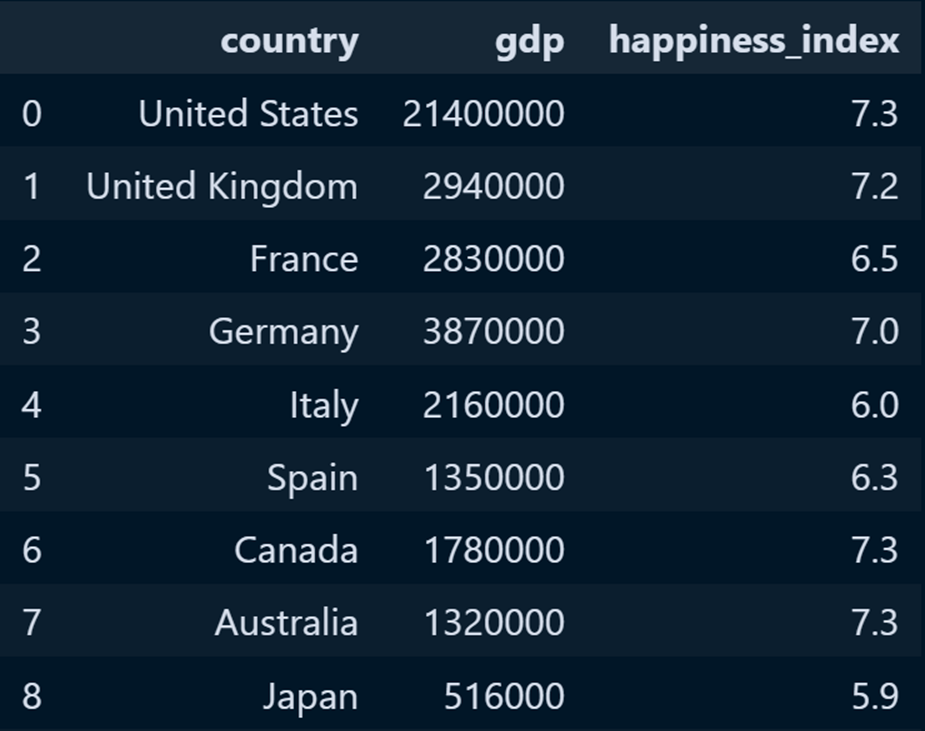
使用向量Embeddings优化LLM应用程序
性价比更高的OpenAI API替代品
以及我们如何从LlamaIndex转向Langchain
当我在开发自己的LLM应用程序时,发生了一些事情。我发现我实验的每个Embedding模型都会产生不同的有趣结果。有些简直太好了,而另一些则略低于预期。这让我思考:
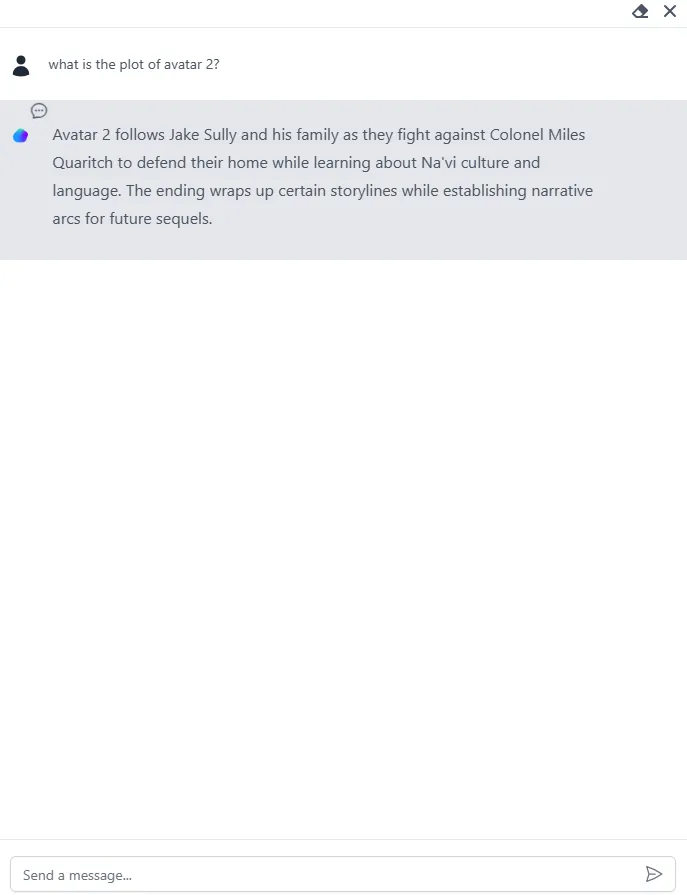
我们如何才能真正掌握这些Embedding模型的力量,并理解它们对聊天机器人性能的影响?
