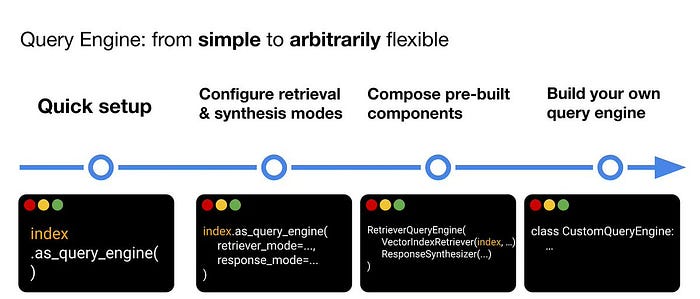
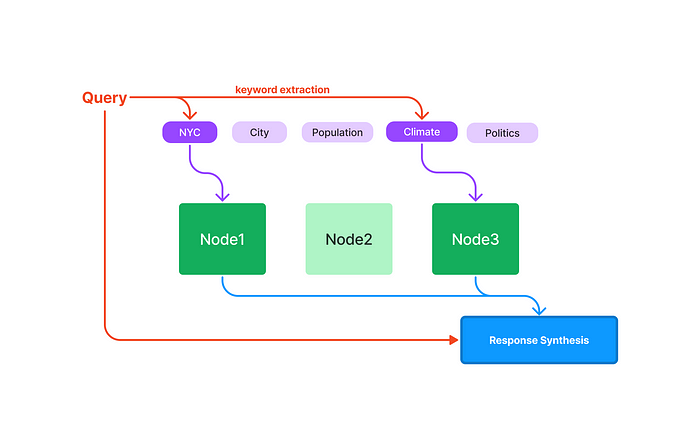
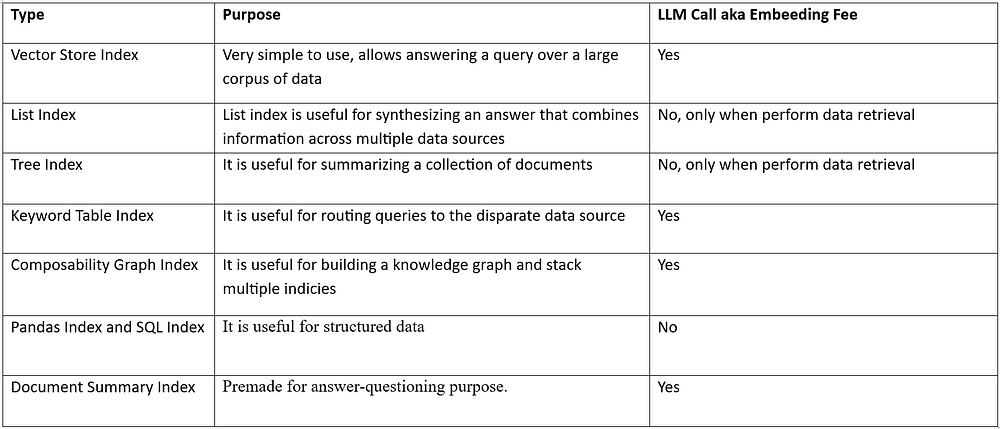
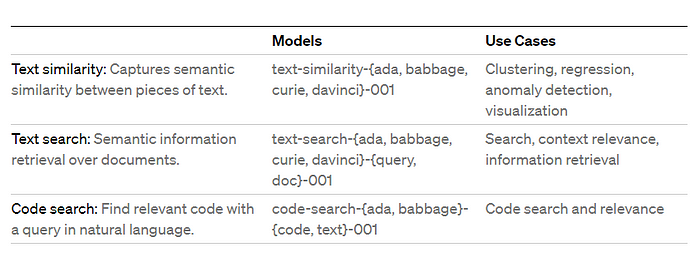
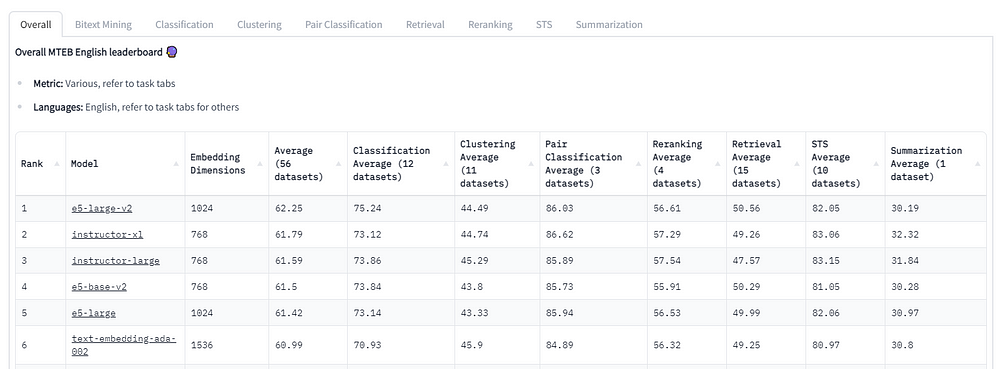
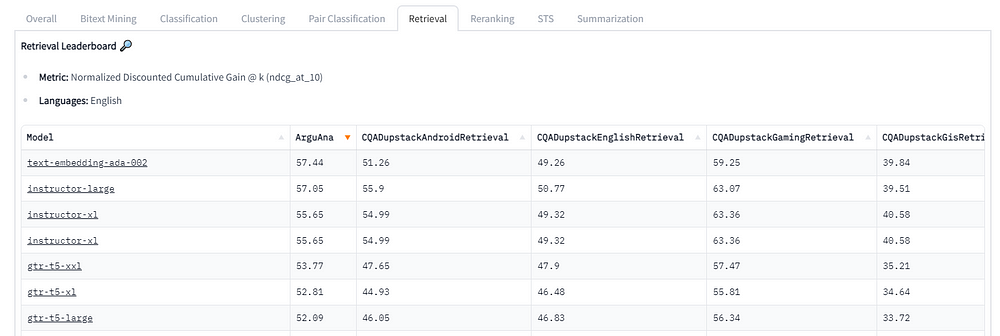
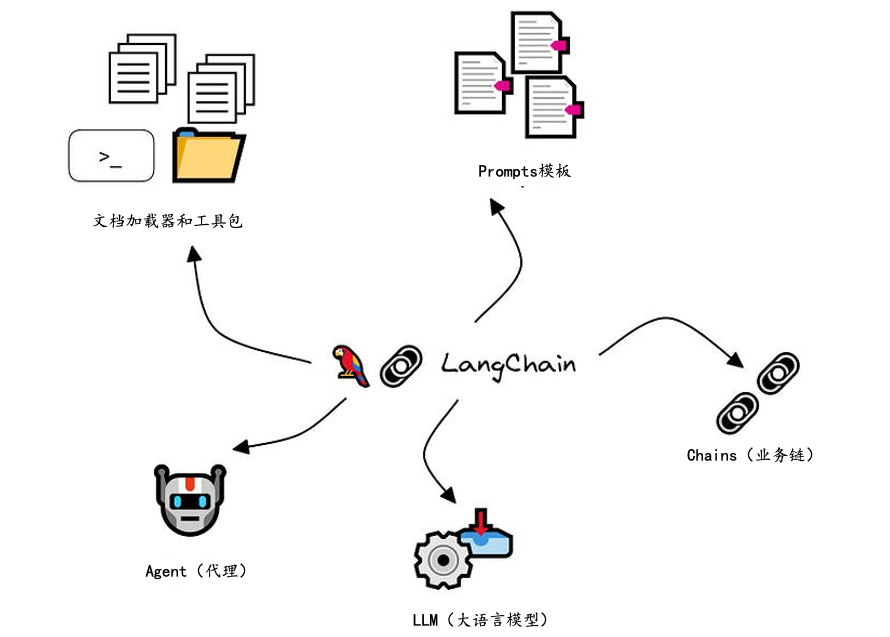
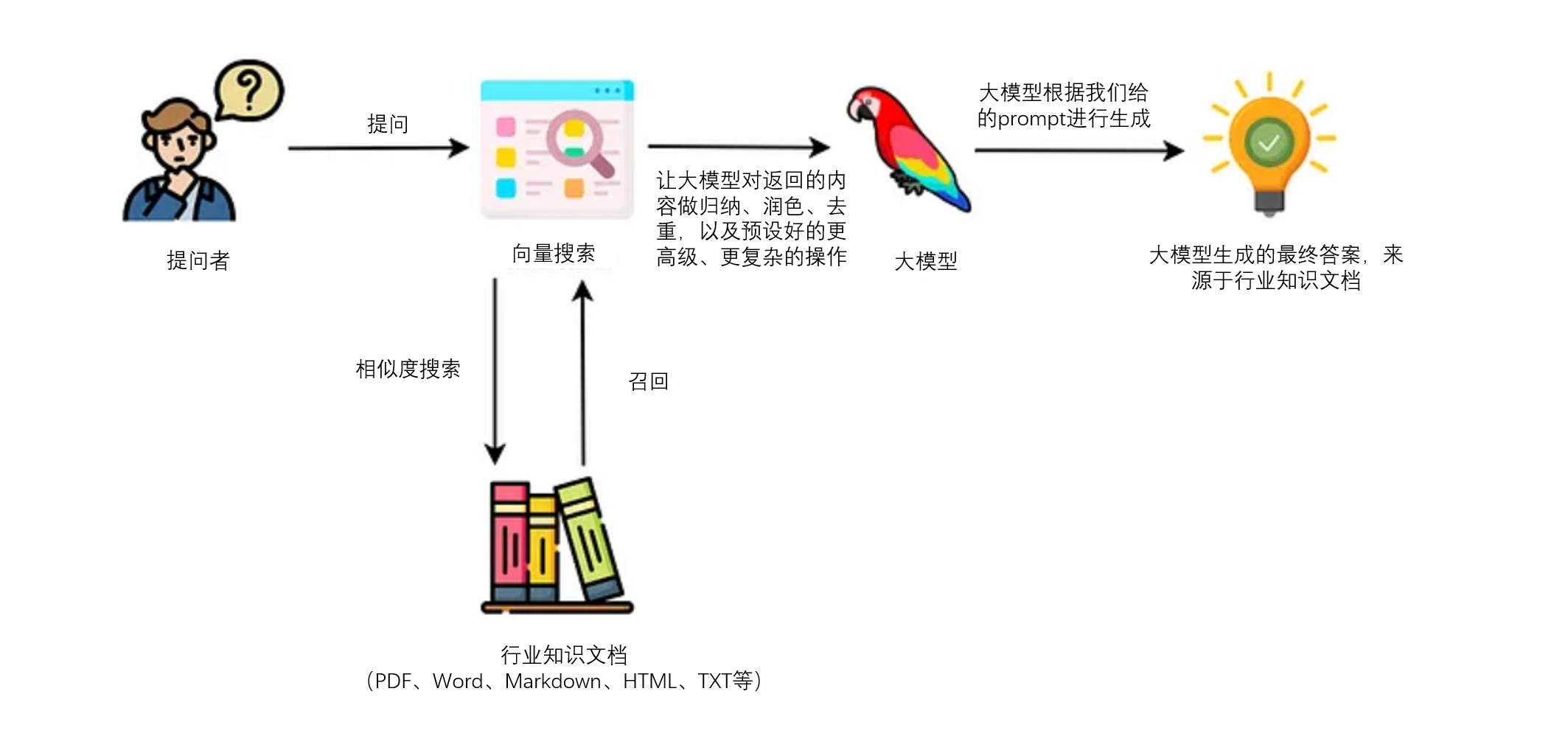
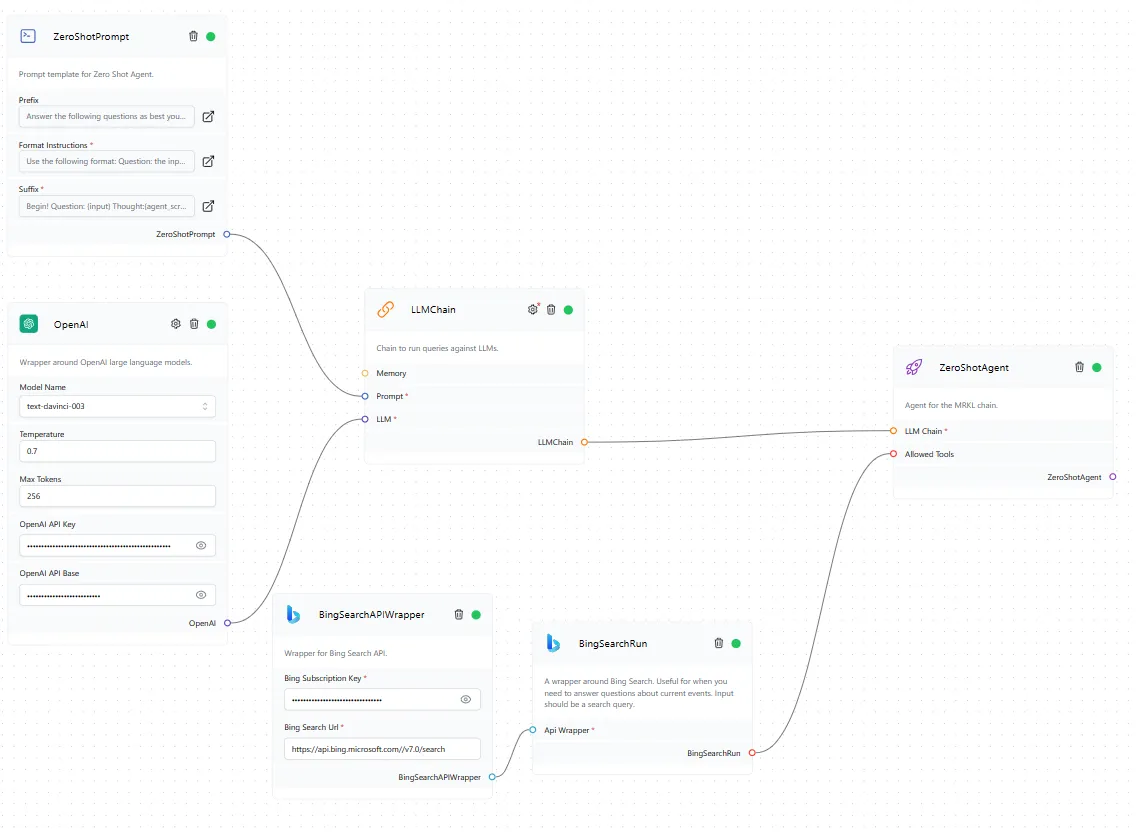
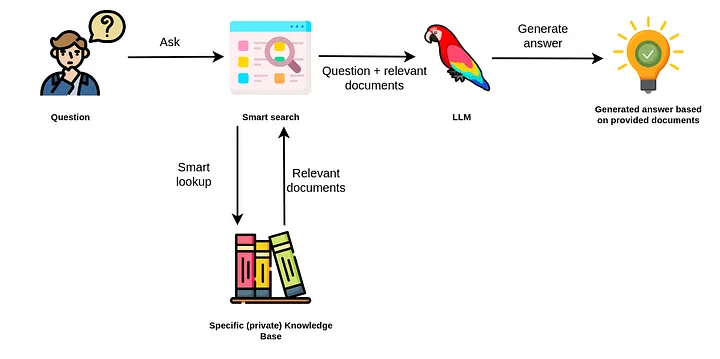
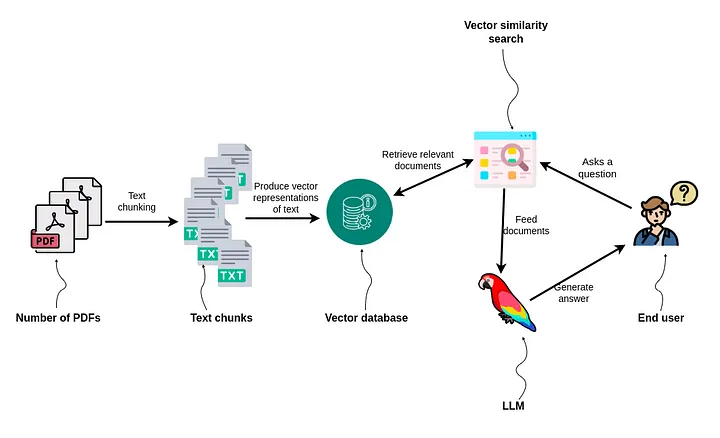
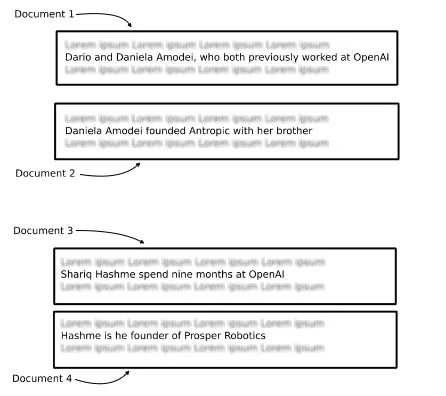
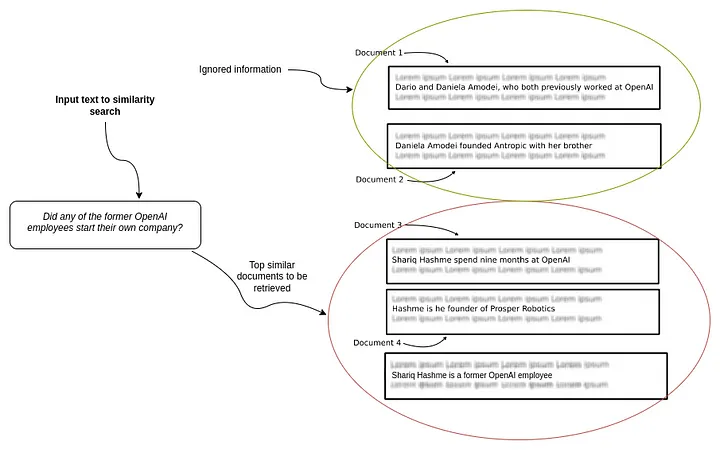
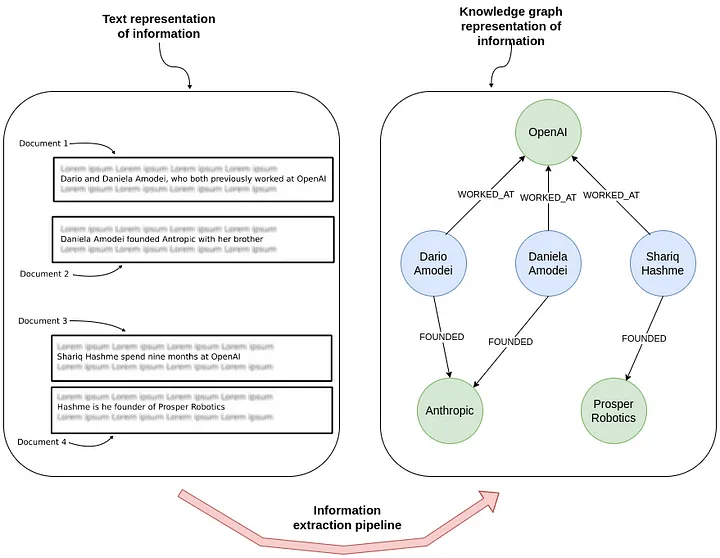
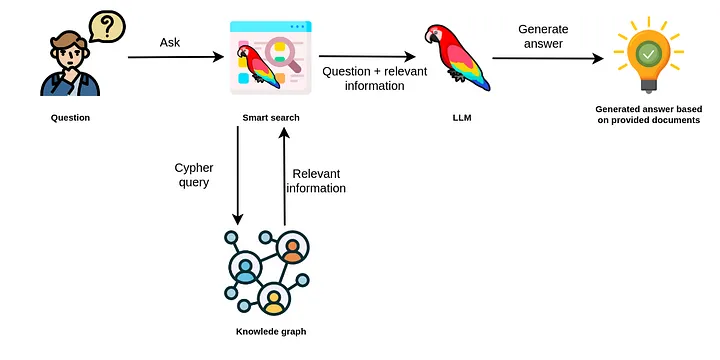
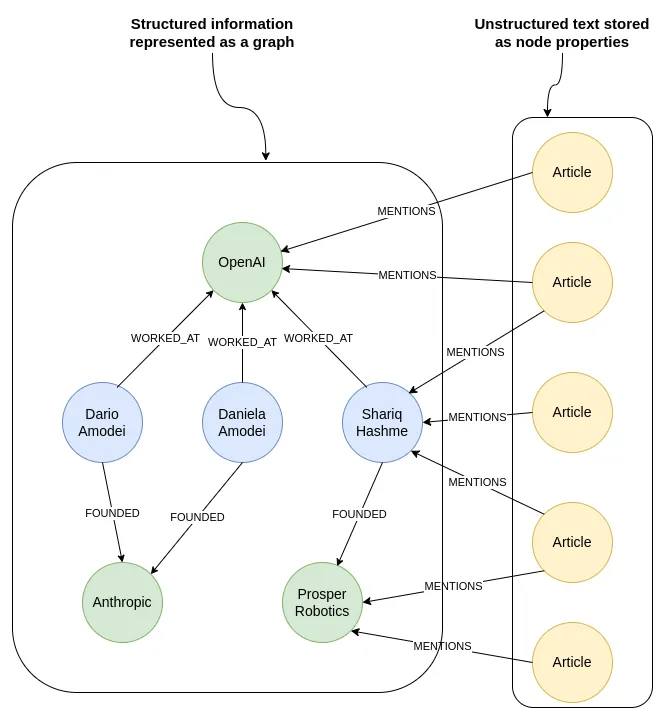
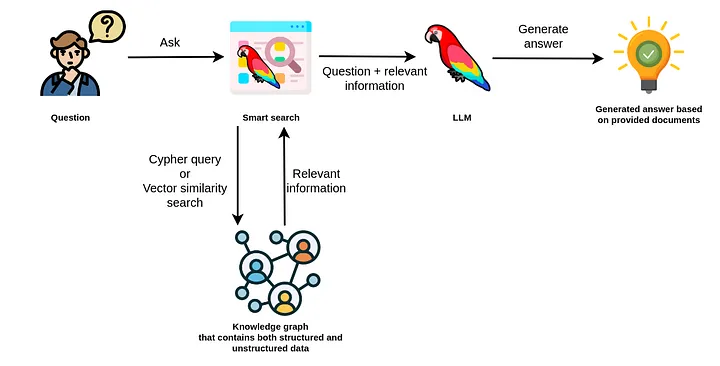
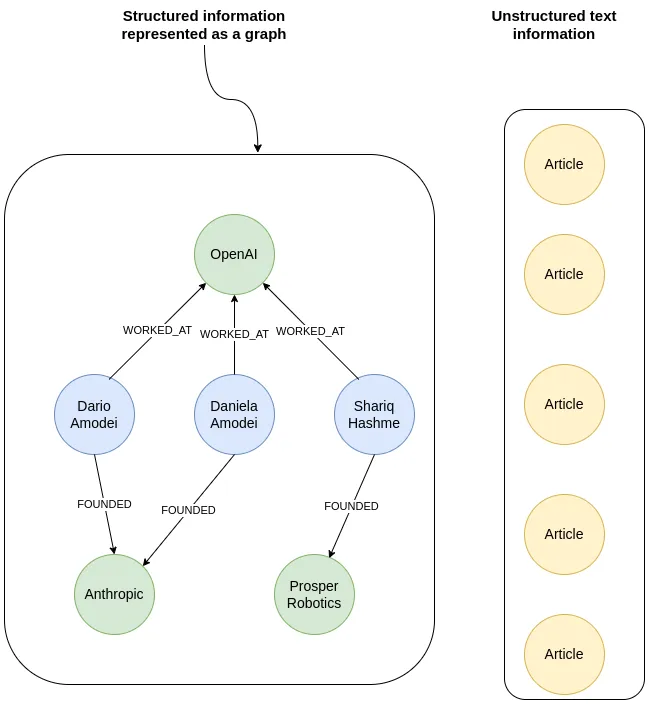
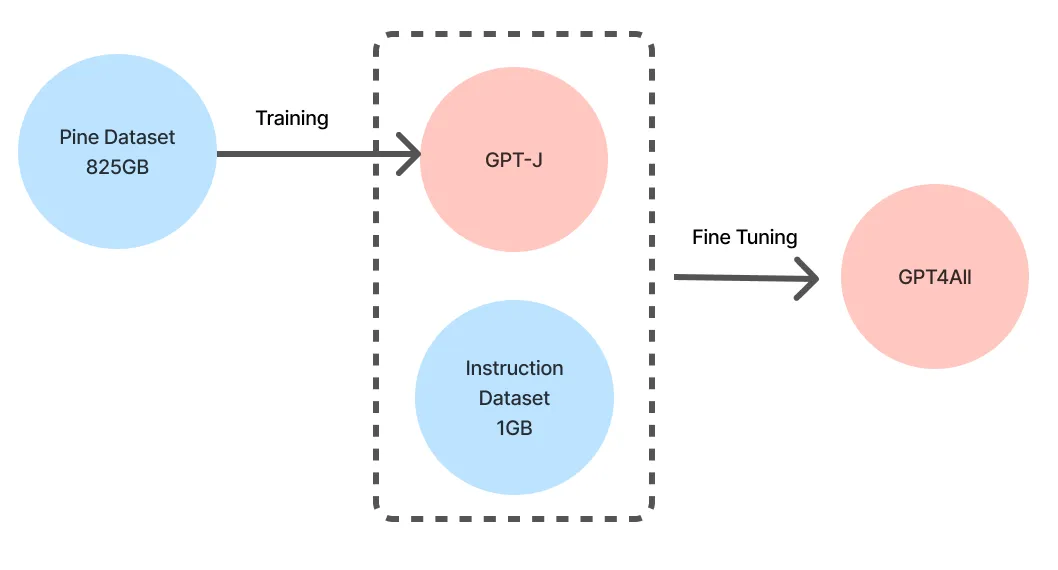
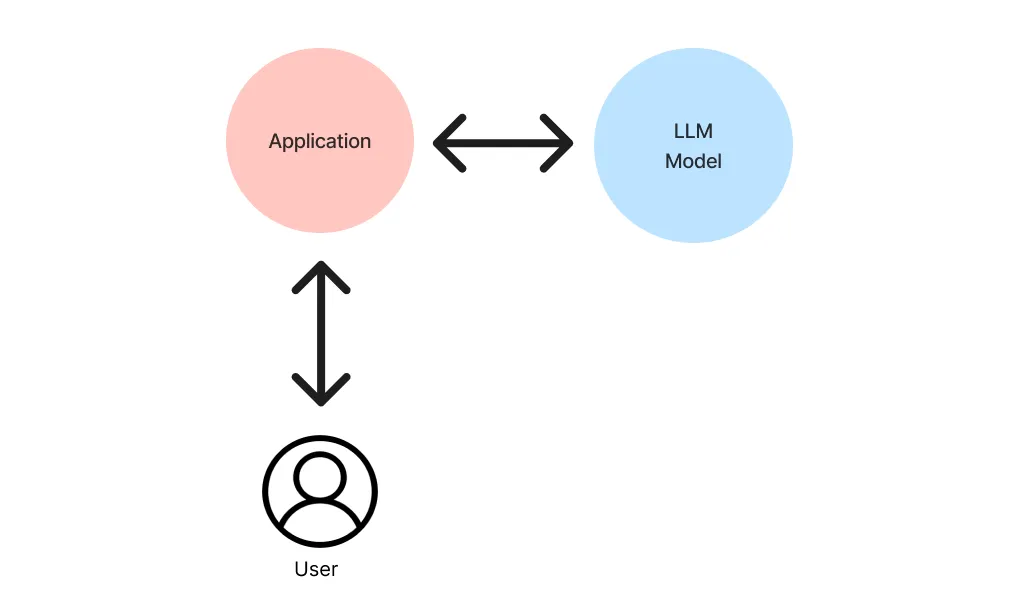
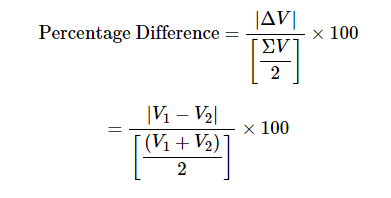LlamaIndex(也称为GPT Index)是一个用户友好的界面,它将您的外部数据连接到大型语言模型(Large Language Models, llm)。它提供了一系列工具来简化流程,包括可以与各种现有数据源和格式(如api、pdf、文档和SQL)集成的数据连接器。此外,LlamaIndex为结构化和非结构化数据提供索引,可以毫不费力地与大语言模型一起使用。
from llama_index import GPTKeywordTableIndex, SimpleDirectoryReader from IPython.display import Markdown, display from langchain.chat_models import ChatOpenAI
## by default, LlamaIndex uses text-davinci-003 to synthesise response # and text-davinci-002 for embedding, we can change to # gpt-3.5-turbo for Chat model index = GPTListIndex.from_documents(documents)
query_engine = index.as_query_engine() response = query_engine.query("What is net operating income?") display(Markdown(f"<b>{response}</b>"))
