让RAG的海量Embedding速度提升百倍
【译文】让RAG面对海量embedding时提速100倍
土猛的员外
作为人类,我们可以阅读和理解文本(至少其中一些文本)。相反,计算机“用数字思考”,所以它们不能自动掌握单词和句子的意思。如果我们想让计算机理解自然语言,我们需要将这些信息转换成计算机可以处理的格式——数字向量。
许多年前,人们就学会了如何将文本转换为机器可理解的格式(最早的版本之一是ASCII)。这种方法有助于呈现和传输文本,但不编码单词的含义。当时,标准的搜索技术是搜索包含特定单词或N-gram的所有文档时使用的关键字搜索。
然后,几十年后,Embeddings出现了。我们可以计算单词、句子甚至图像的Embeddings。Embeddings也是数字向量,但它们可以捕捉到含义。因此,您可以使用它们进行语义搜索,甚至处理不同语言的文档。
在本文中,我想更深入地探讨Embedding主题并讨论所有细节:
让我们继续了解Embeddings的演变。
Re-ranking在检索增广生成(RAG)过程中起着至关重要的作用。在朴素的RAG方法中,可以检索大量上下文,但并非所有上下文都与问题相关。重新排序允许对文档进行重新排序和过滤,将相关的文档放在最前面,从而提高RAG的有效性。
本文介绍了RAG的重新排序技术,并演示了如何使用两种方法合并重新排序功能
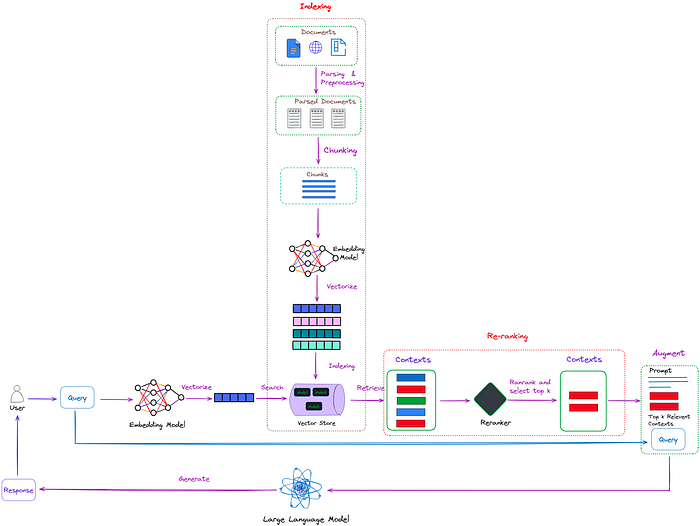
图1:在RAG中重排,重排的任务是评估这些上下文的相关性,并优先考虑最有可能提供准确和相关答案的上下文(红框)。图片来自作者。
如图1所示,重排的任务就像一个智能过滤器。当检索器从索引集合中检索多个上下文时,这些上下文可能与用户的查询具有不同的相关性。有些上下文可能非常相关(在图1中的红色框中突出显示),而其他上下文可能只是稍微相关,甚至不相关(在图1中的绿色和蓝色框中突出显示)。
重排的任务是评估这些上下文的相关性,并优先考虑最有可能提供准确和相关答案的上下文。这允许LLM在生成答案时优先考虑这些排名靠前的上下文,从而提高响应的准确性和质量。