所以,我忍不住想通过这篇文章与你分享我的见解。
相信我,在投入到自己的项目之前,用这些基本知识武装自己是非常值得的。毕竟,每座伟大的房子都是建立在坚实的基础上的,对吧?别担心,我保证这不会是一场无聊的大学讲座。我确保包含了大量的实用教程和引人入胜的例子,让你在阅读过程中保持兴奋。
什么是向量Embedding
在AI聊天机器人的开发领域中,向量Embedding在获取文本信息的本质方面起着关键作用。向量Embedding的核心是指在数学空间中将单词、句子甚至整个文档表示为密集的低维向量的过程。与依赖于稀疏表示(如one-hot编码)的传统方法不同,向量Embeddings封装了单词之间的语义关系,并使算法能够理解它们的上下文含义。
通过使用词Embeddings、句子Embeddings或上下文Embedding等技术,向量Embeddings提供了文本数据的紧凑而有意义的表示。例如,单词Embeddings将单词映射到固定长度的向量,其中具有相似含义的单词在向量空间中的位置更接近。这允许高效的语义搜索、信息检索和语言理解任务。
向量Embedding的重要性在于它能够将原始文本转换为算法可以理解和推理的数字表示。这种转换过程不仅促进了各种自然语言处理(NLP)任务,而且还作为大型语言模型的基本构建块。向量Embeddings使这些模型能够利用嵌入在文本数据中的丰富语义信息,使它们能够生成更连贯和上下文更合适的响应。
向量Embeddings如何捕获语义信息
向量Embeddings通过将单词、句子或文档表示为数学空间中的密集向量来捕获语义信息。这些向量被设计用于对文本元素之间的上下文和语义关系进行编码,从而允许更细致的理解和分析。
捕获语义信息的过程从在大量文本语料库上训练向量Embedding模型开始。在训练过程中,模型学习以反映其语义相似性和上下文的方式将向量分配给单词或单词序列。这是通过分析训练数据中单词的共现模式来实现的。
例如,在单词Embeddings中,例如Word2Vec或GloVe,在相似的上下文中经常一起出现的单词由在Embedding空间中位置更接近的向量表示。这种接近反映了它们的语义相似性。通过利用庞大数据集中单词使用的统计模式,这些Embeddings捕获语义关系,如同义词、类比,甚至更广泛的概念,如性别或情感。
如果你想深入了解向量Embedding的更多信息,你可能会发现这篇文章非常有帮助,感谢parte做了这么好的工作来解释向量Embedding:https://partee.io/2022/08/11/vector-embeddings/
向量Embeddings对大型语言模型应用的重要性
向量Embeddings在大型语言模型(LLM)应用领域中具有非常重要的意义。大语言模型,如GPT-3、BERT或基于transformer的模型,由于其产生连贯和上下文适当的响应的卓越能力,已经获得了显著的关注和普及。
大语言模型的成功取决于他们对自然语言语义复杂性的理解。这就是矢量Embeddings发挥作用的地方。通过使用向量Embeddings,大语言模型可以利用文本数据中嵌入的丰富语义信息,使它们能够生成更复杂和上下文感知的响应。
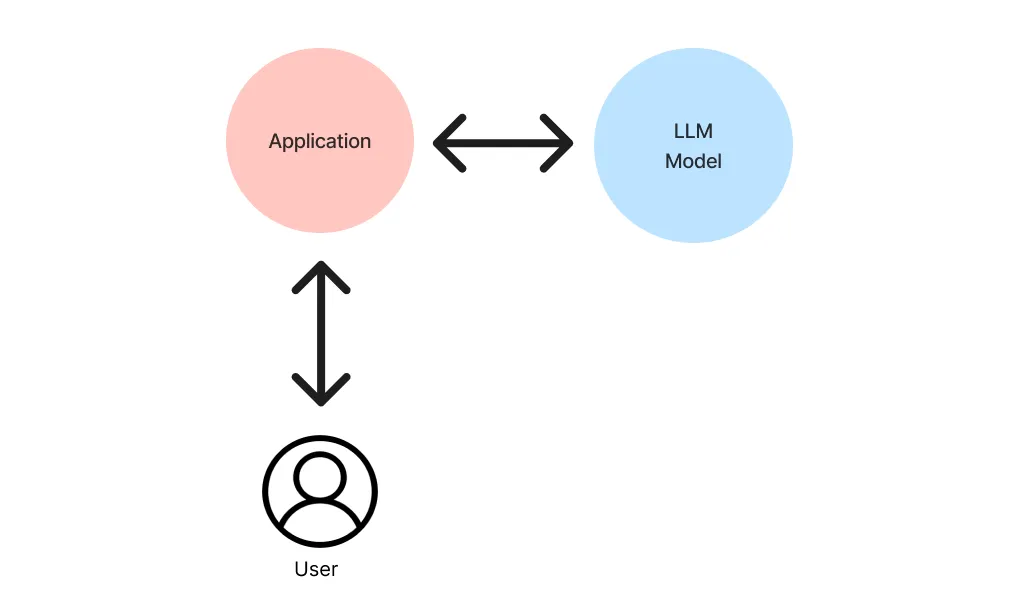
向量Embeddings是原始文本输入和语言模型神经网络之间的桥梁。Embeddings不是为模型提供离散的单词或字符,而是提供捕获输入的含义和上下文的连续表示。这使得大语言模型能够在更高的语言理解水平上运作,并产生更连贯和上下文合适的输出。