## Check the logs to see the different between th ## if you wish to not build the index during the index construction # then need to add retriever_mode=embedding to query engine # query with embed_model specified query_engine = new_index.as_query_engine( retriever_mode="embedding", verbose=True ) response = query_engine.query("What is net operating income?") display(Markdown(f"<b>{response}</b>"))
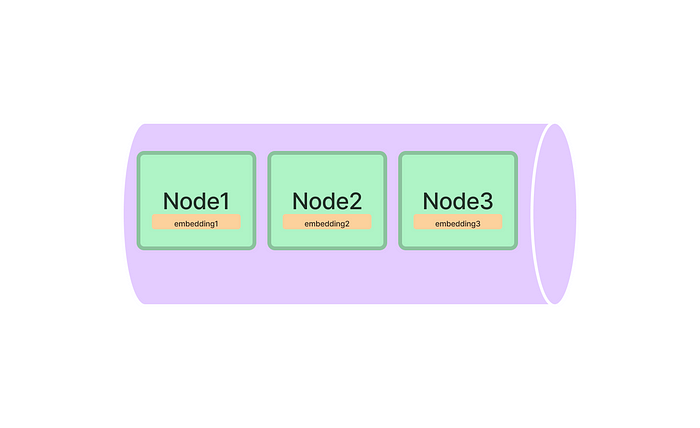
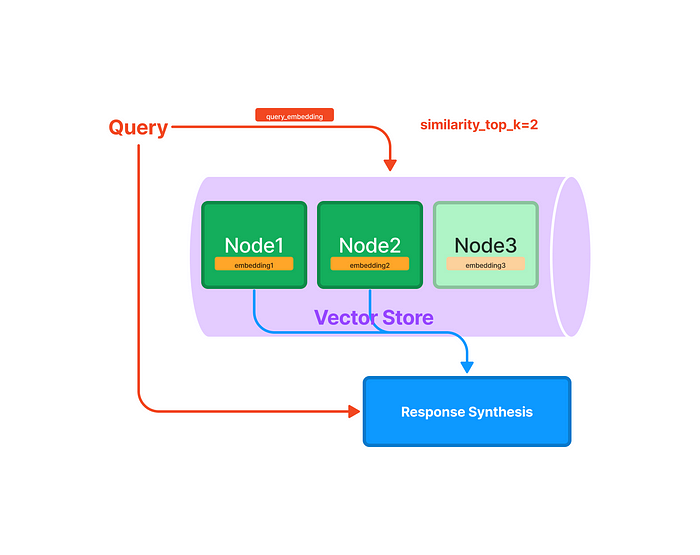
index = GPTVectorStoreIndex.from_documents(documents) query_engine = index.as_query_engine() response = query_engine.query("What did the author do growing up?") response
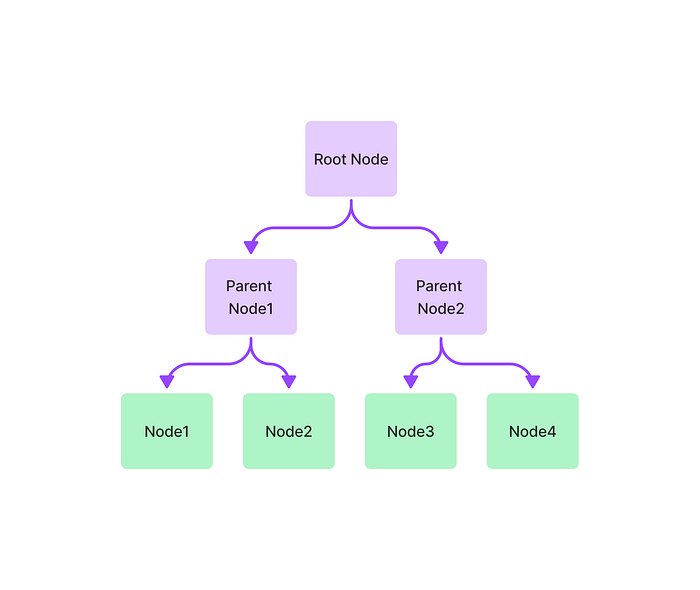
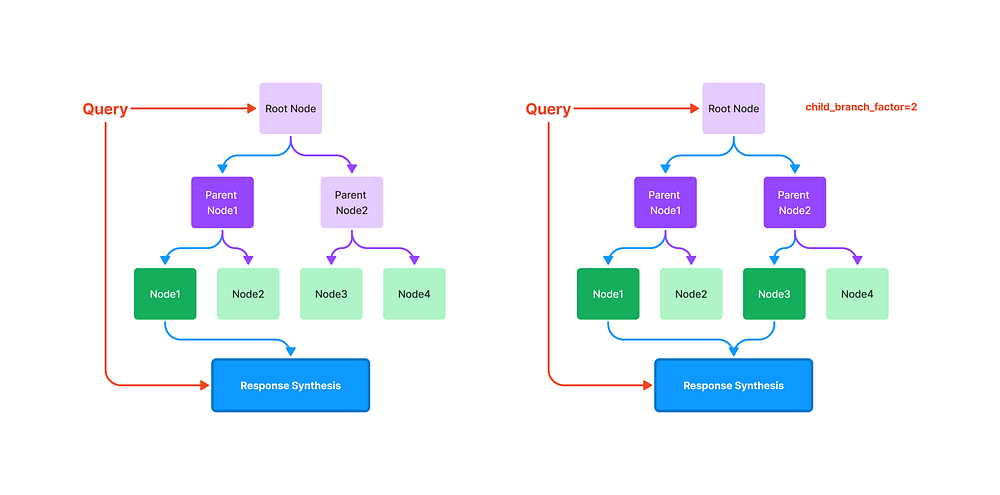
new_index = GPTTreeIndex.from_documents(documents) response = query_engine.query("What is net operating income?") display(Markdown(f"<b>{response}</b>"))
## if you want to have more content from the answer, # you can add the parameters child_branch_factor # let's try using branching factor 2 query_engine = new_index.as_query_engine( child_branch_factor=2 ) response = query_engine.query("What is net operating income?") display(Markdown(f"<b>{response}</b>"))
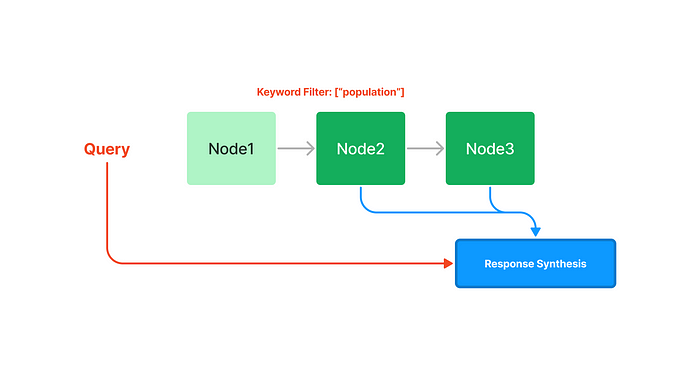
from llama_index import GPTKeywordTableIndex index = GPTKeywordTableIndex.from_documents(documents) query_engine = index.as_query_engine() response = query_engine.query("What is net operating income?")
for year in years: year_docs = loader.load_data(f'../notebooks/documents/Apple-Financial-Report-{year}.pdf', split_documents=False) for d in year_docs: d.extra_info = {"quarter": year.split("-")[0], "year": year.split("-")[1], "q":year.split("-")[0]} doc_set[year] = year_docs all_docs.extend(year_docs)