简单来说,重新排名就像在开卷考试中帮助你从一堆学习材料中选择最相关的参考资料,这样你就可以更有效、更准确地回答问题。
本文介绍的重新排序方法主要分为以下两种:
如果您已经为实际的业务系统开发了检索增强生成(Retrieval Augmented Generation, RAG)应用程序,那么您可能会关心它的有效性。换句话说,您想要评估RAG的性能。
此外,如果您发现您现有的RAG不够有效,您可能需要验证先进的RAG改进方法的有效性。换句话说,您需要进行评估,看看这些改进方法是否有效。
在本文中,我们首先介绍了由RAGAs(检索增强生成评估)提出的RAG的评估指标,这是一个用于评估RAG管道的框架。然后,我们解释了如何使用RAGAs + LlamaIndex实现整个评估过程。
简单地说,RAG的过程包括三个主要部分:输入查询、检索上下文和LLM生成的响应。这三个要素构成了RAG过程中最重要的三位一体,并且是相互依存的。
因此,可以通过测量这些三元组之间的相关性来评估RAG的有效性,如图1所示。
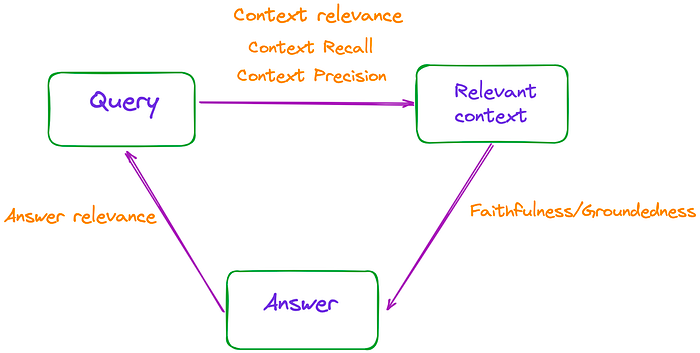
图1:RAG的有效性可以通过测量这些三元组之间的相关性来评估。图片来自作者。
论文总共提到了3个指标:忠实度、答案相关性和上下文相关性,这些指标不需要访问人工注释的数据集或参考答案。
对于RAG,从文档中提取信息是一个不可避免的场景。确保从源头提取内容的有效性对于提高最终输出的质量至关重要
重要的是不要低估这个过程。在实现RAG时,解析过程中的信息提取不佳可能导致对PDF文件中包含的信息的理解和利用受到限制。
pass过程在RAG中的位置如图1所示:
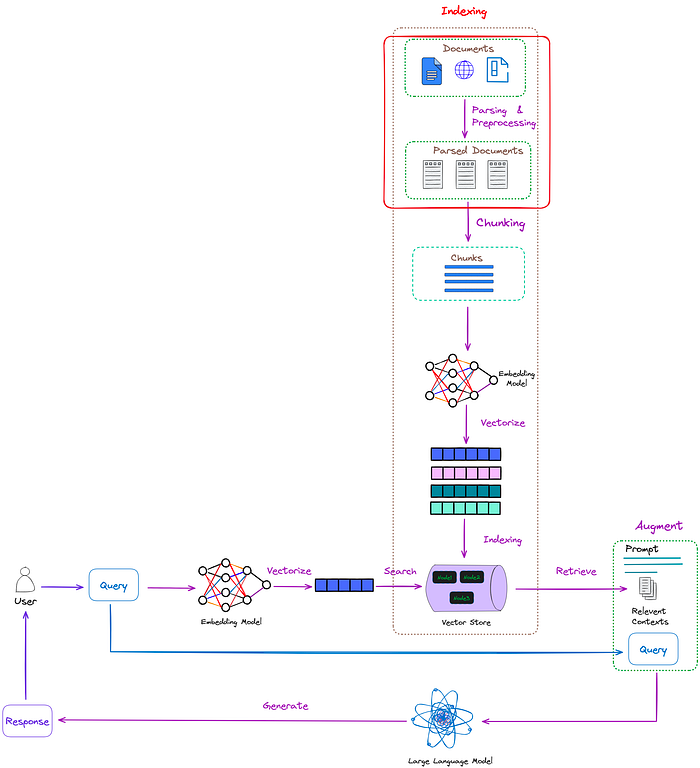
图1:通过过程在RAG中的位置(红框)。图片来自作者。
在实际工作中,非结构化数据要比结构化数据丰富得多。如果这些海量的数据不能被解析,它们的巨大价值就无法实现。