向量Embeddings对大语言模型的重要性超越了语言生成。这些Embeddings还促进了一系列下游任务,如情感分析、命名实体识别、文本分类等。通过结合预训练的向量Embeddings,大语言模型可以利用在Embedding训练过程中捕获的知识,从而提高这些任务的性能。
此外,向量Embeddings可以在大语言模型中实现迁移学习和微调。预训练的Embeddings可以在不同的模型甚至不同的领域之间共享,为在特定任务或数据集上训练模型提供一个起点。这种知识的转移允许更快的训练,改进的泛化,以及在专门任务上更好的表现。
到目前为止,您应该对向量Embedding及其在开发LLM应用程序中的意义有了扎实的掌握。在下面的部分中,让我们直接比较不同的Embedding模型。如果你像我一样,因为太穷而无法支付而寻求OpenAI API的替代方案:(),本指南将帮助您选择最适合您特定任务的Embedding模型。
再次,我将把解释向量Embedding的所有艰苦工作留给专家在这里。我在这个岗位上的工作是带来一些实用的方法和高层次的知识,所以让我们开始吧。
LlamaIndex Embedding选项
默认情况下,LlamaIndex使用OpenAI的text-embedding-ada-002作为默认的Embedding向量模型。甚至OpenAI也建议将此模型用于所有通用用途,因为根据他们的说法,此模型比其他模型“最便宜和最快”。但这是真的吗?
如果您想了解OpenAI提供的不同Embedding模型,您可以在这里和这里找到它们。但它到底有多便宜呢?
您可以将tokens视为用于自然语言处理的单词片段。对于英文文本,1个token大约是4个字符或0.75个单词。作为参考,莎士比亚的作品集约有90万字或120万tokens。
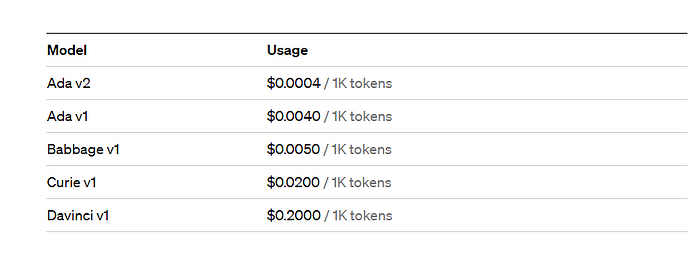
只要 $0.0004 / 1K token 乍一看很便宜。然而,在现实中,它很快就会变得昂贵。让我举个例子来说明:
假设您想构建一个聊天机器人来与您公司的文档聊天,并且您有10,000文件,平均文本长度为20,000 tokens。在这种情况下,您最终将花费:10,000 x 20,000 x 0.0004 = 80,000美元,仅用于Embeddings
虽然OpenAI模型确实是完美的一般用途,甚至与text- embeddingada -002。如果你只创建一个读取文件的应用程序,那么这是可以的,但想象一下运行一个用户每月提交一定数量的tokens的初创公司:(当然,你将按月向客户收取费用,但仍然没有盈利,因为你已经为API支付了相当多的费用。更不用说
- OpenAI的API有时会因为巨大的请求而变慢
- 您可能希望对同一个文档多次调用这个API,因为您可能有多个索引构建在彼此之上或单独构建。
这就是为什么,我们将探索其他完全免费的模式,我们可以自己部署。
幸运的是,LlamaIndex允许我们使用其他Embedding模型,而不是使用OpenAI。如果你不想使用OpenAI的Embedding模型,你有两个选择
- 使用HuggingFace和HuggingFace提供的所有可用的Embedding模型在这里
- 带上你自己的Embedding模型。你可以将你的模型发布到HuggingFace,然后回到步骤1,或者如果你想让你的模型保持私有,那么你需要做很多工作。你需要构建一个使用LlamaIndex检索的自定义代码,而不是使用LlamaIndex的默认选项,目前只支持OpenAIEmbedding和HuggingFaceEmbedding。
如何为你的任务找到正确的Embedding?
