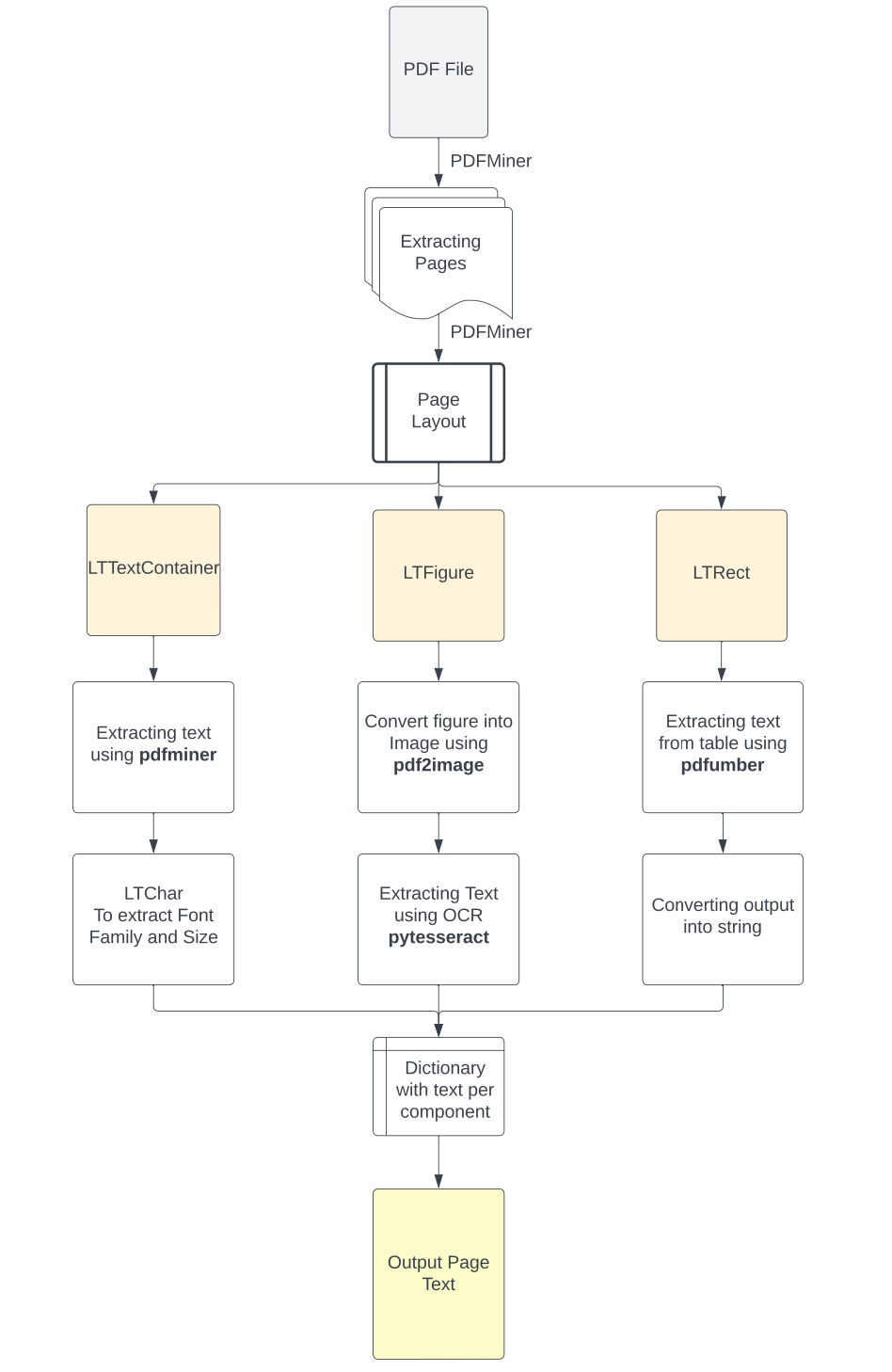
for pagenum, page inenumerate(extract_pages(pdf_path)):
# Iterate the elements that composed a page for element in page:
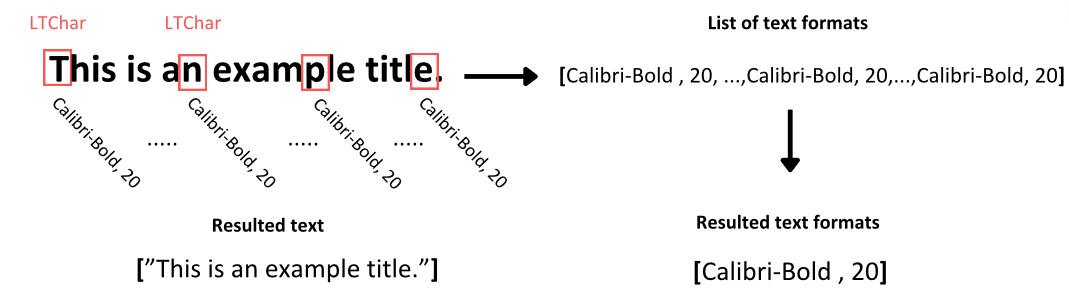
# Check if the element is a text element ifisinstance(element, LTTextContainer): # Function to extract text from the text block pass # Function to extract text format pass
# Check the elements for images ifisinstance(element, LTFigure): # Function to convert PDF to Image pass # Function to extract text with OCR pass
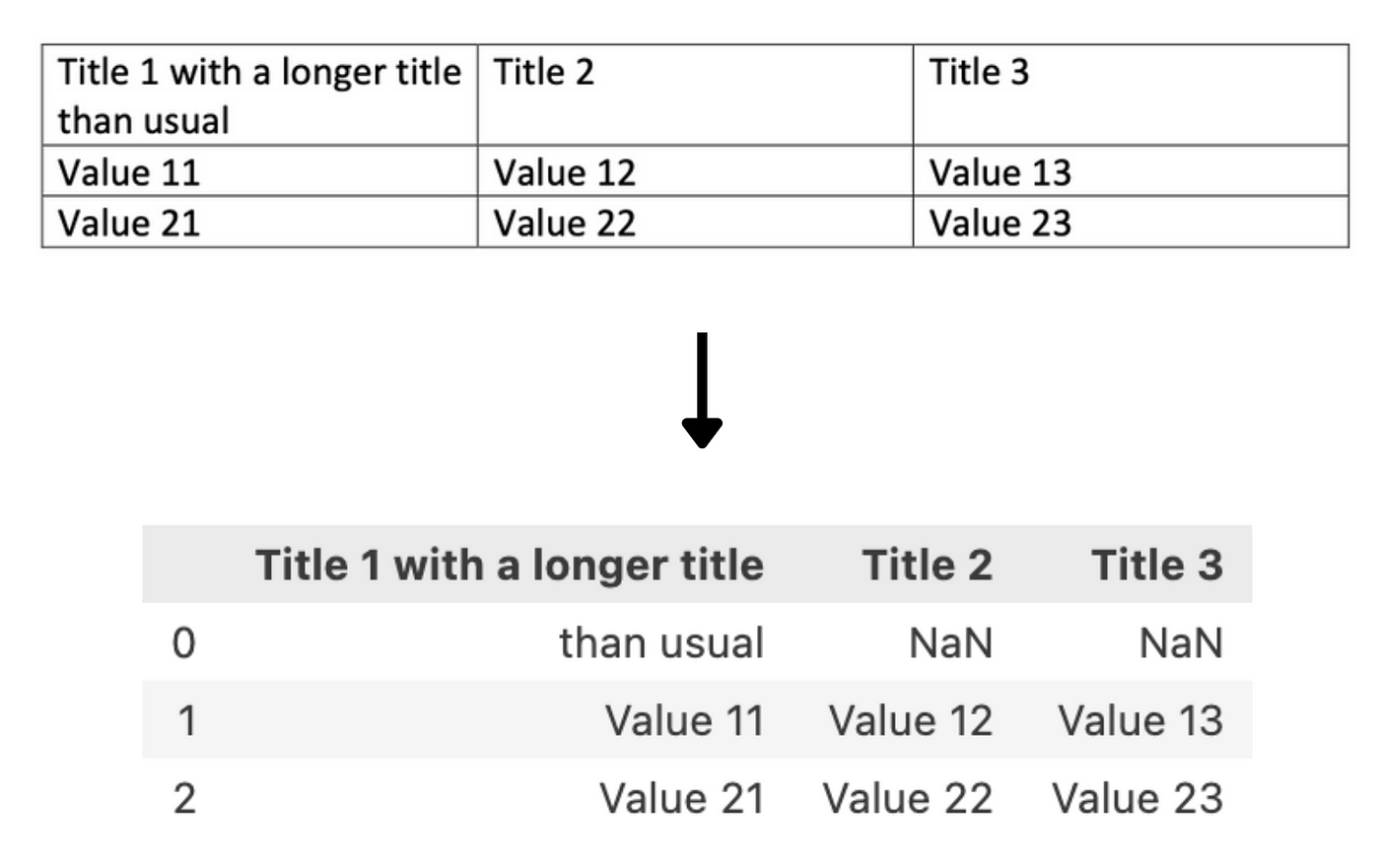
# Check the elements for tables ifisinstance(element, LTRect): # Function to extract table pass # Function to convert table content into a string pass
# Create an HNSW index # Note: You don't need to specify m and ef_construction parameters as we set smart defaults. ts_vector_store.create_index("hnsw", m=16, ef_construction=64)
# Create an IVFFLAT index # Note: You don't need to specify num_lists and num_records parameters as we set smart defaults. ts_vector_store.create_index("ivfflat", num_lists=20, num_records=1000)
from timescale_vector import client # Function to take in a date string in the past and return a uuid v1 defcreate_uuid(date_string: str): if date_string isNone: returnNone time_format = '%a %b %d %H:%M:%S %Y %z' datetime_obj = datetime.strptime(date_string, time_format) uuid = client.uuid_from_time(datetime_obj) returnstr(uuid)
Tue Sep 521:03:212023 +0530 Lakshmi Narayanan Sreethar Fix segfault in set_integer_now_func When an invalid function oid is passed to set_integer_now_func, it finds out that the function oid is invalid but before throwing the error, it calls ReleaseSysCache on an invalid tuple causing a segfault. Fixed that by removing the invalid call to ReleaseSysCache. Fixes #6037
# Create a timescale vector store and add the newly created nodes to it ts_vector_store = TimescaleVectorStore.from_params( service_url=TIMESCALE_SERVICE_URL, table_name="li_commit_history", time_partition_interval= timedelta(days=7), ) ts_vector_store.add(nodes)
# Time filter variables for query start_dt = datetime(2023, 8, 1, 22, 10, 35) # Start date = 1 August 2023, 22:10:35 end_dt = datetime(2023, 8, 30, 22, 10, 35) # End date = 30 August 2023, 22:10:35
# return most similar vectors to query between start date and end date date range # returns a VectorStoreQueryResult object query_result = ts_vector_store.query(vector_store_query, start_date = start_dt, end_date = end_dt)
# for each node in the query result, print the node metadata date for node in query_result.nodes: print("-" * 80) print(node.metadata["date"]) print(node.get_content(metadata_mode="all")) -------------------------------------------------------------------------------- 