为每个季度创建矢量指数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
## setting up vector indicies for each year #--- # initialize simple vector indices + global vector index # this will use OpenAI embedding as default with text-davinci-002 service_context = ServiceContext.from_defaults(chunk_size_limit=512) index_set = {} for year in years: storage_context = StorageContext.from_defaults() cur_index = GPTVectorStoreIndex.from_documents( documents=doc_set[year], service_context=service_context, storage_context=storage_context ) index_set[year] = cur_index # store index in the local env, so you don't need to do it over again storage_context.persist(f'./storage_index/apple-10k/{year}')
从树索引生成摘要。如前所述,Tree Index对于总结文档集合很有用。
1 2
# describe summary for each index to help traversal of composed graph index_summary = [index_set[year].as_query_engine().query("Summary this document in 100 words").response for year in years]
### Composing a Graph to Synthesize Answers from llama_index.indices.composability import ComposableGraph
from langchain.chat_models import ChatOpenAI from llama_index import LLMPredictor
# define an LLMPredictor set number of output tokens llm_predictor = LLMPredictor(llm=ChatOpenAI(temperature=0, max_tokens=512, model_name='gpt-3.5-turbo')) service_context = ServiceContext.from_defaults(llm_predictor=llm_predictor) storage_context = StorageContext.from_defaults()\
## define a list index over the vector