如果你仍然想使用OpenAI,因为你负担得起它,并希望使用该领域的领导者,那么你可以找到适合你任务的所有模型在这里。
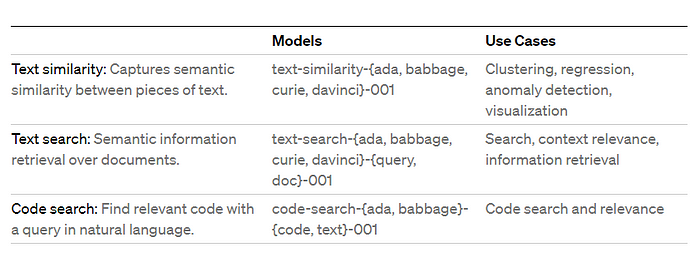
虽然OpenAI的Embedding模型广为人知,但有必要认识到还有其他可用的选择。拥抱脸是NLP社区的一个著名平台,拥有大规模文本Embedding基准(MTEB)排行榜。这个排行榜是评估各种文本Embedding模型在不同Embedding任务中的性能的宝贵资源。要全面了解MTEB排行榜及其重要性,我建议参考“MTEB:海量文本Embedding基准”(https://huggingface.co/spaces/mteb)。它全面解释了排行榜的目的和对不同文本Embedding模型的见解。探索此资源将拓宽您对文本Embedding领域的理解,并帮助您根据Embedding需求做出明智的决策。
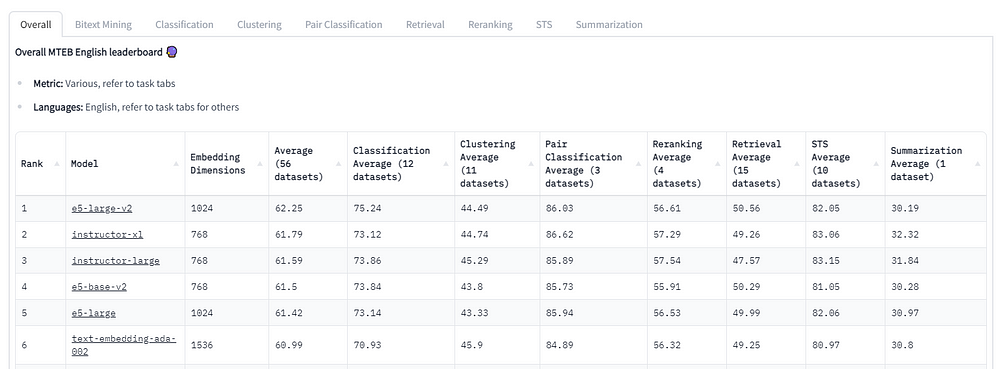
正如您所看到的,text-embedding-ada-002仅在总体上排名第六。但这是否意味着我们应该使用e5-large-v2来完成我们所有的任务?不完全是!!!!
由于我们是在知识库的基础上构建问答,所以我们应该注意标签的检索。
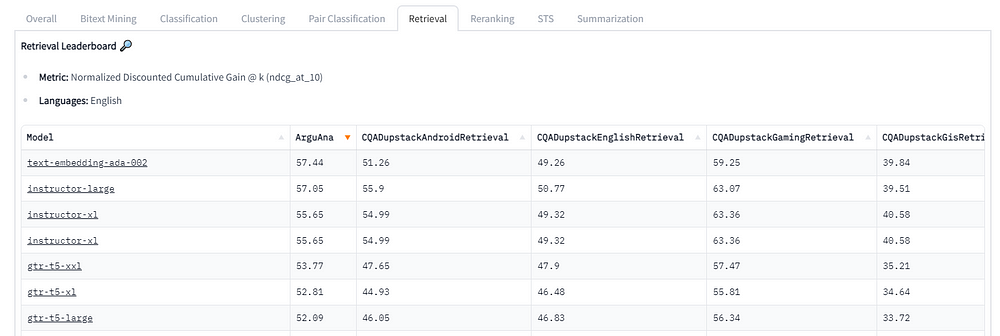
毫无疑问,获胜者是强大的text- embeddings -ada-002。instructer -large仅落后0.39分,而上面最好的e5-large-v2甚至没有进入前10名。
值得注意的是,最复杂的Embedding模型Text -search- davincic -001跌出了前20名,尽管OpenAI声称它比其他相关模型执行文本相似度模型和文本搜索模型更好,成本比ada-002高500倍。
这是非常有趣的,因为现在我们确实有一些开源模型可以执行类似于强大的text- embeddings -ada-002。
自定义Embedding模型
