0629讲稿
以下是我在2024年6月29日上午在北京富力万丽酒店举行的稀土掘金开发者大会RAG专场的分享内容,包括文字稿,一并分享给大家!

朋友们,上午好!
我叫卢向东,来自杭州,今天为大家分享的是我们在大模型应用的企业落地时碰到的一些关于RAG的难点和创新。

可能很多朋友认识我是因为公众号“土猛的员外”,从去年6、7月份开始持续分享了关于RAG和大模型的一些文章和观点。现正在和几个伙伴一起创业,担任杭州萌嘉网络科技(也就是TorchV)的CEO。
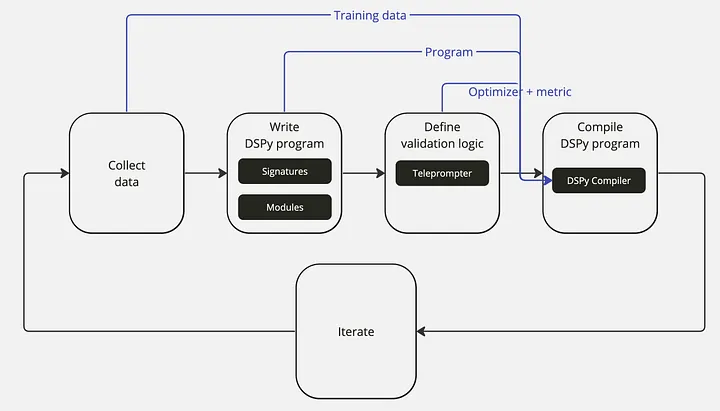