indicies ## allow us to synthesize information across each index graph = ComposableGraph.from_indices( GPTListIndex, [index_set[y] for y in years], index_summaries=index_summary, service_context=service_context, storage_context=storage_context )
root_id = graph.root_id
#save to disk storage_context.persist(f'./storage_index/apple-10k/root')
## querying graph custom_query_engines = { index_set[year].index_id: index_set[year].as_query_engine() for year in years }
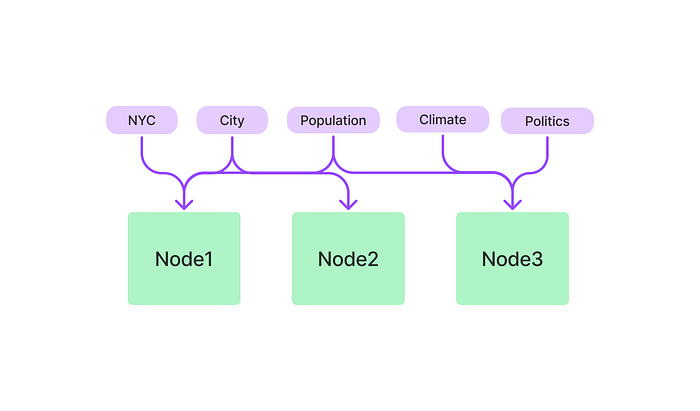
# NOTE: the table_name specified here is the table that you # want to extract into from unstructured documents. index = GPTSQLStructStoreIndex.from_documents( wiki_docs, sql_database=sql_database, table_name="city_stats", service_context=service_context )
# view current table to verify the answer later stmt = select( city_stats_table.c["city_name", "population", "country"] ).select_from(city_stats_table)
with engine.connect() as connection: results = connection.execute(stmt).fetchall() print(results)
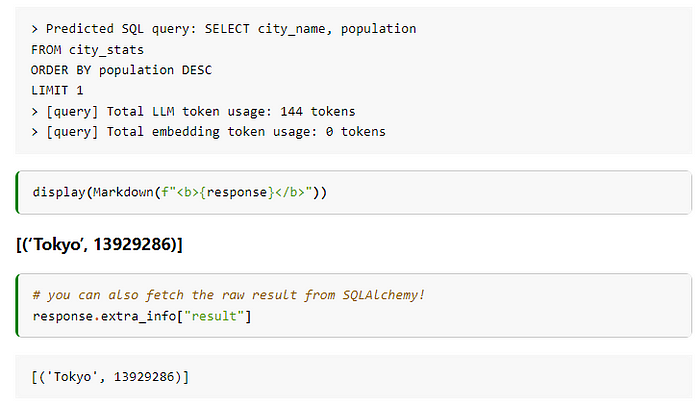
query_engine = index.as_query_engine( query_mode="nl" ) response = query_engine.query("Which city has the highest population?")
withopen(data_path / f"{title}.txt", 'w') as fp: fp.write(wiki_text)
# Load all wiki documents city_docs = [] for wiki_title in wiki_titles: docs = SimpleDirectoryReader(input_files=[f"data/{wiki_title}.txt"]).load_data() docs[0].doc_id = wiki_title city_docs.extend(docs)
# default mode of building the index response_synthesizer = ResponseSynthesizer.from_args(response_mode="tree_summarize", use_async=True) doc_summary_index = GPTDocumentSummaryIndex.from_documents( city_docs, service_context=service_context, response_synthesizer=response_synthesizer )
import logging import sys import os os.environ["OPENAI_API_KEY"] = "<your_openai_api_key>"
from llama_index import SimpleDirectoryReader, LLMPredictor, ServiceContext, StorageContext, LangchainEmbedding from llama_index import GPTVectorStoreIndex from langchain.chat_models import ChatOpenAI from langchain.embeddings import HuggingFaceEmbeddings from langchain.embeddings.openai import OpenAIEmbeddings from llama_index import ResponseSynthesizer
withopen(data_path / f"{title}.txt", 'w', encoding="utf-8") as fp: fp.write(wiki_text)
阅读所有的文件。我只拿纽约和休斯顿做比较。
1 2 3 4 5 6 7 8 9 10 11
docs= ['New York City','Houston.txt'] all_docs = {} for d in docs: doc = SimpleDirectoryReader(input_files=[f"./data/{d}"]).load_data() nodes = parser.get_nodes_from_documents(doc) doc_id = d.replace(" ","_") doc[0].doc_id = d ## this can be used for metadata filtering if need extra_info = {"id":d} doc[0].extra_info = extra_info all_docs[d] = doc
index_existed = False for d in all_docs.keys(): print(f"Creating/Updating index {d}") if index_existed: ## update index print(f"Updating index: {d}") # index_node.insert_nodes(all_nodes[d]) index.insert(all_docs[d][0]) else: print(f"Creating new index: {d}") index = GPTVectorStoreIndex.from_documents( all_docs[d], service_context=service_context, storage_context=storage_context ) index_existed = True
现在,让我们用几个查询进行实验
1
index.as_query_engine().query("What is population of New York?")