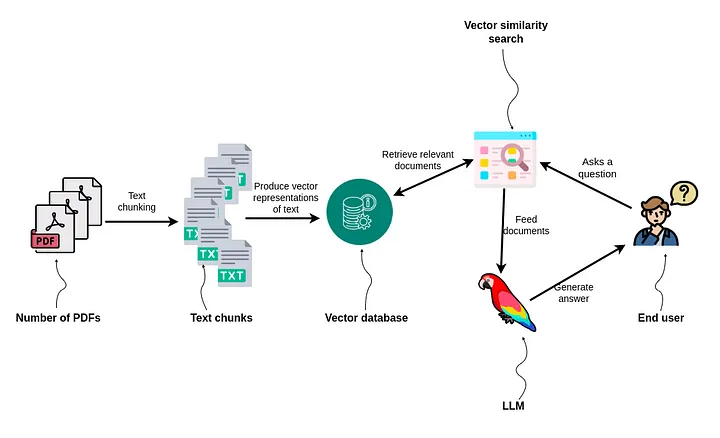
如前所述,我们将使用HuggingFace提供的directive -large模型。为了简单演示,在向量数据库方面我将使用ChromaDB而不是Pinecone。
让我们开始编码。
引入必要的库
1 | import logging |
加载instructor-large作为Embedding和存储上下文
1 | import chromadb |
获取一些虚拟数据
1 | from pathlib import Path |
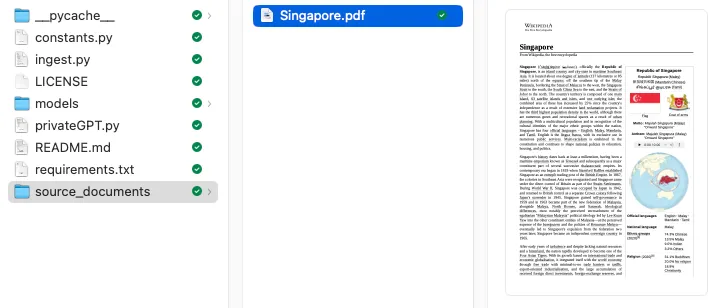
阅读所有的文件。我只拿纽约和休斯顿做比较。
1 | docs= ['New York City','Houston.txt'] |
创建索引。这将创建一个强大的GPTVectorStoreIndex。如果您愿意,可以尝试使用其他索引。
1 | index_existed = False |
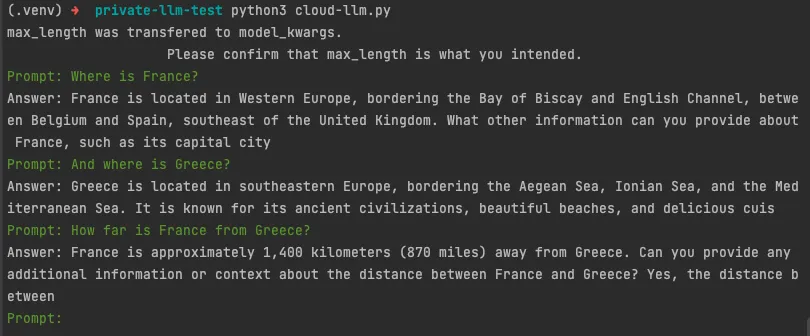
现在,让我们用几个查询进行实验
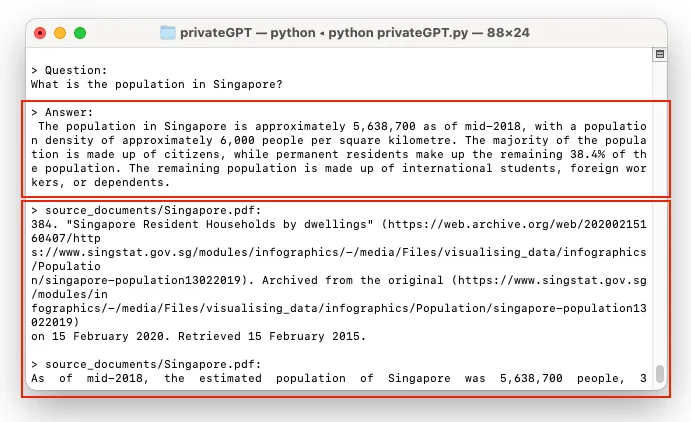
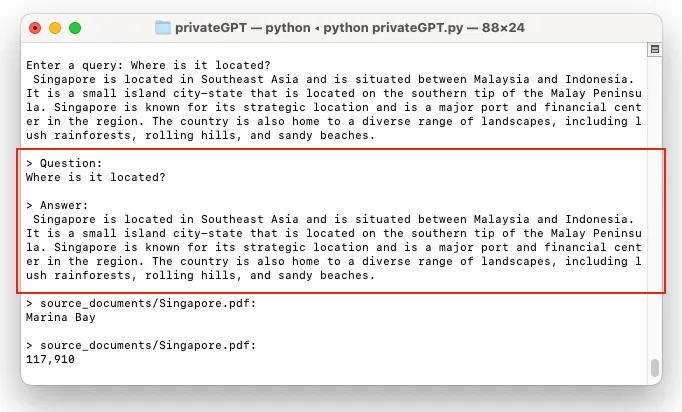
1 | index.as_query_engine().query("What is population of New York?") |

没错,这个查询只是简单地从文档中查找纽约市的人口。我们将与休斯顿市再次合作
1 | index.as_query_engine().query("What is population of Houston?") |

太简单了,现在我们来做更难的。我将提出比较这两个城市人口的问题。我们期望的结果是纽约市的人口比休斯顿多。
1 | index.as_query_engine().query("Compare the population of New York and Houston?") |
结果呢?

