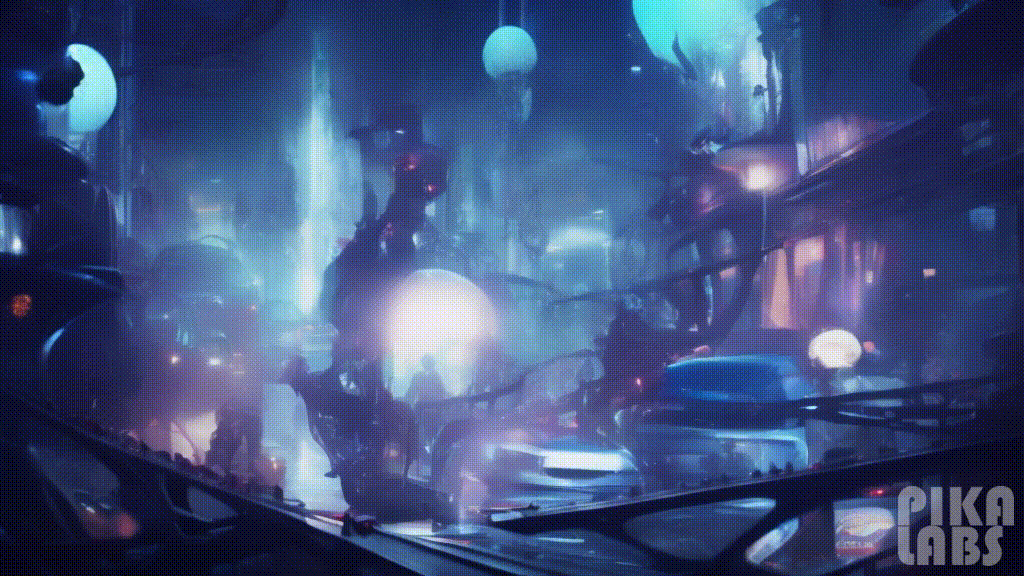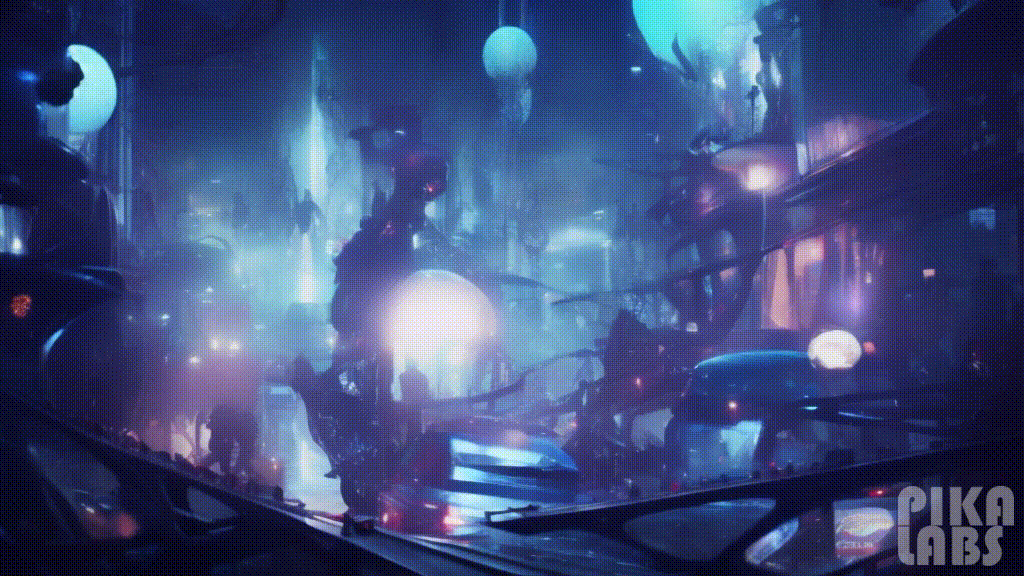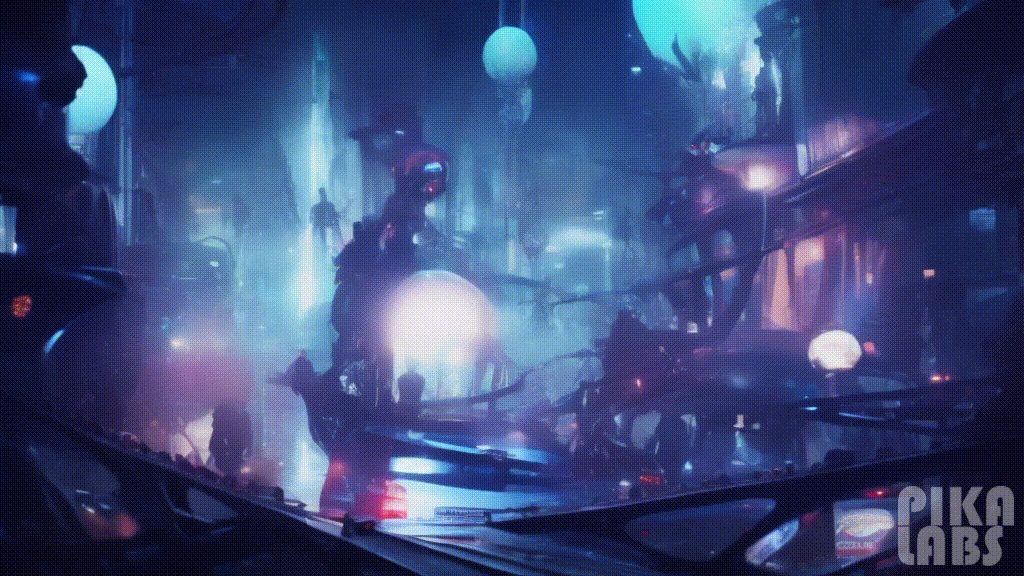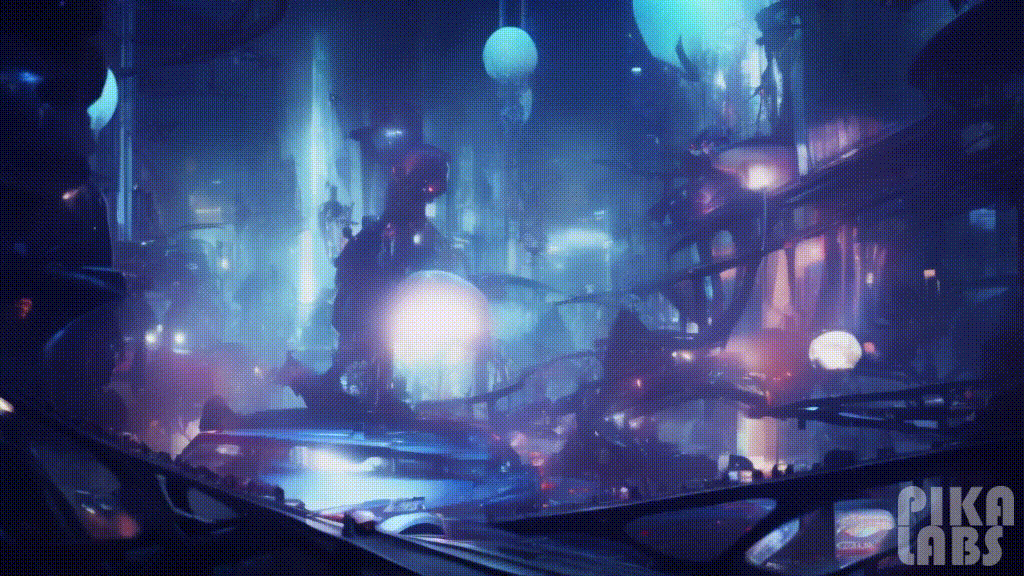原文: 30+ Best Midjourney Prompts For Outstanding Interior Design
技术在进步,跟上室内设计行业的趋势是明智的。在竞争中走在前面,使用让你的工作更轻松的工具是很重要的。
来自世界各地的室内设计师一直在利用Midjourney的能力,快速创建设计,探索无限的可能性,体验没有边界的刺激。
这个工具已被证明是一个宝贵的资源,为专业人士寻求产生高质量的工作。