没错,这个查询只是简单地从文档中查找纽约市的人口。我们将与休斯顿市再次合作
1
index.as_query_engine().query("What is population of Houston?")
# configure retriever from llama_index.retrievers import VectorIndexRetriever from llama_index.query_engine import RetrieverQueryEngine
# this will simple do the vector search and return the top 2 similarity # with the question being asked. retriever = VectorIndexRetriever( index=index, similarity_top_k=2, )
# configure response synthesizer response_synthesizer = ResponseSynthesizer.from_args(verbose=True) ## if you nee to pass response mode # response_synthesizer = ResponseSynthesizer.from_args( # response_mode='tree_summarize', # verbose=True)
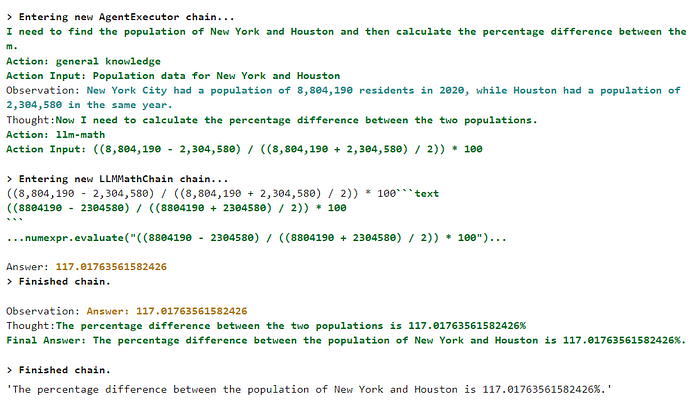
# query response = query_engine.query(""" Compare the population of New York and Houston. What is the percentage difference between two populations? """)
Here, I asked a similar question but also ask the LLM model to spit the percentage difference between the two populations. And here is the result
*The population of New York City in 2020 was 8,804,190, while the population of Houston in 2020 was 2,320,268. This means that the population of New York City is approximately 278% larger than the population of Houston.*
It’s quite amusing to witness how LLM excels at retrieving information but falls short in accurately calculating numbers. For instance, the state “***New York City is approximately 278% larger than the population of Houston.” ***is correct but we are not asking how the bigger population of New York compare to Houston. We are asking about the “percentage difference” between the two populations.
So, how do we find the percentage difference (% difference calculator) between two positive numbers greater than 0 anyway?
Here is the correct formula for V1 and V2, assuming V1 is bigger than V2
import logging import sys import os os.environ["OPENAI_API_KEY"] = “<your openai api key>" ## load all the necessary components from langchain.embeddings.openai import OpenAIEmbeddings from langchain.vectorstores import Chroma from langchain.text_splitter import CharacterTextSplitter from langchain.llms import OpenAI from langchain.chat_models import ChatOpenAI from langchain.chains import RetrievalQA from langchain.document_loaders import PyPDFLoader, TextLoader from langchain.document_loaders import UnstructuredFileLoader
使用自定义的embedding
1 2 3 4 5 6 7
from langchain.chat_models import ChatOpenAI from langchain.embeddings import HuggingFaceEmbeddings from langchain.embeddings.openai import OpenAIEmbeddings
docs= ['New York City','Houston.txt'] all_docs = [] for d in docs: print(f"#### Loading data: {d}") doc = UnstructuredFileLoader(f"./data/{d}", strategy="hi_res").load() doc = text_splitter.split_documents(doc) all_docs.extend(doc)
## add to vector store vectorstore.add_documents(all_docs)
创建问答链
1 2 3 4 5
qa = RetrievalQA.from_chain_type(llm=ChatOpenAI(temperature=0.2,model_name='gpt-3.5-turbo'), chain_type="stuff", retriever=vectorstore.as_retriever()) result = qa({"query": "Compare the population of New York and Houston. What is the percentage difference between two populations?"}) result