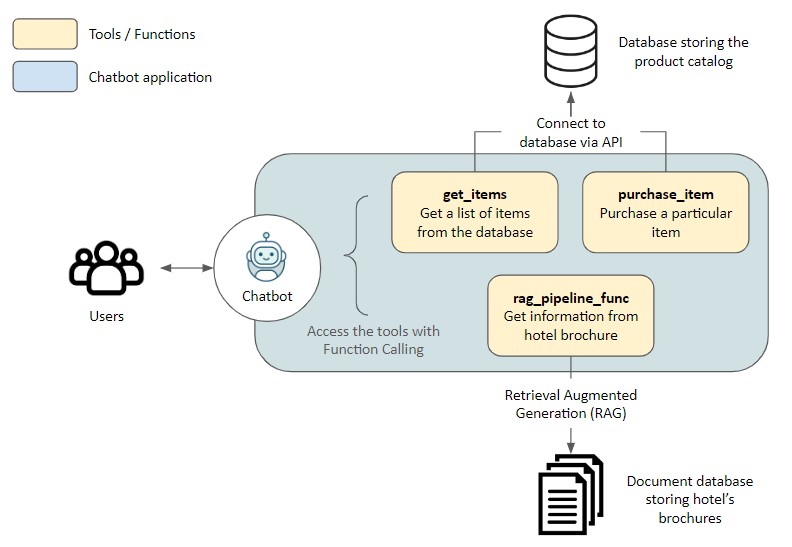
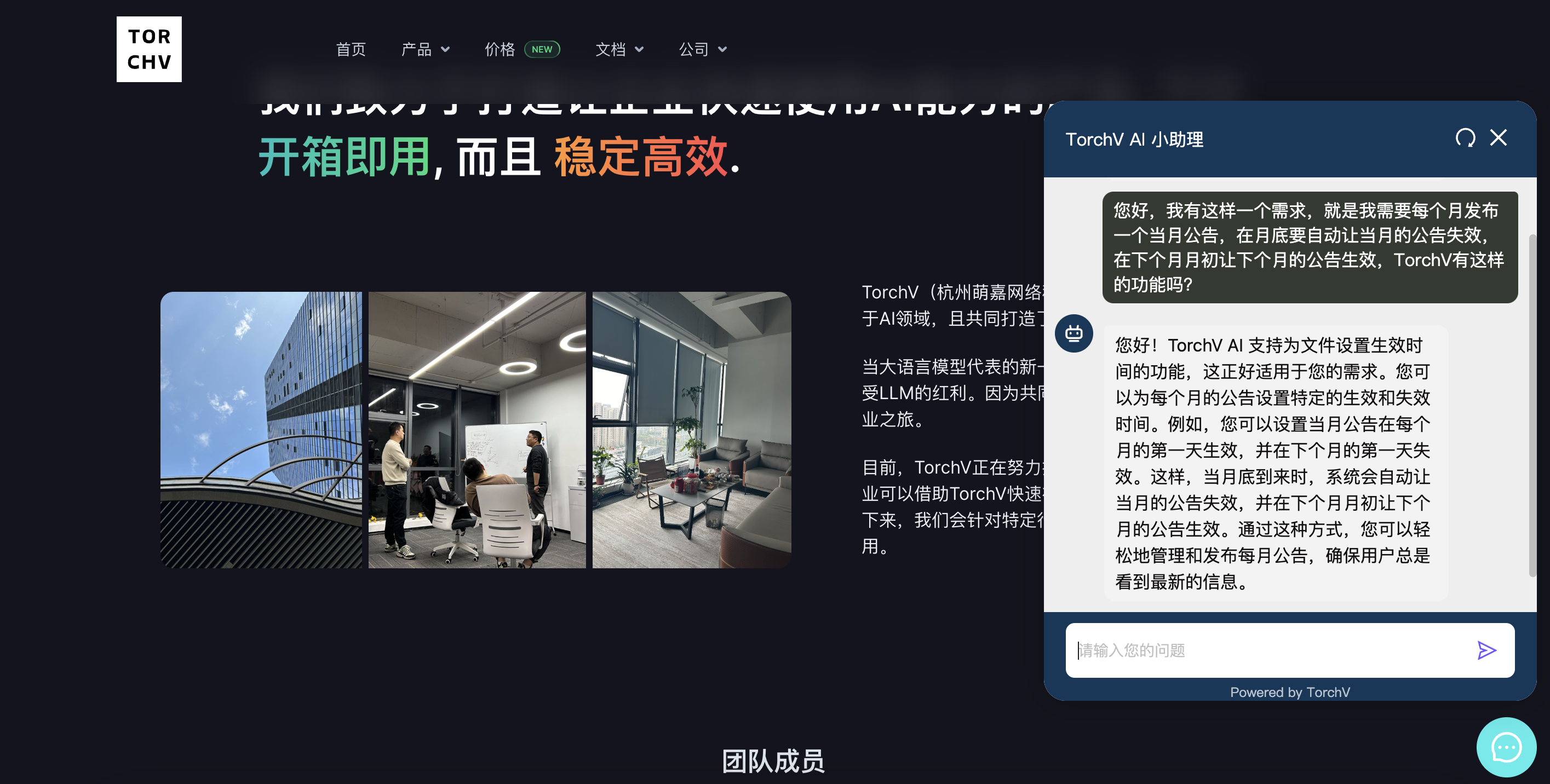
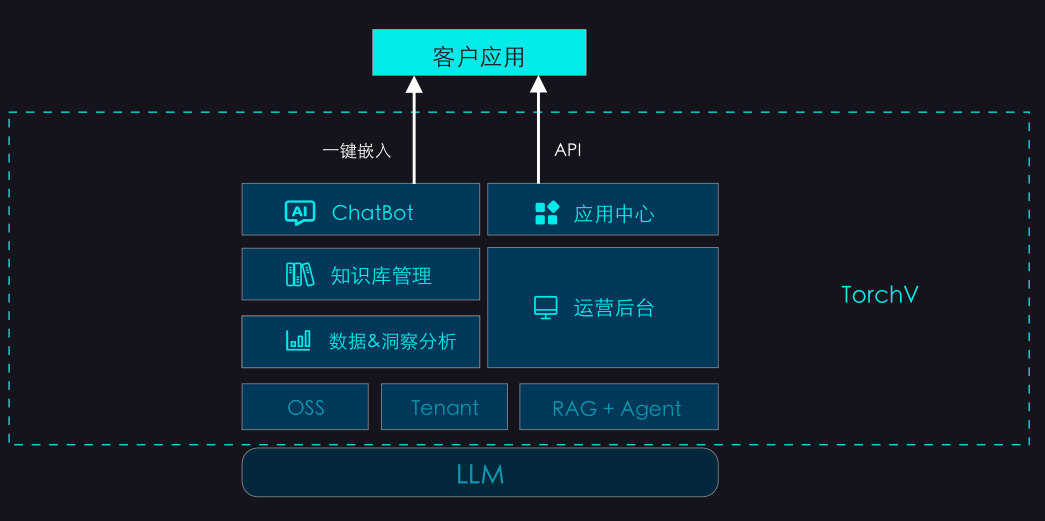
今天在这里想和大家分享的主要内容,是关于我们在大模型应用的企业落地场景中遇到的一些问题,以及一些落地的产品案例。我一共会分享四个难点,三个应用案例,然后把一些个人对这一领域的思考放在最后面。希望能从不同视角给大家带来一些大模型应用在企业落地实践中的内容。
OK,那现在我们就进入第一Part,来讲讲我们在实践中遇到的问题。