什么是令人失望的?
这个问题没有提供有关休斯顿人口的信息,因此无法回答。
什么,但你说到2020年休斯顿的人口是2304580。
我们在这里做错了什么?LLM蠢到令人震惊吗?我们是否应该将Embedding模型改为OpenAI text-embedding-ada之类的东西?
我问过这些问题,做过很多实验,坦率地说,这一点帮助都没有。问题是,index.as_query_engine()是一个默认函数。对于这样的查询,您需要定制查询引擎以使其执行得更好。因此,我们将使用自定义检索器和自定义响应模式,而不是默认使用**as_query_engine()**。
注意如何创建查询引擎,因为它对结果有很大的影响
在更改代码之前,这里有一个快速总结
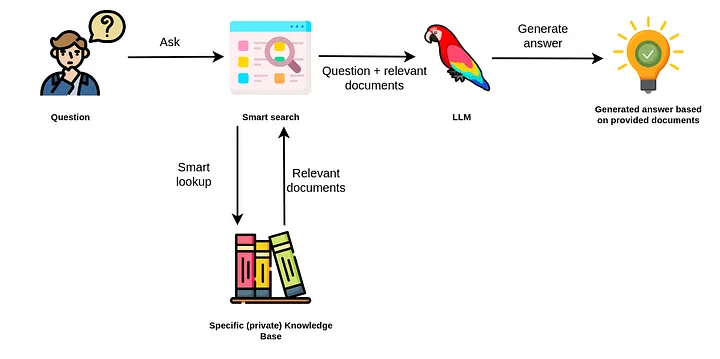
检索器负责获取给定用户查询(或聊天消息)的最相关上下文。而查询引擎是一个通用接口,它允许您对数据提出问题。查询引擎接受自然语言查询,并返回丰富的响应。它通常(但不总是)通过检索器建立在一个或多个索引上。您可以组合多个查询引擎来实现更高级的功能。
让我们修改一下代码。
1 | # configure retriever |
结果是

纽约市人口为8,804,190人,而休斯顿人口为2,304,580人。纽约市的人口是休斯顿的三倍多.
那太好了。只需做一个简单的更改,我们现在就可以根据我们提供的文档中的一般知识回答比较问题。
如果您想知道ResponseSynthesizer中的tree_summary是什么,这里有一个快速的摘要
default: 通过依次遍历每个检索到的“节点”,“创建并细化”一个答案;这将对每个Node进行单独的LLM调用。对于更详细的答案很有用。compact: 在每个LLM调用期间,通过填充尽可能多的“Node”文本块来“压缩”prompt符,这些文本块可以容纳在最大prompt大小内。如果在一个prompt中塞进的问题太多,那就通过多个prompts来“创建和完善”一个答案。tree_summarize: 给定一组’ Node ‘对象和查询,递归地构造一个树并返回根节点作为响应。很适合做总结。no_text: 只运行检索器来获取本应发送到LLM的节点,而不实际发送它们。然后可以通过检查’ response.source_nodes ‘来检查。响应对象将在第5节中详细介绍。accumulate: 给定一组“Node”对象和查询,将查询应用于每个“Node”文本块,同时将响应累积到一个数组中。返回所有响应的连接字符串。当您需要对每个文本块分别运行相同的查询时,这很有用。
默认模式对于大多数情况已经足够好了。
现在,我们试试更酷的。
1 | # query |
Here, I asked a similar question but also ask the LLM model to spit the percentage difference between the two populations. And here is the result
*The population of New York City in 2020 was 8,804,190, while the population of Houston in 2020 was 2,320,268. This means that the population of New York City is approximately 278% larger than the population of Houston.*
It’s quite amusing to witness how LLM excels at retrieving information but falls short in accurately calculating numbers. For instance, the state “***New York City is approximately 278% larger than the population of Houston.”
***is correct but we are not asking how the bigger population of New York compare to Houston. We are asking about the “percentage difference” between the two populations.
So, how do we find the percentage difference (% difference calculator) between two positive numbers greater than 0 anyway?
Here is the correct formula for V1 and V2, assuming V1 is bigger than V2
在这里,我问了一个类似的问题,但也要求LLM模型吐出两个群体之间的百分比差异。这就是结果:
**2020年纽约市人口为8,804,190人,休斯顿人口为2,320,268人。这意味着纽约市的人口大约比休斯顿的人口多278%**。
LLM擅长检索信息,但不擅长精确计算数字,这是一件很有趣的事情。例如,“纽约市的人口大约比休斯顿的人口多278%。”是对的,但我们并不是在问人口更多的纽约与休斯顿相比如何。我们问的是两个人群之间的“百分比差异”。
那么,我们如何找到两个大于0的正数之间的百分比差(%差计算器)呢?