Midjourney的人工智能艺术生成工具是一个显着的游戏规则改变释放你的创造潜力!
这是一种革命性的方式来挖掘你的想象力和探索创造性的可能性!
如果你是Midjourney的新手,看看这个快速指南开始
今天,我整理了一个伟大的选择32个Midjourney室内设计prompts,它们具有不同的设计风格和独特的功能,以支持您创造令人惊叹的室内设计。
设计风格
1. Art Deco(艺术装饰风格)
艺术装饰风格的室内装饰通常与古老的精致和魅力联系在一起,同时也体现了高质量的工艺和奢侈。
Prompt: Interior design of a living room, art deco style— ar 16:9

2. Bauhaus(包豪斯)
包豪斯的设计力求在理性和逻辑的基础上创造简单、实用而又美观的设计。
Prompt: Interior design of a living room, bauhaus style, dark green — ar 16:9

3. Nordic(北欧风格)
北欧设计的重点通常放在设计功能空间,不加修饰的极简作品,自然的材料,朴素的墙壁和最少的色彩使用。
Prompt: Interior design of a living room, nordic style, blue and white — ar 16:9

4. Loft
Loft(阁楼)风格的室内设计因其独特的工业仓库氛围而越来越受欢迎。它们的特点是天花板高,没有隔板,并结合了工业部件。
Prompt: Interior design of a living room, loft style, two storey apartment— ar 16:9

5. Bohemian(波西米亚)
波西米亚的室内设计是放松的,灵感来自大自然,同时也具有大胆的图案和醒目的色彩。
Prompt: Interior design of a living room, bohemian style — ar 16:9

6. Contemporary(当代设计)
当代设计永远是时尚的——它反映了当前的趋势和运动。
Prompt: Interior design of a living room, contemporary, black and gold — ar 16:9

7. Urban Modern(城市风)
城市风现代设计为更工业化的方法提供了一种平衡,增加了温暖和诱人的元素,软化了外观。
Prompt: Interior design of a penthouse, urban modern style — ar 16:9

8. Tropical(热带风格)
热带风格侧重于营造轻松的氛围,将户外融入您的空间;考虑添加深绿色和火烈鸟粉来实现充满活力和平静的色调。
Prompt: Interior design of a studio apartment, tropical style — ar 16:9

9. Minimalism(极简主义)
极简主义是室内设计风格的一个关键主题。这意味着家具、调色板和其他方面都应该尽可能地保持简单和必要。
Prompt: Interior design of a kitchen, minimal style, beige and wood — ar 16:9

10. Coastal(海景风格)
海景装饰就是在你的家里营造一种海滩的氛围。它结合了天然材料和柔和的色彩,创造了一个休闲但平静的氛围。
Prompt: Interior design of a villa, coastal style, beautiful sunlight — ar 16:9

11. Hollywood Regency(好莱坞摄政风格)
这种设计风格起源于20世纪30年代的好莱坞电影工业中建立的装饰风格。豪华,独树一帜,不同的纺织品,纹理和图案为该地区提供了独特的外观。
Prompt: Interior design of a bathroom, hollywood regency — ar 16:9

12. The French Style(法式)
优雅的法式室内风格为房间带来了独特的平衡,结合了精致的情调与温馨的家,质朴的触摸。
Prompt: Interior design of a bedroom, french style glossy ceramic granite and polished natural stone — ar 16:9

13. Mediterranean(地中海风格)
地中海的设计融合了众多的自然元素,舒适的颜色,和丰富的照明。
Prompt: Interior design of a hotel villa room, mediterranean style, beside the beach, beautiful sunlight shining through — ar 16:9

14. Mid-Century(中世纪风格)
中世纪风格的家具以其简洁的线条、几何形状以及天然和人造材料(如木材和Lucite)的混合为特点。
Prompt: Interior design of a library, mid-century style — ar 16:9

15. Maximalist(极多主义)
极多主义的目标是用色彩、纹理和装饰来利用家里的每一个空间。它的流行可能是因为它是极简主义的对立面。
Prompt: Interior design of a coffee shop, maximalist style, dusk blue and terracotta and cantaloupe color — ar 16:9

16. Shabby Chic(破旧风)
这种破旧别致的趋势以家具为特征,这些家具出于审美目的被有意识地或有机地磨损,并带有古老部件的迷人吸引力。
Prompt: Interior design of a florist shop, shabby chic style, beautiful warm light — ar 16:9