2023-08-314:30:23+0500 commit: 7aeed663b9c0f337b530fd6cad47704a51a9b2ec author: Dmitry Simonenko date: 2023-08-314:30:23+0500
Thu Aug 314:30:232023 +0300 Dmitry Simonenko Feature flags for TimescaleDB features This PR adds.. -------------------------------------------------------------------------------- 2023-08-2918:13:24+0320 commit: e4facda540286b0affba47ccc63959fefe2a7b26 author: Sven Klemm date: 2023-08-2918:13:24+0320
Tue Aug 2918:13:242023 +0200 Sven Klemm Add compatibility layer for _timescaledb_internal functions With timescaledb 2.12all the functions present in _timescaledb_internal were… -------------------------------------------------------------------------------- 2023-08-2212:01:19+0320 commit: cf04496e4b4237440274eb25e4e02472fc4e06fc author: Sven Klemm date: 2023-08-2212:01:19+0320
Tue Aug 2212:01:192023 +0200 Sven Klemm Move utility functions to _timescaledb_functions schema To increase schema security we do not want to mix… -------------------------------------------------------------------------------- 2023-08-2910:49:47+0320 commit: a9751ccd5eb030026d7b975d22753f5964972389 author: Sven Klemm date: 2023-08-2910:49:47+0320
Tue Aug 2910:49:472023 +0200 Sven Klemm Move partitioning functions to _timescaledb_functions schema To increase schema security… -------------------------------------------------------------------------------- 2023-08-915:26:03+0500 commit: 44eab9cf9bef34274c88efd37a750eaa74cd8044 author: Konstantina Skovola date: 2023-08-915:26:03+0500
Wed Aug 915:26:03 2023 +0300 Konstantina Skovola Release 2.11.2 This release contains bug fixes since the 2.11.1 release…
# return most similar vectors to query from start date and a time delta later query_result = ts_vector_store.query(vector_store_query, start_date = start_dt, time_delta = td)
# return most similar vectors to query from end