在非结构化数据中,PDF文档占多数。有效地处理PDF文档还可以**极大地帮助管理其他类型的非结构化文档
本文主要介绍解析PDF文件的方法。它提供了有效解析PDF文档和提取尽可能多的有用信息的算法和建议
检索增强生成(RAG)是通过集成来自外部知识来源的附加信息来改进大型语言模型(大语言模型)的过程。这允许大语言模型产生更精确和上下文感知的反应,同时也减轻幻觉。
自2023年以来,RAG已成为基于LLM的系统中最流行的架构。许多产品的功能都严重依赖于RAG。因此,优化RAG的性能,使检索过程更快,结果更准确成为一个至关重要的问题。
本系列文章将重点介绍先进的RAG技术,以提高RAG生成的质量。
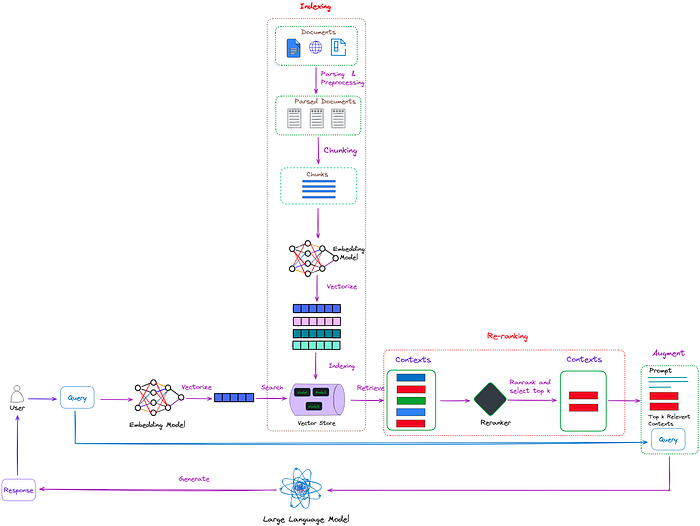
朴素RAG的典型工作流程如图1所示。
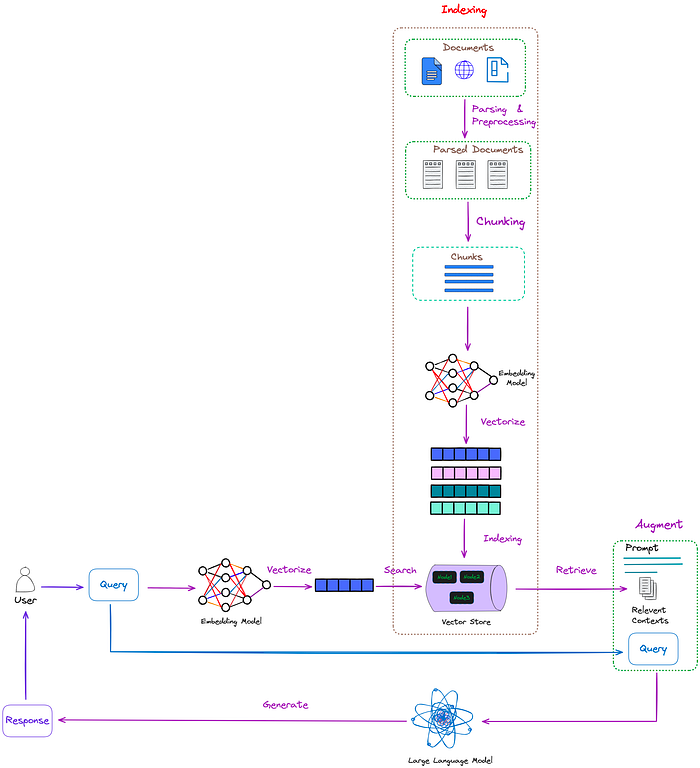
图1:朴素RAG的典型工作流程。图片来自作者。
如图1所示,RAG主要包括以下几个步骤:
从2023年11月29日开始启动公司(杭州萌嘉网络科技有限公司),到12月中旬开始研发TorchV,第一个对外试用版本终于开始接受试用了。
欢迎企业用户试用,共同探讨AI的企业应用落地。
下面的内容主要分为:
- TorchV Bot产品介绍;
- 有哪些可以说道的特性;
- 如何试用?
- 合作方式;
- 附录1:RAG简要说明;
- 附录2:TorchV Bot操作说明
TorchV Bot是一款基于大语言模型(Large Language Model,后文简称LLM)和检索增强生成(Retrieval-augmented generation,后文简称RAG)技术的人工智能问答机器人,属于TorchV最主要的三款产品(Bot、Assistant和Analyst)中一款。
这是一篇翻译文章,觉得确实很有启发,所以发出来大家一起看看。
我们现在做RAG应用,对于tokens确实很敏感,能省一些是一些吧,但是这篇文章是针对英文的,不知道对于中文支持的怎么样?