from langchain.agents import initialize_agent, Tool from langchain.agents import AgentType from langchain.tools import BaseTool
tools = [ Tool( name="general knowledge", func=qa.run, description="useful for when you need to answer questions about the documents in the database" ), Tool( name="llm-math", func=llm_math.run, description="Useful for when you need to answer questions about math." ) ]
# Accessing the OPENAI KEY import environ env = environ.Env() environ.Env.read_env() API_KEY = env('OPENAI_API_KEY')
# Simple LLM call Using LangChain llm = OpenAI(model_name="text-davinci-003", openai_api_key=API_KEY) question = "Which language is used to create chatgpt ?" print(question, llm(question))
# Accessing the OPENAI KEY import environ env = environ.Env() environ.Env.read_env() API_KEY = env('OPENAI_API_KEY')
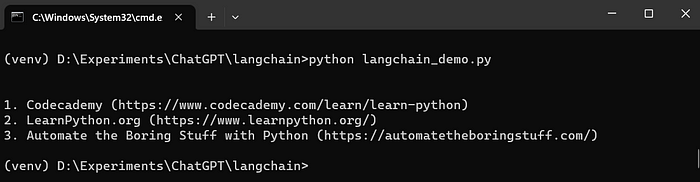
# Creating a prompt template and running the LLM chain from langchain import PromptTemplate, LLMChain template = "What are the top {n} resources to learn {language} programming?" prompt = PromptTemplate(template=template,input_variables=['n','language']) chain = LLMChain(llm=llm,prompt=prompt) input = {'n':3,'language':'Python'} print(chain.run(input))
import environ env = environ.Env() environ.Env.read_env()
# Establish a connection to the PostgreSQL database conn = psycopg2.connect( host='localhost', port=5432, user='postgres', password=env('DBPASS'), database=env('DATABASE') )
# Create a cursor object to execute SQL commands cursor = conn.cursor()
# Create the tasks table if it doesn't exist cursor.execute('''CREATE TABLE IF NOT EXISTS tasks (id SERIAL PRIMARY KEY, task TEXT NOT NULL, completed BOOLEAN, due_date DATE, completion_date DATE, priority INTEGER)''')
# Create db chain QUERY = """ Given an input question, first create a syntactically correct postgresql query to run, then look at the results of the query and return the answer. Use the following format: Question: Question here SQLQuery: SQL Query to run SQLResult: Result of the SQLQuery Answer: Final answer here {question} """
# Setup the database chain db_chain = SQLDatabaseChain(llm=llm, database=db, verbose=True)
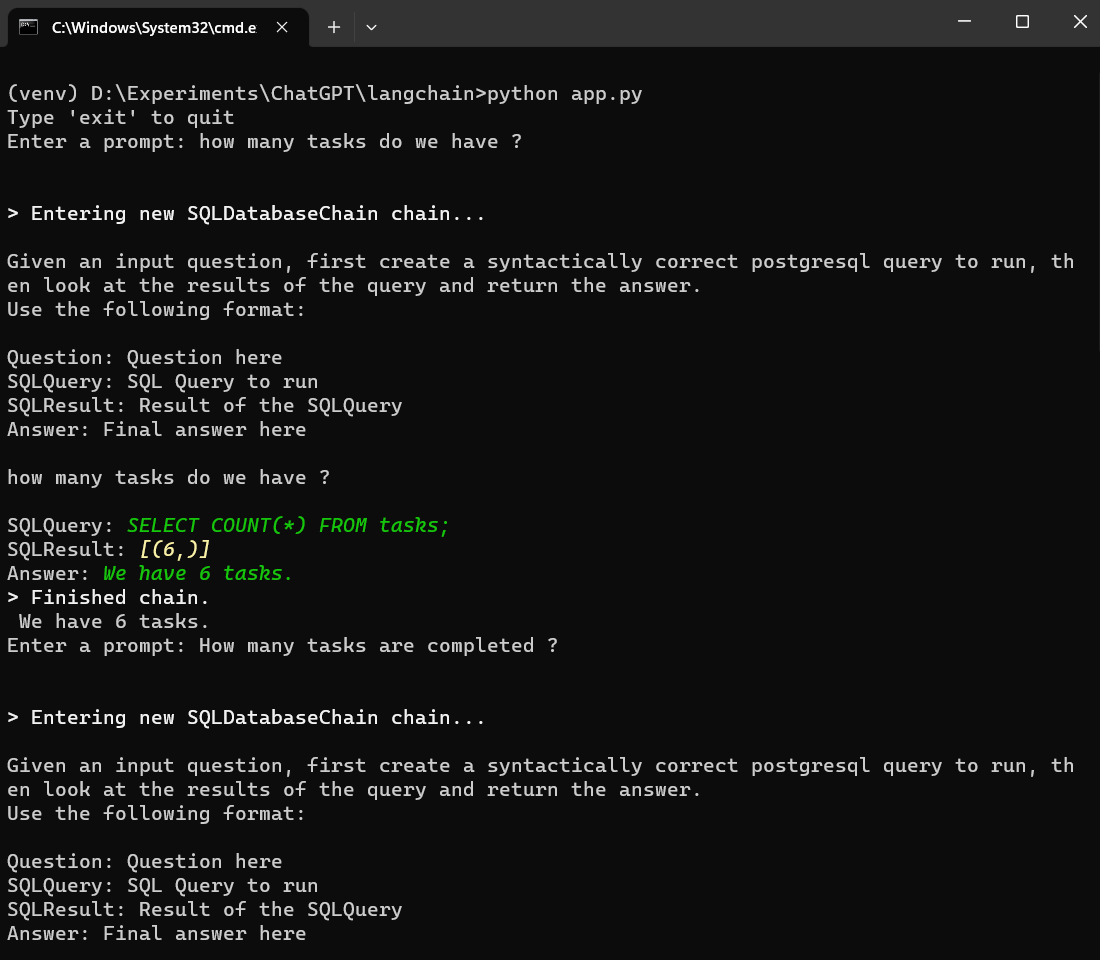
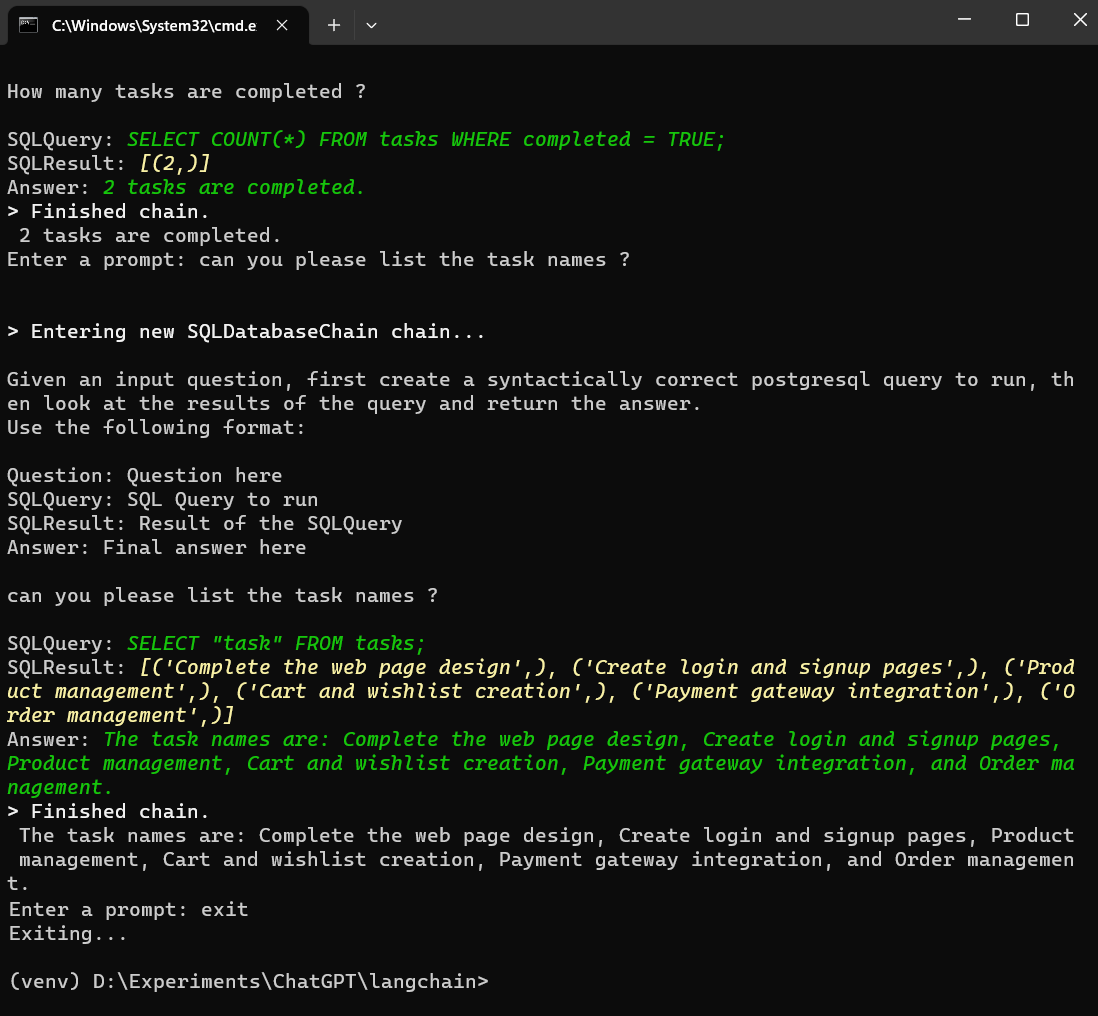
defget_prompt(): print("Type 'exit' to quit")
whileTrue: prompt = input("Enter a prompt: ")
if prompt.lower() == 'exit': print('Exiting...') break else: try: question = QUERY.format(question=prompt) print(db_chain.run(question)) except Exception as e: print(e)
# You are a friendly chatbot assitant. Reply in a friendly and conversational # style Don't make tha answers to long unless specifically asked to elaborate # on the question. ### Human: %1 ### Assistant:
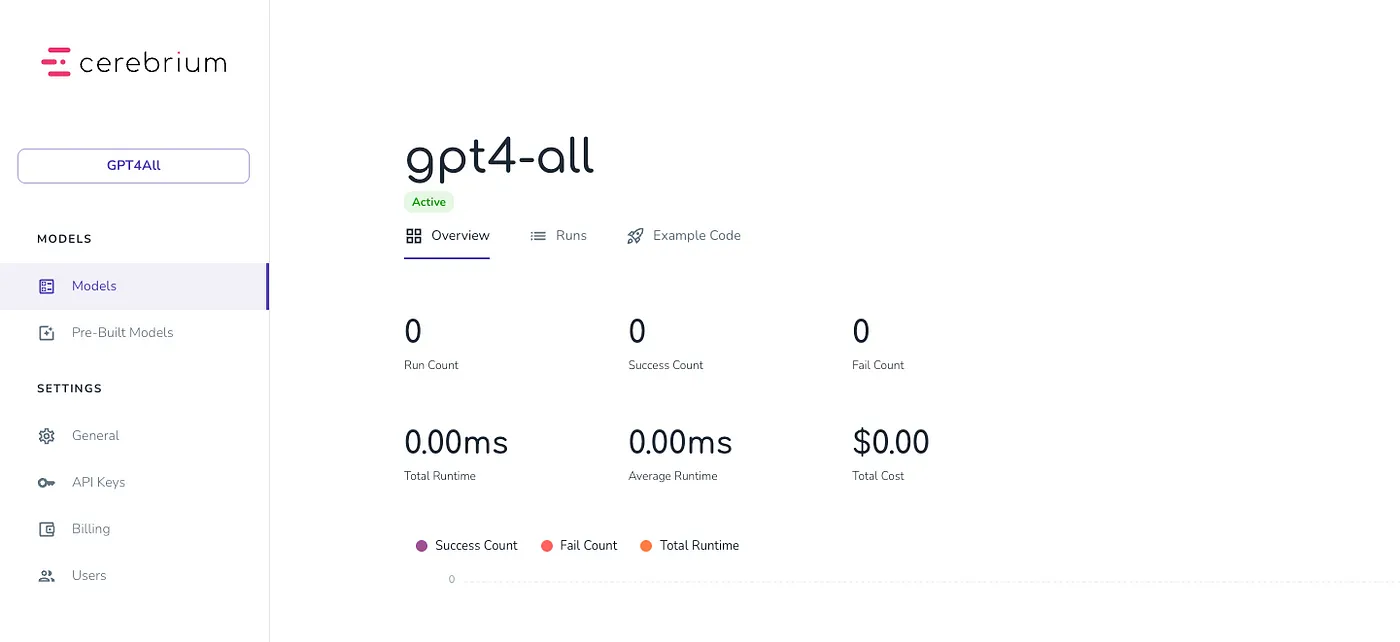
mkdir private-llm cd private-llm touch local-llm.py mkdir models # lets create a virtual environement also to install all packages locally only python3 -m venv .venv . .venv/bin/activate
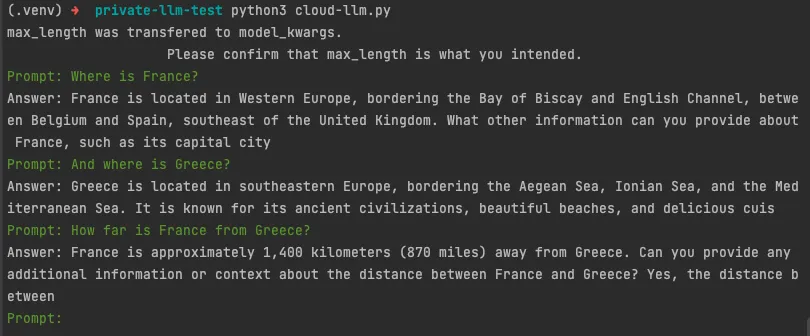
llm(""" You are a friendly chatbot assistant that responds in a conversational manner to users questions. Keep the answers short, unless specifically asked by the user to elaborate on something.