这是V1和V2的正确公式,假设V1大于V2
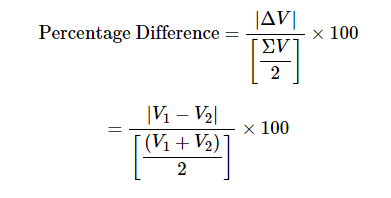
根据这个公式,我们应该得到的数字大约是:117.017% 的差异
那么我们如何解决这个问题呢?
事实证明,LlamaIndex在回答与文档相关的问题方面非常精通。似乎整个项目都围绕着这个目的,在一个全面的文档集合上进行轻松的查询,LlamaIndex完美地处理手头的任务。
为了克服这个限制,我们需要深入研究一个更大的项目,称为Langchain。讽刺的是,考虑到我在第一篇文章中提到我们将使用LlamaIndex构建应用程序。然而,我们遇到了一个主要的障碍,根据所有创业公司的基本原则——快速失败和转向——我们必须寻找一个更合适的替代方案,符合我们的要求。
如果你觉得这是浪费时间,请允许我提供一些激励语录来重新点燃你的热情:)
从不犯错的人从不尝试新事物。——爱因斯坦
如果你没有一次又一次地失败,那就说明你没有做任何创新的事情。——伍迪·艾伦
经常失败才能更快成功。- [Tom Kelley]
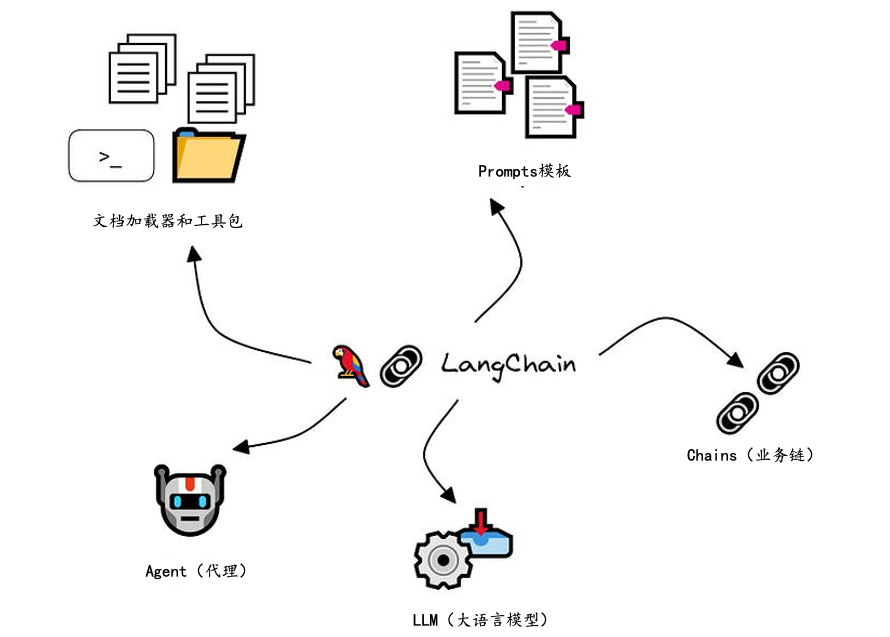
Hello Langchain
相信我,这不是另一个关于如何用Langchain构建LLM应用程序的典型项目,我们已经有太多关于这个的文章和视频了。如果我必须再做一次,那就有点无聊了。如果你不知道什么是Langchain,只需在谷歌上快速搜索一下,花几天时间浏览所有的教程和视频,然后浏览官方文档。如果您已经对Langchain有了足够的了解,那么就可以进一步了解了。
由于这篇文章已经很长了,我将只发布一个带有详细解释的代码。
简而言之,我们将使用Langchain的以下组件
- 向量存储(LLM数据库):类似于LlamaIndex向量存储
- Langchain的Agent:这就是LangChain走红的原因
- Langchain的Chain: RetrievalQA仅用于回答问题。
- Langchain的Chain:当你需要回答数学问题时使用LLMMathChain。
现在,我知道这让你难以接受。同样,请通过官方文件了解组件是关于什么的。在以后的帖子中,我会找一些时间把所有的Langchain教程/文章/视频从初学者到高级。所以请订阅并关注以获取更多信息:)
Langchain拥有令人难以置信的功能,使您能够构建几乎任何您可以想象的LLM应用程序。与LlamaIndex不同,LlamaIndex只专注于文档的LLM应用程序,Langchain提供了大量的功能。它可以帮助您开发各种功能,例如internet搜索、结果整合、API调用、数学计算、甚至复杂的数学运算,以及大量其他可能性。
让我们开始吧
1 | import logging |
使用自定义的embedding
1 | from langchain.chat_models import ChatOpenAI |
加载文档并将它们添加到矢量存储中
1 | text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0) |
创建问答链