17. Patterns(使用循环模式)
设计师经常使用图案为任何区域增添独特的美感。图案是赋予空间视觉趣味、深度和质感的绝佳方式。
Prompt: Interior design of a bathroom, with Portuguese blue tiles wall, luxurious — ar 16:9

18. Justina Blakeney(布莱尼克风格)
贾斯蒂娜以她的新波西米亚、折衷主义和充满植物的风格而闻名。
Prompt: Interior design of a coffee shop, designed by Justina Blakeney, with nature tone— ar 16:9

19. Kelly Wearstler(凯利·威尔斯特勒)
凯利被称为西海岸室内设计的杰出大师,她在浴室设计方面擅长用大理石地板、四帷柱大床和宽大的露天阳台,体现精致。
Prompt: Interior design of a luxury bathroom, designed by Kelly Wearstler, natural color scheme— ar 16:9

20. Karim Rashid(卡里姆·拉希德)
卡里姆被誉为全美洲最著名的工业设计师和“塑料王子”。
Prompt: Interior design of a cafe, designed by Karim Rashid, concrete and glass facade, outdoor forest, natural light with warm tones, breathtaking — ar 16:9

21. Vincent Van Duysen(文森特·范·杜伊森)
文森特以高端住宅和永恒的设计风格而闻名,擅长使用灌注的混凝土设计各种室内装饰,如桌子、台灯等
Prompt: Interior view of a bold rammed earth and oak mid century modern house, designed by Vincent Van Duysen, sitting on a desert land facing the mountains, moroccan warm light fixtures — ar 16:9

22. India Mahdavi(印度马达维)
印度被称为“色彩大师”和“完美音高的拥有者”的建筑师和设计师
Prompt: The most Instagrammed bar in the world, designed by India Mahdavi, vivid ceramics — ar 16:9

23. UI设计师Leo Natsume
Leo Natsume风格以其独特,生动的插图而脱颖而出,这些插图是喜剧和怪诞的结合。
Prompt: Interior design of a studio, trending color palette, by Leo Natsume, 3D illustration, pop up color, vibrant — ar 16:9

24. Yayoi Kusama(草间弥生)
最著名的现代日本艺术家之一,以她在作品中独特的波尔卡圆点而闻名。
Prompt: Interior design of a bedroom, by Yayoi Kusama — ar 16:9

25. Tim Burton(蒂姆伯顿)
美国导演和动画师,以其黑暗奇幻和恐怖电影而闻名
Prompt: Interior design of a living room, by Tim burton — ar 16:9

我们来看看电影的风格
26. Harry Potter(哈利波特)
Prompt: Interior design of livin room, harry potter theme — ar 16:9

27. Alice in Wonderland(爱丽丝梦游仙境)
Prompt: Interior design of a bathroom, in the style of alice in wonderland, dreamy, breathtaking, beautiful sunlight — ar 16:9

28. Disney & Cartoon(迪士尼动漫)
迪士尼和卡通风格是为你的小公主和王子创造梦想房间的完美选择。
Prompt: Interior design of a room for a baby boy, pastel color, blue and white, Disney, diorama, cartoon, — ar 16:9

也可以用最新的niji5效果,可以让上面的设计发生很有趣的变化.
Prompt: Interior design of a room for a baby boy, pastel color, blue and white, Disney, diorama, cartoon, — ar 16:9 — niji v 5 — style scenic

29. 未来主义2080
让我们游历未来的室内空间设计
Prompt: Interior design of a bedroom, futuristic, in 2080, sci-fi, C4D rendering, smooth lighting, clean, neon light, advanced technology, intelligent housing appliances — ar 16:9

30. Cyberpunk(赛博朋克)
Prompt: Interior design of a music studio room, cyberpunk — ar 16:9

31. Ice Cave(冰洞)
Prompt: Interior design of an ice cave hotel , glowing, translucent, natural lighting, blue and white, hyper detailed, 8k — ar 16:9

32. Intertwining Materials(交织设计)
Prompt: An interior inside of a tree, in the style of realistic yet ethereal, monumental architecture, organic forms, muted tones, 32k uhd, intertwining materials, intricate ceiling designs— ar 16:9