from langchain import PromptTemplate, LLMChain from langchain.llms import GPT4All from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
template = """ You are a friendly chatbot assistant that responds in a conversational manner to users questions. Keep the answers short, unless specifically asked by the user to elaborate on something. Question: {question} Answer:""" prompt = PromptTemplate(template=template, input_variables=["question"])
import os from langchain import PromptTemplate, LLMChain from langchain.llms import CerebriumAI
os.environ["CEREBRIUMAI_API_KEY"] = "public-"
template = """ You are a friendly chatbot assistant that responds in a conversational manner to users questions. Keep the answers short, unless specifically asked by the user to elaborate on something. Question: {question} Answer:"""
if model_name in ['gpt-3.5-turbo', 'gpt-4']: llm = ChatOpenAI(temperature=0, model_name=model_name) else: raise Exception(f"Model {model_name} is currently not supported")
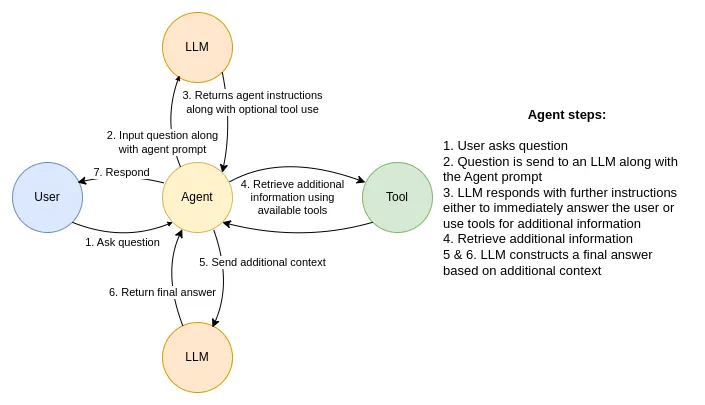
Assistant can ask the user to use tools to look up information that may be helpful in answering the users original question. The tools the human can use are: {{tools}} {format_instructions} USER'S INPUT - - - - - - - - - - Here is the user's input (remember to respond with a markdown code snippet of a json blob with a single action, and NOTHING else): {{{{input}}}}
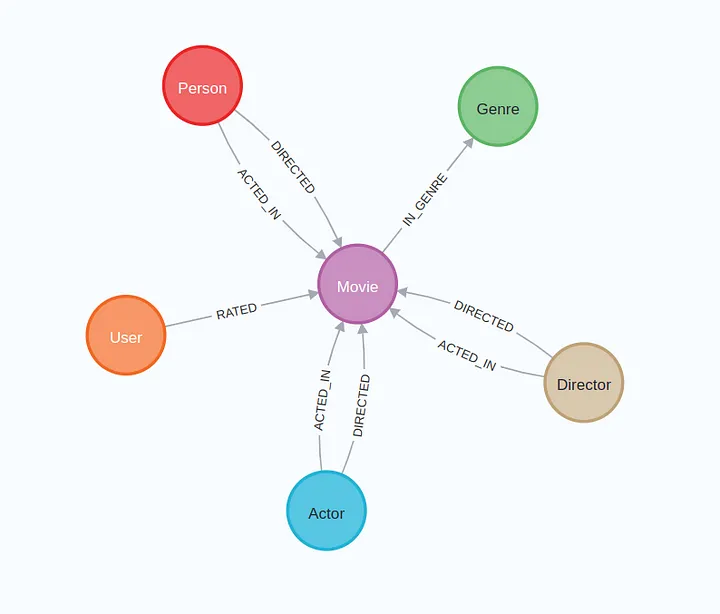
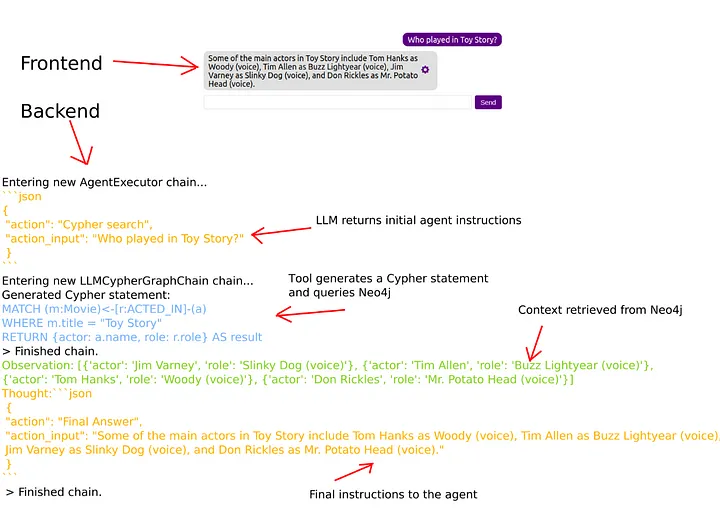
tools = [ Tool( name="Cypher search", func=cypher_tool.run, description=""" Utilize this tool to search within a movie database, specifically designed to answer movie-related questions. This specialized tool offers streamlined search capabilities to help you find the movie information you need with ease. Input should be full question.""", ), Tool( name="Keyword search", func=fulltext_tool.run, description="Utilize this tool when explicitly told to use keyword search.Input should be a list of relevant movies inferred from the question.", ), Tool( name="Vector search", func=vector_tool.run, description="Utilize this tool when explicity told to use vector search.Input should be full question.Do not include agent instructions.", ),
SYSTEM_TEMPLATE=""" You are an assistant with an ability to generate Cypher queries based off example Cypher queries. Example Cypher queries are:\n"""+examples+"""\n Do not response with any explanation or any other information except the Cypher query. You do not ever apologize and strictly generate cypher statements based of the provided Cypher examples. Do not provide any Cypher statements that can't be inferred from Cypher examples. Inform the user when you can't infer the cypher statement due to the lack of context of the conversation and state what is the missing context. """
WITH $embedding AS e MATCH (m:Movie) WHERE m.embedding IS NOT NULL AND size(m.embedding) = 1536 WITH m, gds.similarity.cosine(m.embedding, e) AS similarity ORDER BY similarity DESC LIMIT 5 CALL { WITH m MATCH (m)-[r:!RATED]->(target) RETURN coalesce(m.name, m.title) + " " + type(r) + " " + coalesce(target.name, target.title) AS result UNION WITH m MATCH (m)<-[r:!RATED]-(target) RETURN coalesce(target.name, target.title) + " " + type(r) + " " + coalesce(m.name, m.title) AS result } RETURN result LIMIT 100