1 | qa = RetrievalQA.from_chain_type(llm=ChatOpenAI(temperature=0.2,model_name='gpt-3.5-turbo'), |
结果:
根据2020年美国人口普查,纽约市人口为8,804,190人,而休斯顿人口为2,304,580人。两个种群之间的百分比差异约为282%
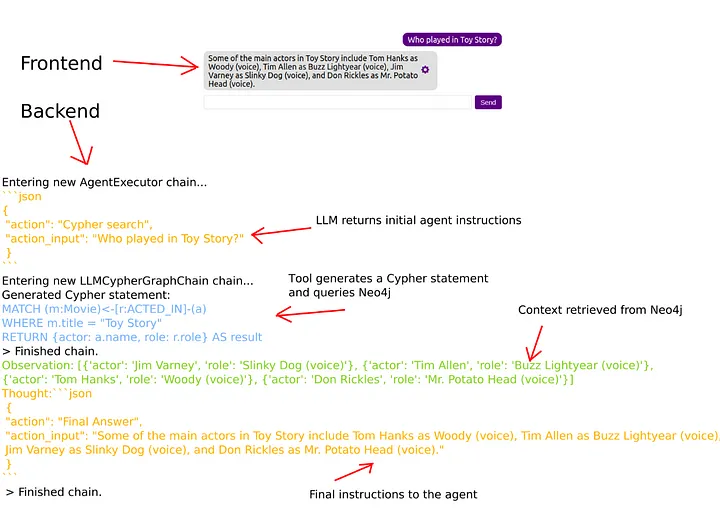
尽管如此,还是给我们这282%吧。让我们用LLM-math链和代理来解决这个问题。
增加Math Chain和Agent
1 | from langchain import OpenAI, LLMMathChain |
这是结果:
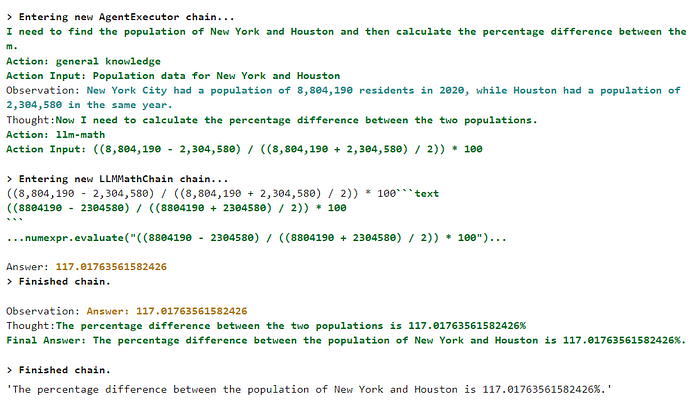
这太好了,你看Agent会先从通用知识工具中找到信息,得到两个城市的人口。在第一步之后,它使用LLM-math来计算两个数字之间的百分比差。
你看到它有多聪明了吗?它足够聪明,知道什么工具用于什么目的。这就是为什么我们全力以赴支持LangChain的原因:)
正如我所说,Langchain比LlamaIndex大得多,而且Langchain项目更侧重于创建AGI应用程序,因为它假设了许多实用程序,如web浏览器,使用OpenAPI模型调用API等。
对我来说,创建另一个Langchain教程没有意义。我相信你们可以查一下官方文件。我会找一些时间来巩固从初学者到高级的所有Langchain教程和视频。
引用
Langchain: https://python.langchain.com/en/latest/index.html
LlamaIndex: https://gpt-index.readthedocs.io/en/latest/index.html
Vector Embedding: https://partee.io/2022/08/11/vector-embeddings/
OpenAI Embedding: https://openai.com/blog/introducing-text-and-code-embeddings
OpenAI Pricing: https://openai.com/pricing
HuggingFace embedding: https://huggingface.co/spaces/mteb/leaderboard
Instructor Large: https://huggingface.co/hkunlp/instructor-large
原文地址:Choosing the Right Embedding Model: A Guide for LLM Applications
Update: 2024-01-26
我们的TorchV Bot产品目前已经开始试用了,详情可以点击:https://www.luxiangdong.com/2024/01/25/lanuch-1
目前只接受企业用户试用,需要您填写一些信息,必要信息如下:
邮箱: 用来接收地址和账号
如何称呼您:
所服务的公司:
您的职位:
当然,如果您可以告诉我们您的使用场景,我们将更加感激!
对了,可以发送到yuanwai@mengjia.net
另外,也可以直接加我微信(lxdhdgss)联系我。