date and a time delta earlier query_result = ts_vector_store.query(vector_store_query, end_date = end_dt, time_delta = td)
from llama_index import VectorStoreIndex from llama_index.storage import StorageContext
index = VectorStoreIndex.from_vector_store(ts_vector_store) query_engine = index.as_query_engine(vector_store_kwargs = ({"start_date": start_dt, "end_date":end_dt}))
query_str = "What's new with TimescaleDB functions? When were these changes made and by whom?" response = query_engine.query(query_str) print(str(response))
我们问了LLM一个关于我们的git日志的问题,即“What`s new with TimescaleDB functions? When were these changes made and by whom?”(“TimescaleDB函数有什么新功能?”这些改动是什么时候做的,是谁做的?”)
TimescaleDB functions have undergone changes recently. These changes include the addition of several GUCs (Global User Configuration) that allow for enabling or disabling major TimescaleDB features. Additionally, a compatibility layer has been added for the "_timescaledb_internal" functions, which were moved into the "_timescaledb_functions" schema to enhance schema security. These changes were made by Dmitry Simonenko and Sven Klemm. The specific dates of these changes are August 3, 2023, and August 29, 2023, respectively.
from llama_index.embeddings import OpenAIEmbedding from llama_index import ServiceContext, VectorStoreIndex from llama_index.schema import TextNode from tqdm.notebook import tqdm import pandas as pd
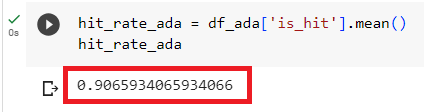
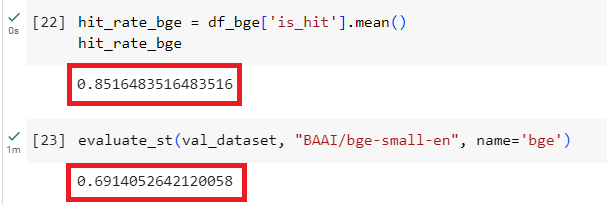
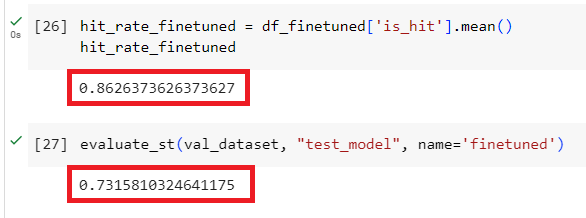
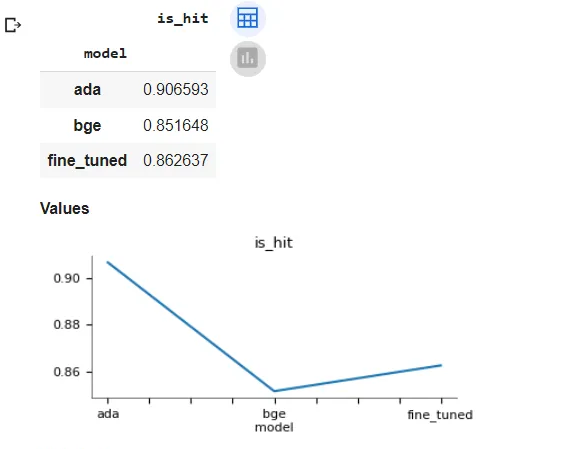
# function for hit rate evals defevaluate( dataset, embed_model, top_k=5, verbose=False, ): corpus = dataset.corpus queries = dataset.queries relevant_docs = dataset.relevant_docs
service_context = ServiceContext.from_defaults(embed_model=embed_model) nodes = [TextNode(id_=id_, text=text) for id_, text in corpus.items()] index = VectorStoreIndex(nodes, service_context=service_context, show_progress=True) retriever = index.as_retriever(similarity_top_k=top_k)
eval_results = [] for query_id, query in tqdm(queries.items()): retrieved_nodes = retriever.retrieve(query) retrieved_ids = [node.node.node_id for node in retrieved_nodes] expected_id = relevant_docs[query_id][0] is_hit = expected_id in retrieved_ids # assume 1 relevant doc
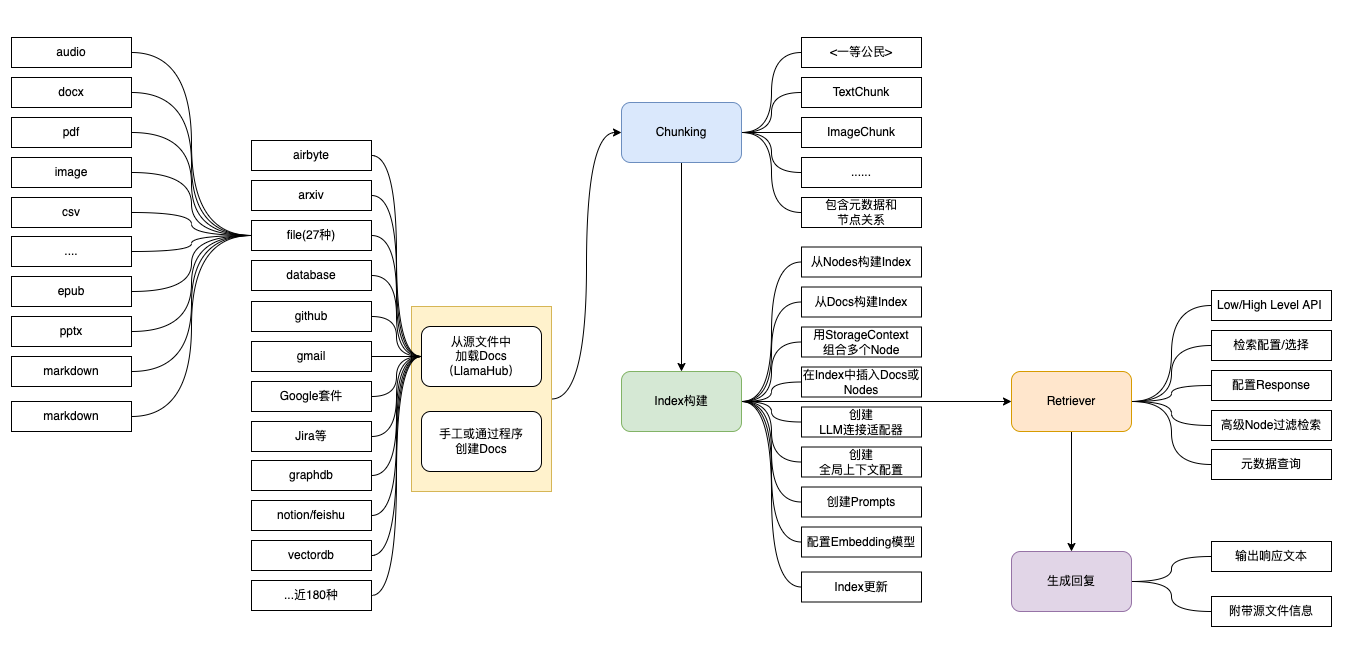
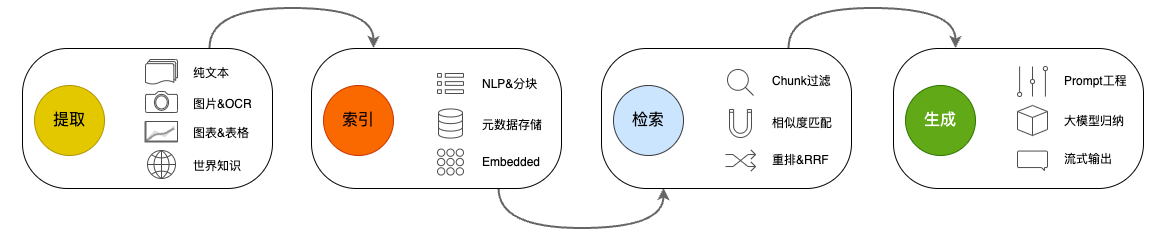
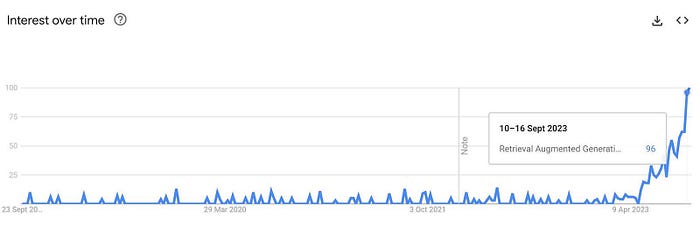
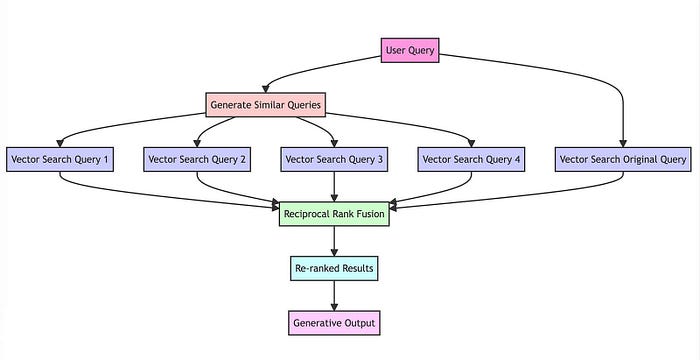
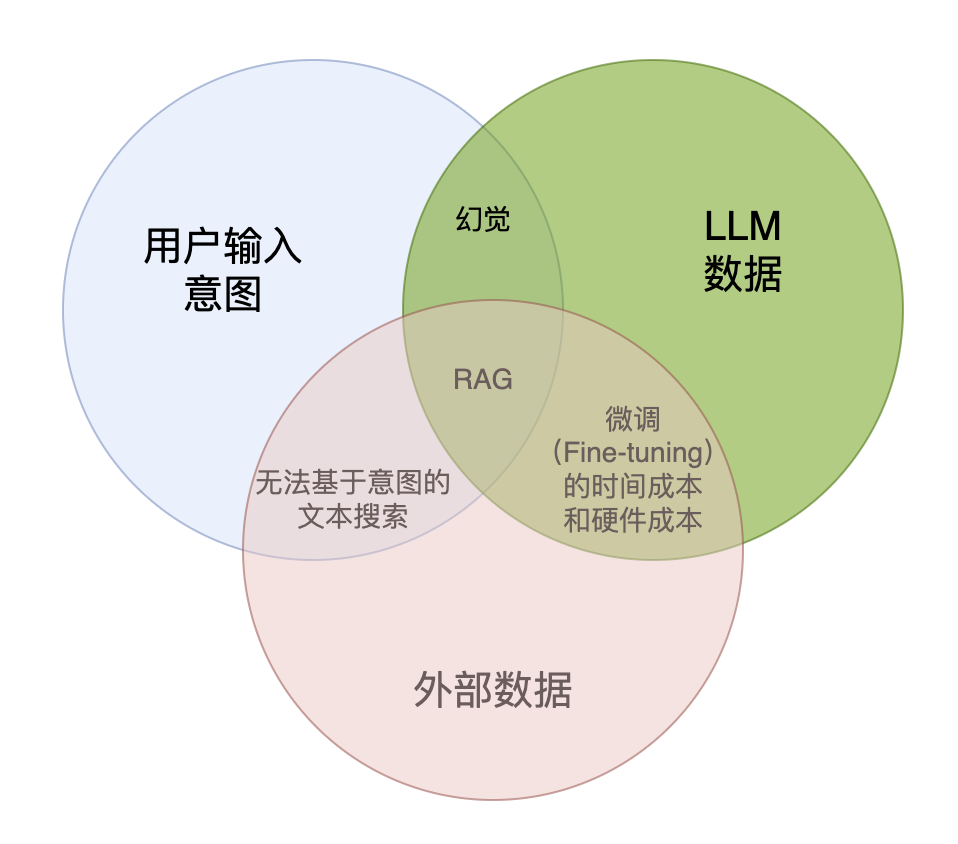
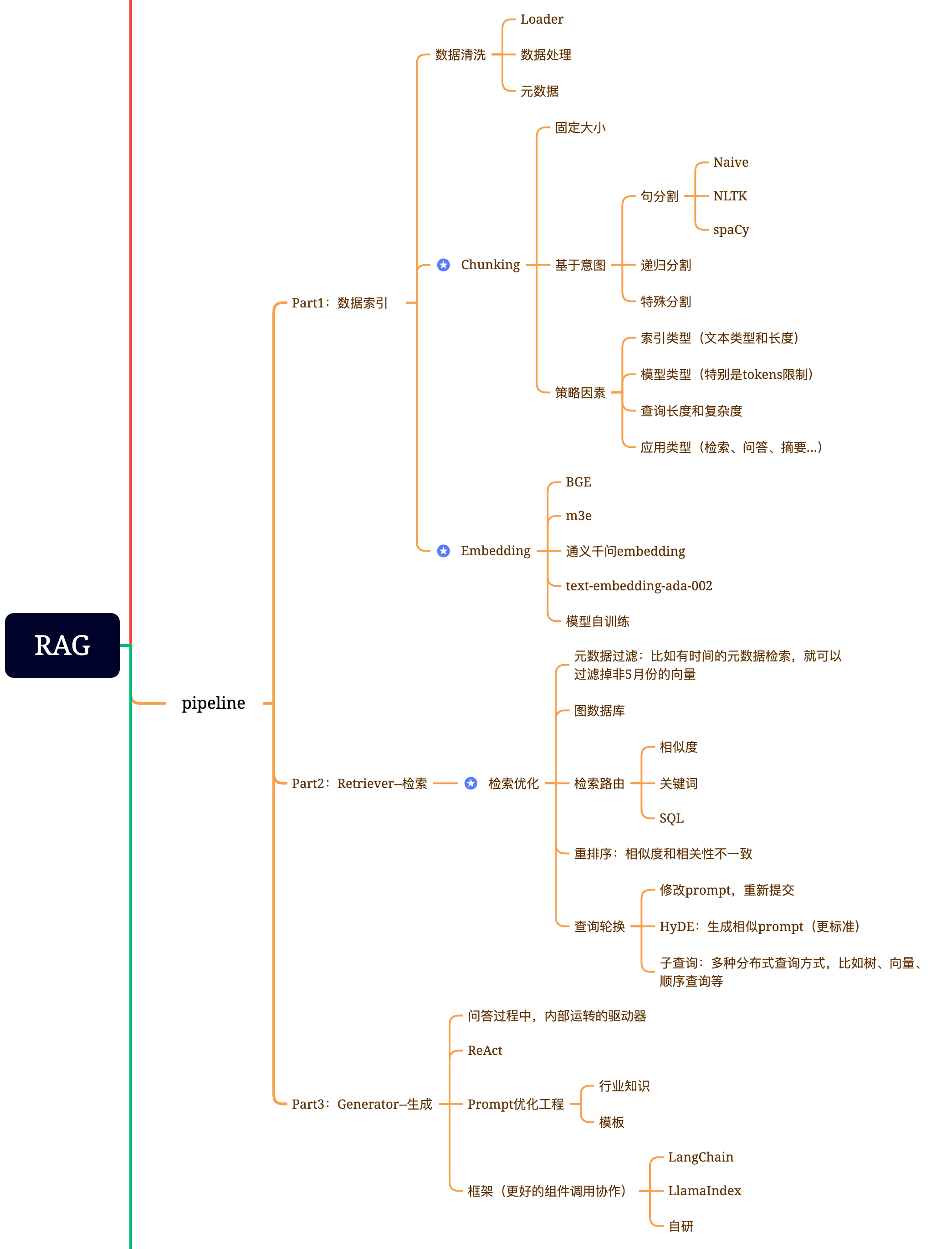
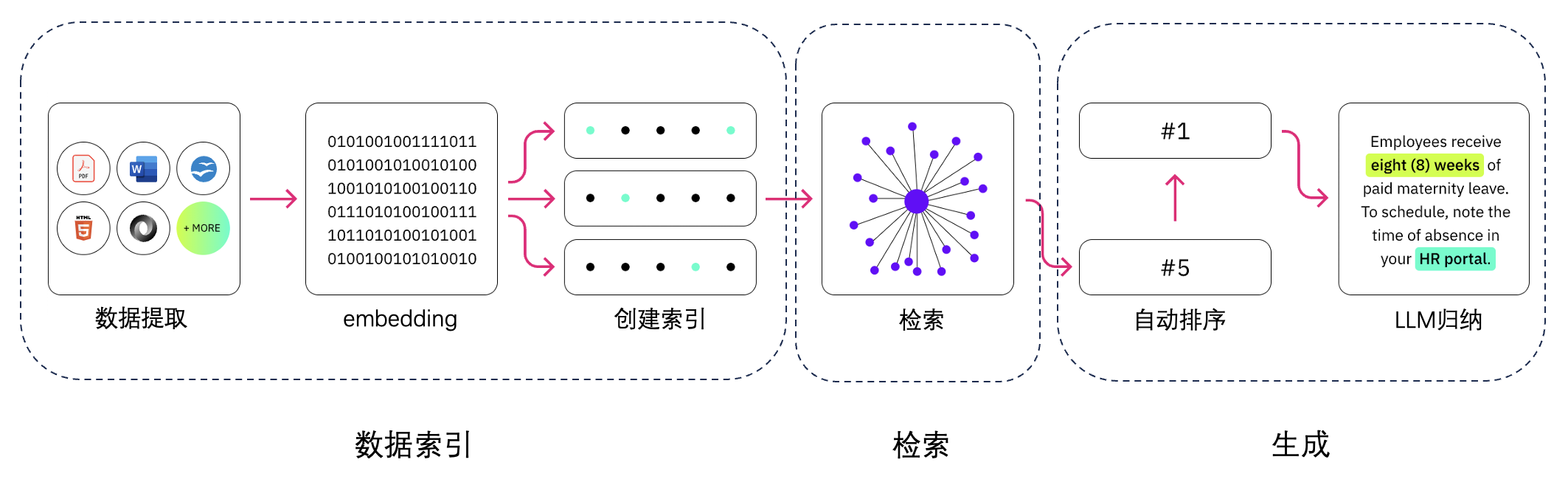
下面我们来了解一下RAG,它有非常多的组件,但是我们可以化繁为简。我喜欢把RAG——Retrieval Augmented Generation理解为Retrieval And Generation,也就是检索与生成,在加上一个数据向量和索引的工作,我们对RAG就可以总概方式地理解为“索引、检索和生成”。