我们后面也会真正用起来,会再给大家汇报一下使用效果,或者会发布我们自己的改良方法。
感谢原作者:Iulia Brezeanu,原文和引用在文末。
推理过程是使用大型语言模型时消耗资金和时间成本的因素之一,对于较长的输入,这个问题会更加凸显。下面,您可以看到模型性能与推理时间之间的关系。
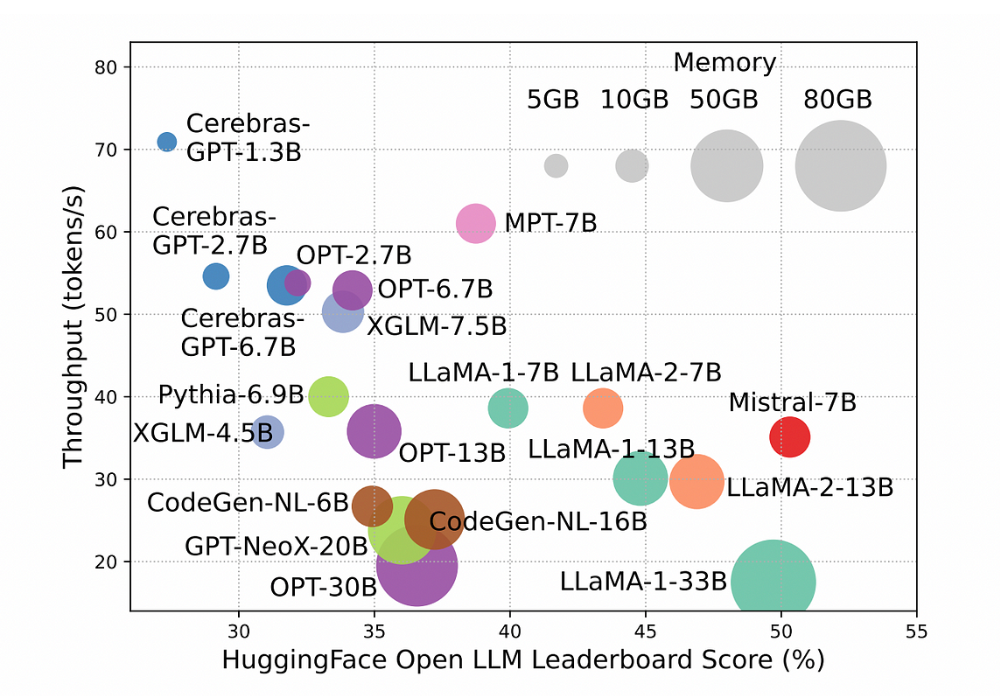
小型模型每秒生成更多的tokens,往往在Open LLM排行榜上得分较低。增加模型参数大小可以提高性能,但会降低推理吞吐量。这使得在实际应用中部署它们变得困难[1]。
提高LLMs的速度并减少资源需求将使其能够更广泛地被个人或小型组织使用。
对于提高LLM的效率,目前大家提出了不同的解决方案来,有些人会关注模型架构或系统。然而,像ChatGPT或Claude这样的专有模型只能通过API访问,因此我们无法改变它们的内部算法。
本文我们将讨论一种简单且廉价的方法,该方法仅依赖于改变输入给模型的方式——即提示压缩。
AI领域最近的风声:2024是RAG爆发年。
对于这些信息,我的理解是这样的:
LLMs属于Infra,属于大厂和已经被资本投资的“AI大厂”们玩的,2023年大部分的投资也都是大额的,聚焦在LLMs这一领域。但是LLMs要找到健康的商业模式,必须与更丰富的业务场景结合起来,就需要大量基于LLMs的应用去拓展市场,不论是toC还是toB。所以到了Q4,有些资本已经在讨论2024年的投资要更加分散,更关注AI原生应用。作为基于LLMs应用支撑技术的RAG,也就必然会被特别关注,我想这就是所谓的2024是RAG爆发年的道理了。
但是今天我不是来讨论RAG的,虽然公众号“土猛的员外”是有很明显的RAG标签的,我今天更想讨论的是AI原生应用(AI-Native App)这个话题:
- 什么是AI原生应用?
- AI原生应用有什么不同之处?
- AI原生应用的猜想
在讲什么是AI原生应用之前,我们可以先来看看电动机在最开始时候的应用。