理多达数万甚至数十万个文档时,这种方法已经足够好了。记住,瓶颈通常是大语言模型,特别是使用GPT-4时。因此,如果您不处理数以百万计的文档,则不必考虑多语言实现,其中您同时拥有矢量和图形数据库,以便能够通过遍历图形来生成相关信息。

当代理被指示使用向量搜索工具时,第一步是将问题作为向量嵌入。OpenAI的嵌入模型产生维度为1536的向量(译者:我们才387维(⊙o⊙)…)表示。因此,下一步是使用构造好的向量,通过计算问题与相关文档或节点之间的余弦相似度,在数据库中搜索相关信息。同样,由于我们处理的是图形数据库,所以我决定以三元组的形式将信息返回给代理。
关于向量搜索的有趣之处在于,即使我们指示代理搜索《指环王》电影,向量相似性搜索也会返回有关《霍比特人》电影的信息。看起来《指环王》和《霍比特人》电影在嵌入空间里很近,这是可以理解的。
最后
可以访问外部工具和信息的聊天机器人和生成代理似乎是ChatGPT炒作之后的下一波浪潮。有能力提供额外信息和上下文内容,可以让大语言模型大大提高其结果。此外,代理的工具不限于只读操作,这意味着它们可以更新数据库甚至在淘宝帮你下订单(比如你家的洗衣液快没了,对着手机说一声,还是同一个牌子的洗衣液,再来一箱。)。在大多数情况下,LangChain框架似乎是目前用于实现生成代理的主要库。当您开始使用LangChain时,您可能需要在编码过程中进行一些调整,因为您需要将大语言模型提示与代码结合起来完成任务。例如,大语言模型和工具之间的消息可以用自然语言指令作为提示而不是Python代码来塑造和重塑。我希望这个项目能够帮助您在LangChain项目中实现像Neo4j这样的图形数据库的功能。



